
《CS224n斯坦福課程》-----第三課
學習筆記:cs224n3
學習視訊:cs224n3
學習課件:cs224n3
上課的好處,就在於每節課老師都會解決幾個問題,跟著老師的思路走,然後就可以清晰知道這節課學習了什麼。
1,還是繼續聊聊word2vec
對於word2vec而言,要遍歷整個語料庫的每個詞,然後預測詞的上下文的情況,根據損失函式的隨機梯度下降,來求解二個詞向量的情況。要更新的引數高達|V|*2*m。尤其對於傳統的word2vec而言,在softmax的時候,存在很大的問題,因為資料量太大了,進行softmax的時候有很多的問題。
為了解決這個問題,所以,出現了二種Word2vec的實現,分層softmax和負取樣,然後根據到底是知道中心詞求上下文,還是知道上下文來求中心詞,有CBOW,Skip-gram的實現方式。
其中分層softmax涉及到了哈夫曼樹,負取樣是更為簡單的一種實現。
貼出原理貼:http://www.hankcs.com/nlp/word2vec.html#h3-12
對於skip-gram的實現,損失函式如下:
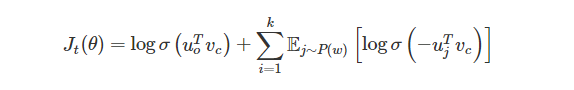
損失函式,用大白話來解釋就是,使得出現在上下文的詞向量的相似度儘可能高,對於不出現在上下文視窗的詞,相似度儘可能的低。此時是通過視窗來作為訓練單位,一個視窗或者幾個視窗更新一下引數。
2,其他的詞向量的處理辦法
早在word2vec之前,就出現了很多的詞向量的度量方法,這些方法基本都是基於統計共現矩陣。現在來一一解開面紗。
1)基於視窗的共現矩陣。
比如字典有N個詞,那麼會有一個N*N的一個記錄表,來記錄詞的共現情況。每個元素表示二個詞在語料庫中共現的次數。
在這種詞向量的度量中,首先很大,維度很大,與詞表大小有關,其次,很難進行再次學習,也就是有新詞來的時候,整個矩陣都需要改變,並且這種詞向量的度量方式可能比one-hot好點,但稀疏性也是很高的。
2)SVD
在1)的基礎上,我們為了降低維度,所以用了奇異值分解的手段,也就是將N維的向量,降低到k維,K可以是一個固定的低維的向量。還有一些可以改進的點,比如,去除停止詞,也就是限制高頻詞的頻次,詞頻可以用皮爾遜相關係數來進行代替,還可以根據與中心詞的距離來衰減詞頻的權重,而不是統一的給一個度量,視窗不同的位置給予不同的權重。
在SVD中,計算複雜度還是很高的,不方便來訓練新詞,與深度學習的訓練框架有很大的區分,移植性不強。
3,Glove的出現
對於基於統計共現矩陣的方法而言,有效的利用了共現的統計資訊,但沒有考慮到詞語的相似度,語境的相似度問題,而且對於大規模的語料的應用也是很不妥的,計算複雜度很高。對於基於神經網路的詞向量的方法而言,有視窗的存在,可以捕捉到區域性的統計資訊,利用到了上下文,也就是語境的資訊,但無法利用到單詞的全域性統計資訊。
所以,為了綜合二大類方法,GlOVE出現了。對於第一種方法,可以說序列的詞向量抽取,第二種方法,可以說是並行的詞向量抽取的方法。用個專業的名詞來解釋,syntagmatic models/paradigmatic models 詳細看這篇文章。https://www.cnblogs.com/Determined22/p/5780305.html
對於Glove的損失函式:
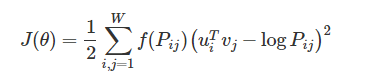
其中,u,v向量等價,最後的向量為二個的求和平均(當然這個平均可以說有也可以說無,畢竟就是一個常數項,放在那裡都行)。P為共現矩陣,然後f函式是一個調節的引數。
對於GLove而言,有點在於可以擴充套件到大語料庫,當然,其也適用於小規模的語料庫和小向量。
4,對於詞向量模型的評價
分為了內部(intrinsic),外部(extrinsic)二種評測的辦法。
對於內部的評測方法,可以專門的測驗,就是通過與人標註的結果來進行比對,好處是計算塊,但壞處是不知道這種提升在實際中是不是有那麼大的用處。
對於外部評測,需要在實際的系統應用中進行調節,這種調節起來就很慢了,而且解耦合做的不好,你根本不知道什麼起到了作用,你不知道什麼沒有起到作用。
具體的來說,對於內部的評測方法,一般可以通過視覺化的方法,通過詞語之間的某些聯絡來進行測試,判斷是否具有平行的關係來進行表述。對於外部評測來說,肯定就是通過外在應用的評價的好壞來進行判斷了。
5,對於詞向量的調參
1)視窗是否對稱,是否只考慮到了單邊的效果。
2)向量維度的大小設定是否合理。
3)視窗的大小設定是否合理。