
自然語言推理-文字蘊含識別簡介
from: https://blog.csdn.net/u010960155/article/details/81335067
一 什麼是文字蘊含識別
文字間的推理關係,又稱為文字蘊含關係 (TextualEntailment),作為一種基本的文字間語義聯絡,廣泛存在於自然語言文字中。簡單的來說文字蘊含關係描述的是兩個文字之間的推理關係,其中一個文字作為前提(premise),另一個文字作為假設(hypothesis),如果根據前提P能夠推理得出假設H,那麼就說P蘊含H,記做。這跟一階邏輯中的蘊含關係是類似的。
例子:

這個例子中前提P是“A dog jumping for a Frisbee in the snow”,意思一隻狗在雪地中接飛盤玩,同時下面給出了三個假設,這三個假設中前提跟第一個是蘊含關係(entailment),因為這句話描述的是“一個動物正在寒冷室外玩塑料玩具”,這是能夠從前提推理出來的;第二句化描述的是“一隻貓...”,這跟前提是衝突的(contradiction);第三句話與前提既不是蘊含關係也沒有衝突,我們把它定義成中立的(neutral)。
文字蘊含識別(Recognizing Textual Entailment,RTE)主要目標是對前提和假設進行判斷,判斷其是否具有蘊含關係。文字蘊含識別形式上是一個文字分類的問題,在上面這個例子中是一個三分類的問題,label分別為entailment,contradiction,neutral。
二 文字蘊含識別資料集
2.1 SNLI
SNLI資料主頁
The Stanford Natural Language Inference (SNLI) 是斯坦福大學NLP組釋出的文字蘊含識別的資料集。SNLI由人工標註的,一共包含570K個文字對,其中訓練集550K,驗證集10K,測試集10K,一共包含三類entailment,contradiction,neutra,上節提到的例子就是出自此資料集,下圖為此資料集例子:
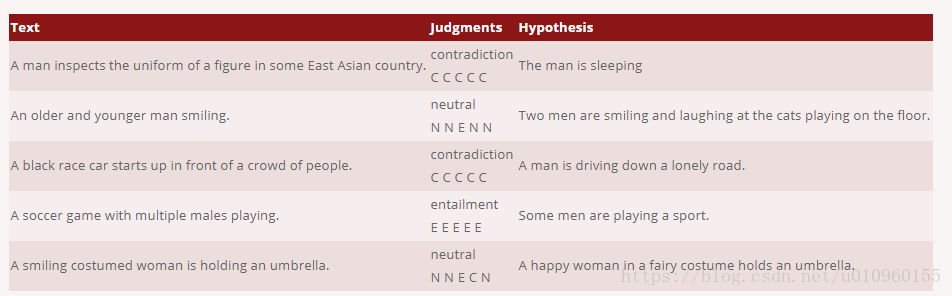
2.2 MultiNLI
MultiNLI主頁
The Multi-Genre Natural Language Inference (MultiNLI)是一個眾包資料集,包含433k個文字對。與SNLI資料集類似,每條資料包含兩個文字,第一條文字來從已經存在的語料中獲取,例如 Open American National Corpus (OpenANC) 。第二條文字是有人編寫的,下面為該資料集的例子:
2.3 其他資料集
Past campaigns data sets
RTE1 dataset - provided by PASCAL
RTE2 dataset - provided by PASCAL
RTE3 dataset - provided by PASCAL
RTE4 dataset - provided by NIST - freely available upon request. For details see TAC User Agreements
RTE5 dataset - provided by NIST - freely available upon request. For details see TAC User Agreements
RTE6 dataset - provided by NIST - freely available upon request. For details see TAC User Agreements
RTE7 dataset - provided by NIST - freely available upon request. For details see TAC User Agreements
The Joint Student Response Analysis and 8th Recognizing Textual Entailment Challenge at SemEval 2013
The MultiGenre NLI Corpus (433k examples, used in the RepEval 2017 Shared Task)
RTE data sets translated in other languages
RTE3 dataset translated in German - provided by EXCITEMENT
RTE3 dataset translated in Italian - provided by EXCITEMENT
Other data sets
The Stanford Natural Language Inference (SNLI) corpus, a 570k example manually-annotated TE dataset with accompanying leaderboard.
FrameNet manually annotated RTE 2006 Test Set. Provided by SALSA project, Saarland University.
Manually Word Aligned RTE 2006 Data Sets. Provided by the Natural Language Processing Group, Microsoft Research.
RTE data sets annotated for a 3-way decision: entails, contradicts, unknown. Provided by Stanford NLP Group.
BPI RTE data set - 250 pairs, focusing on world knowledge. Provided jointly by Boeing, Princeton, and ISI.
Textual Entailment Specialized Data Sets - 90 RTE-5 Test Set pairs annotated with linguistic phenomena + 203 monothematic pairs (i.e. pairs where only one linguistic phenomenon is relevant to the entailment relation) created from the 90 annotated pairs. Provided jointly by FBK-Irst, and CELCT.
RTE-5 Search Pilot Data Set annotated with anaphora and coreference information - RTE-5 Search Data Set annotated with anaphora/coreference information + Augmented RTE-5 Search Data Set, where all the referring expressions which need to be resolved in the entailing sentences are substituted by explicit expressions on the basis of the anaphora/coreference annotation. Provided by CELCT and distributed by NIST at the Past TAC Data web page (2009 Search Pilot, annotated test/dev data).
RTE-3-Expanded, RTE-4-Expanded, RTE-5-Expanded. RTE data set expanded in the two and three way task, at least 2000 pairs in each data set.
Explanation-Based Analysis annotation of RTE 5 Main Task subset described in this ACL 2010 paper
Wiki Entailment Corpus A RTE-like set of entailment pairs extracted from Wikipedia revisions described in this paper
The Guardian Headlines Entailment Training Dataset An automatically generated dataset of 32,000 pairs similar to the RTE-1 dataset.
Answer Validation Exercise at CLEF 2006 (AVE 2006)
The Textual Entailment Task for Italian at EVALITA 2009 An evaluation exercise on TE for Italian.
Cross-Lingual Textual Entailment for Content Synchronization The Cross-Lingual Textual Entailment task at SemEval 2012.
Cross-Lingual Textual Entailment for Content Synchronization The Cross-Lingual Textual Entailment task at SemEval 2013.
ASSIN a shared task on TE for Portuguese with 10,000 pairs.
三、文字蘊含識別演算法
3.1 基於相似度的方法
構成蘊含關係的兩個文字往往比較相似,可以通過計算前提和假設之間的相似度來判斷其之間是否構成蘊含關係。這類方法比較直觀,在RTE研究領域一度是比較流行的方法,但隨著研究的深入,現在更多把相似度作為判別模型中的一個特徵。
Jijkoun在論文Recognizing Textual Entailment Using Lexical Similarity中提出了基於詞袋模型的文字蘊含識別方法,他的做法時首先對文字進行分詞,然後通過詞頻對單詞進行賦權,然後計算Lin-相似度和WordNet相似度,並以此為根據計算相似度。這種方法最終在PASCAL-2005的RTE資料集上accuracy為0.55。
Adams在論文http://u.cs.biu.ac.il/~nlp/RTE2/Proceedings/21.pdf中在Jijkoun詞袋模型基礎對相似度進行了改造,該方法利用WordNet抽出來的詞鏈來連結前提和假設,並計算兩者的編輯距離,最終結合其他特徵使用決策樹識別蘊含關係。這種方法最終在PASCAL-2005的RTE資料集上accuracy為0.657。
這種基於相似度的方法簡單易實現,但這種方法強行假設“相似及蘊含”是有明顯缺陷的,這會導致有大量的文字蘊含關係識別錯誤。
3.2 基於文字對齊的方法
在基於相似度識別方法的基礎上演化出了基於文字對齊的方法,這類方法不直接使用相似度判別蘊含關係,這類方法先把前提和假設相似的部分進行對齊,通過對齊的方式和程度作為最後判別是否為蘊含關係的依據。這種方式優點就是能夠更好體現兩個文字之間的相似度。
Marneffe在論文Finding Contradictions in Text中首先把前提和假設中的詞進行對齊,對齊後再加工特徵使用邏輯迴歸進行蘊含分析,這篇論文主要做的是衝突檢測,跟前面的蘊含關係識別稍有區別。
基於對齊的方法在相似度的基礎刪上引入了對齊操作,這樣使我們能更加關注前提和假設不相同的部分。對齊方法缺點在於需要引入先驗知識進行對齊,並且存在一些一對多、多對多的對齊情況難以操作。
3.3 基於邏輯演算
蘊含關係實際上是一種語義推理關係,而數學屆對命題邏輯問題已經有了比較成熟的方法和工具,因此將邏輯演算運用到文字蘊含是非常自然的想法。基於邏輯演算的方法一般是將文字表示成數學邏輯表示式,比如一階邏輯,構成事實集合,然後用邏輯推理規則判斷是否能根據前提推理出假設。
Raina在論文Robust textual inference via learning and abductive reasoning中利用依存關係將前提和假設分別表示成兩組子命題的和取形式,然後通過溯因推理機制嘗試從前提推理出假設並計算其代價,並因此判別前提和假設是否有蘊含關係
基於邏輯演算的方法把數學界機器證明領域成熟的思想遷移到文字蘊含識別領域,具有一定的理論基礎,但文字到邏輯表示式的轉換不夠魯棒,容錯性較差。而背景知識缺失往往導致推理鏈條的中斷,導致結果召回率偏低。
3.4 基於文字轉換
由於基於邏輯演算方法的不足,有的學者提出了基於文字轉換的思路。這類方法採用了類似的“演算”思想,卻拋棄了嚴格的數學邏輯表示式,轉而利用語言分析技術,例如句法分析,語義角色標註,把前提和假設都表示成某種語言表示形式,如句法樹、依存圖等。然後利用背景知識設計推理規則將前提和假設進行改寫,將其轉換成對方的類似的形式,然後再通過子圖相似性判別出其蘊含關係。
Bar-Haim在論文Semantic Inference at the Lexical-Syntactic Level的主要方法為把前提和假設都改寫成句法樹,然後依照規則對前提進行改寫,如果前提能夠改寫成假設的句法樹形式則認為存在蘊含關係。
基於轉換的方法保留了基於邏輯演算的核心,同時不再要求把前提和假設表示成邏輯表示式,避免了引入噪音,但是該方法嚴重依賴轉換規則。這些轉換規則有的來自於知識庫有的來自於語料。
3.5 基於混合模型
針對前面所介紹的各類文字蘊含識別方法的優勢與不足,有學者提出了基於混合模型的方法.該類方法把諸如前提和假設的詞級別相似度(如單詞重疊率、同義詞、反義詞等)、句法樹相似度、句法樹編輯距離、對齊程度、由T轉換為H的代價等等混合在一起作為特徵,送入分類器(如支援向量機等)進行分類的方法。
3.6 基於深度學習的模型
1) 基於CNN模型。
Yin在論文中ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs提出了基於Attention機制的卷積神經網路來處理RTE問題,由於蘊含關係需要考慮一對文字前提和假設的資訊,可以在對其中一個文字(比如假設)建模是同時考慮前提的資訊,這種參照機制就是Attention機制。該方法通過在卷積中加入Attention Matrix來實現此目的。
此外,普通的卷積神經網路不能夠有效捕獲句法資訊,而這些資訊是判別文字蘊含所需要的重要特徵。因此Mou在論文Natural Language Inference by Tree-Based Convolution and Heuristic Matching中提出了基於樹結構的卷積神經網路,該網路將句法依存樹作為卷積的操作物件,構成子樹特徵提取器,它能夠一次性提取父節點及其子節點間的依存關係,該方法使用兩個TBCNN分別對前提和假設進行建模,使用拼接、求差、相乘等啟發式特徵構造向量代表前提和假設的對的語義資訊,最後再使用softmax進行分類。該方法在SNLI資料集上準確率達到0.824.
2) 基於RNN方法
Rocktäschel 在論文 Reasoning about Entailment with Neural Attention提出了使用LSTM進行RTE的方法,主要思想為分別使用兩個LSTM對前提和假設進行建模,並使用前提的LSTM的狀態來初始化假設LSTM。在建模的過程中引入了Attention機制,即在處理假設時考慮前提的資訊。Rocktäschel等人還提出了word by word Attention機制,即在LSTM處理假設文字中的每個詞時,都引入前提經過LSTM建模後的資訊,這樣進一步提升了模型的效能。最後實驗通過分析Attention矩陣,發現該機制能很好的發現前提和假設中詞之間的關聯關係,並且實現了軟對齊,較之前的RTE方法有了很大進步,在SNLI資料集上的準確率為0.832。
Wang等人在Rocktäschel基礎上在論文Learning Natural Language Inference with LSTM提出了match-LSTM模型,重點關注前提和假設之間各個部分的匹配情況。Wang等人認為Rocktäschel的方法有倆個侷限性。第一個是這個模型僅使用了前提的單一向量來跟假設之間做匹配。第二個是這個模型沒有對前提和假設之間匹配的部分增加權重,對衝突的部分降低權重。也就是沒有很好區分這兩種情況。針對這兩點Wang對模型進行了改進,他們把對前提和假設進行LSTM建模時的Attention向量進行拼接輸入到match-LSTM。此外該方法還在前提中引入特殊單詞NULL,當假設中的單詞與前提中的單詞不構成任何匹配時,match-LSTM就會把這個詞跟NULL進行匹配,相當於增加了懸空對齊方式,完善了對齊模型。
Wang在實驗中同樣對Attention矩陣進行了分析,除此之外還對LSTM中的遺忘門、輸入們、輸出門分別作了實驗分析。該方法在SNLI資料集上的準確率為0.861。
Reference
https://repeval2017.github.io/shared/
https://aclweb.org/aclwiki/Textual_Entailment_Resource_Pool
郭茂盛, 張宇, 劉挺. 文字蘊含關係識別與知識獲取研究進展及展望[J]. 計算機學報, 2017, 40(4):889-910.
---------------------
作者:龐加萊
來源:CSDN
原文:https://blog.csdn.net/u010960155/article/details/81335067
版權宣告:本文為博主原創文章,轉載請附上博文連結!