
Shazam It! Music Recognition Algorithms, Fingerprinting, and Processing
轉載自:https://blog.csdn.net/yutianzuijin/article/details/45418035
最近看到一篇老外寫的部落格,簡單介紹了shazam的工作原理。圖非常好,所以就把它翻譯成中文,希望對搞聽歌識曲的人有幫助。
你可能遇到這樣的場景:在酒吧或者餐廳聽到你非常熟悉的歌,也許你曾經聽過無數次,並且被歌曲憂傷的旋律深深打動。久違之後的邂逅讓你依然心動,所以想再次欣賞這首歌,但是卻突然不記得名字了!明明就在嘴邊,但就是說不出來!這時如果你手機上裝有音樂識別軟體,那麼問題就很容易解決了。你只需要開啟軟體錄一段音樂就好了,然後識別軟體就會告訴你歌名,之後你就可以無限暢聽直到厭煩為止。
移動技術和音訊訊號處理技術的發展,使演算法工程師有能力設計出音訊識別軟體。最出名的音訊識別app之一是Shazam。如果你有某首歌的一個20s片段,交給shazam之後,shazam會首先提取指紋,然後查詢資料庫,最後利用其精準的識別演算法返回歌名。
shazam是如何工作的呢?其演算法核心由Avery Li-Chung Wang發表於03年。在本文中會回顧一下shazam演算法的基礎和流程。
1. 模擬到數字—訊號取樣
聲音究竟為何物?難道是一種看不見摸不著但是卻可以進入我們耳朵的神祕物質?
這當然是holy shit了。從本質上來說,聲音是機械波在介質(空氣或者水)中的振動。當振動傳到我們耳朵特別是鼓膜時,就會進一步通過微小的軟骨傳到內耳的毛細胞。毛細胞會產生電磁脈衝將訊號最終傳遞到大腦的聽覺神經。
錄音裝置通過模仿人耳的工作原理將聲波轉換成電子訊號。空氣中的聲音是連續的波形訊號,麥克風會將其轉化成模擬的連續電壓訊號。但是該連續的模擬訊號在數字世界中用處不大,需要轉換成離散的訊號,便於儲存。我們往往通過捕獲特定時刻訊號的幅值來將訊號數字化。轉換需要對輸入的模擬訊號進行量化,這不可避免地會引入少量錯誤。所以,為了避免單次轉換帶來的誤差,我們會利用一個模數轉換器對一段很小的訊號進行多次轉換—這個過程也即常說的取樣。
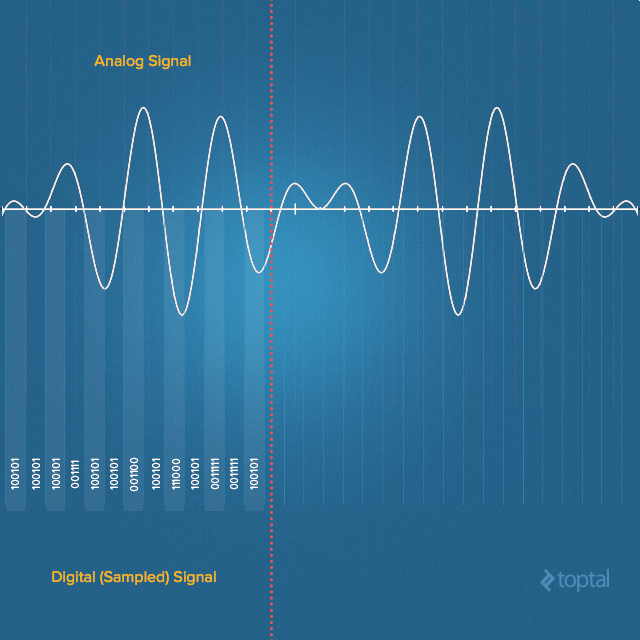
奈奎斯特-夏農取樣定理告訴我們,為了能捕獲人類能聽到的聲音訊率,我們的取樣速率必須是人類聽覺範圍的兩倍。人類能聽到的聲音訊率範圍大約在20Hz到20000Hz之間,所以在錄製音訊的時候取樣率大多是44100Hz。這是大多數標準MPEG-1 的取樣率。44100這個值最初來源於索尼,因為它可以允許音訊在修改過的視訊裝置上以25幀(PAL)或者30幀( NTSC)每秒進行錄製,而且也覆蓋了專業錄音裝置的20000Hz頻寬。所以當你在選擇錄音的頻率時,選擇44100Hz就好了。
1. 錄音—聲音捕獲
錄音不是什麼難事。目前的音效卡都有一個模數轉換器,所以我們需要做的就是選擇自己擅長的程式語言和一個合適的處理庫,然後設定取樣率、聲道數和取樣位數就可以開始錄音了。如果用java來實現,程式碼可能會像下面這樣:
-
private AudioFormat getFormat() {
-
float sampleRate =
44100;
-
int sampleSizeInBits =
16;
-
int channels =
1;
//mono
-
boolean signed =
true;
//Indicates whether the data is signed or unsigned
-
boolean bigEndian =
true;
//Indicates whether the audio data is stored in big-endian or little-endian order
-
return
new AudioFormat(sampleRate, sampleSizeInBits, channels, signed, bigEndian);
-
}
-
-
final AudioFormat format = getFormat();
//Fill AudioFormat with the settings
-
DataLine.Info info =
new DataLine.Info(TargetDataLine.class, format);
-
final TargetDataLine line = (TargetDataLine) AudioSystem.getLine(info);
-
line.open(format);
-
line.start();
-
OutputStream out =
new ByteArrayOutputStream();
-
running =
true;
-
-
try {
-
while (running) {
-
int count = line.read(buffer,
0, buffer.length);
-
if (count >
0) {
-
out.write(buffer,
0, count);
-
}
-
}
-
out.close();
-
}
catch (IOException e) {
-
System.err.println(
"I/O problems: " + e);
-
System.exit(-
1);
-
}
3. 時域和頻域
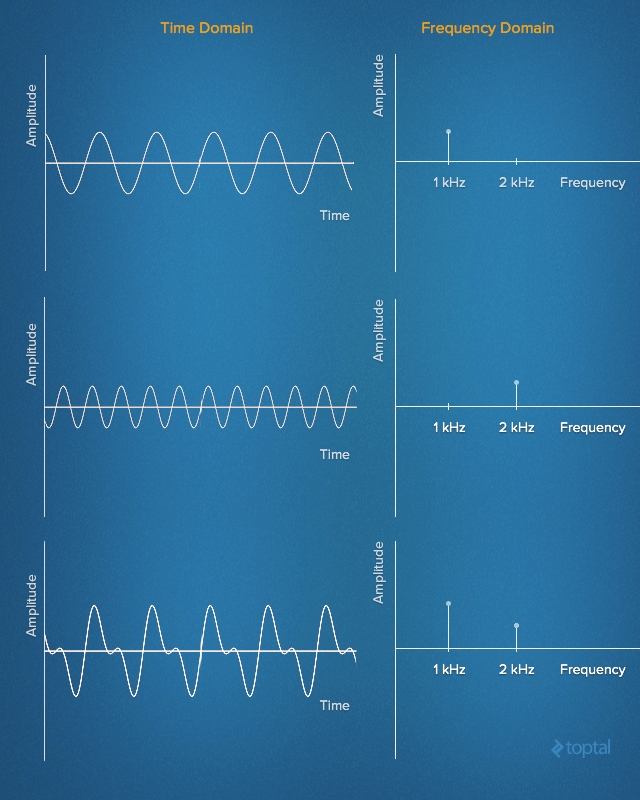
上述位元組陣列中儲存的是時域訊號,時域訊號表示訊號幅值隨時間的變化(不過時域訊號包含的有用資訊比較少)。早在十八世紀初,傅立葉就有了一個驚人發現:任何時域上的訊號都可以等價為多個(也可能是無窮多個)簡單正弦訊號的疊加,每個正弦訊號都有不同的頻率、幅值和相位。這一系列的正弦函式集合被稱為傅立葉級數。
換句話說,我們可以用給定頻率、幅值和相位的多個正弦訊號構成任意的時域訊號。將訊號用一系列簡單正弦訊號表示的方法稱為訊號的頻域表示。從某種角度來說,頻域表示可以看做時域訊號的指紋或者簽名,它給我們提供了一種用靜態資料表示動態訊號的方法。
下面的動畫展示了1Hz square波是如何由多個正弦波疊加構成的。上圖展示了時域訊號,下圖展示了正弦波的頻域表示。
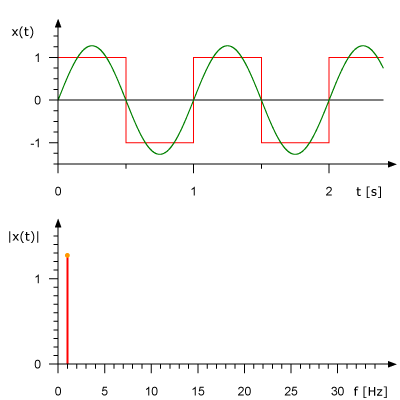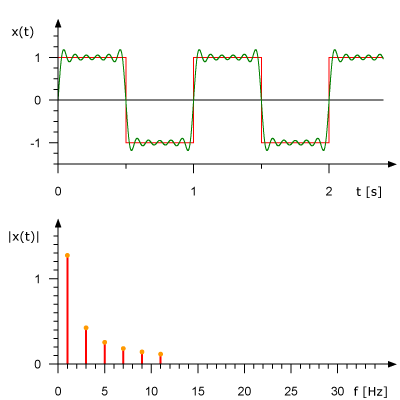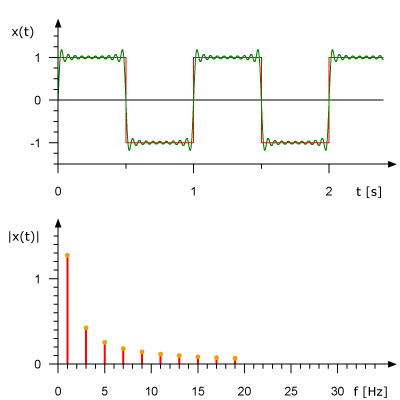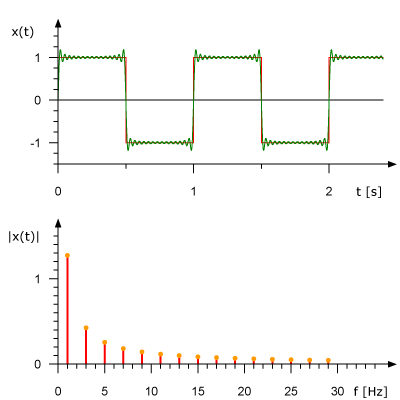
來自於:René Schwarz
從頻域角度分析訊號可以極大地簡化問題。在數字訊號處理的世界中,頻域訊號分析更為方便,我們可以通過分析頻域來判斷某個頻率的正弦訊號是否存在。在這之後,還可以對訊號進行某些頻率的過濾,幅值調節,或者基頻識別等等。
4. 離散傅立葉變換
為了將訊號由時域變換到頻域,我們需要一個變換工具,這個工具叫做離散傅立葉變換(DFT)。DFT是一種對離散訊號進行傅立葉變換的數學工具,它將等間隔取樣的訊號轉換成具有等間隔頻率的正弦訊號幅值(幅值是用複數表示的)。
計算DFT的方法是FFT,目前最常用的FFT實現是 Cooley–Tukey algorithm。該演算法通過分治策略解決DFT問題。直接解決DFT需要O(n2)的複雜度,但是Cooley-Tukey演算法採用分治策略後DFT問題的複雜度降到O(n logn)。目前有很多FFT的庫,下面列舉了一些:
- C – FFTW
- C++ – EigenFFT
- Java – JTransform
- Python – NumPy
- Ruby – Ruby-FFTW3 (Interface to FFTW)
下面的程式碼展示瞭如何利用java進行FFT(FFT的輸入是複數,理解複數和三角函式的關係需要了解
-
public
static Complex[] fft(Complex[] x) {
-
int N = x.length;
-
-
// fft of even terms
-
Complex[] even =
new Complex[N /
2];
-
for (
int k =
0; k < N /
2; k++) {
-
even[k] = x[
2 * k];
-
}
-
Complex[] q = fft(even);
-
-
// fft of odd terms
-
Complex[] odd = even;
// reuse the array
-
for (
int k =
0; k < N /
2; k++) {
-
odd[k] = x[
2 * k +
1];
-
}
-
Complex[] r = fft(odd);
-
-
// combine
-
Complex[] y =
new Complex[N];
-
for (
int k =
0; k < N /
2; k++) {
-
double kth = -
2 * k * Math.PI / N;
-
Complex wk =
new Complex(Math.cos(kth), Math.sin(kth));
-
y[k] = q[k].plus(wk.times(r[k]));
-
y[k + N /
2] = q[k].minus(wk.times(r[k]));
-
}
-
return y;
-
}
下圖展示了訊號進行FFT前後的變化:
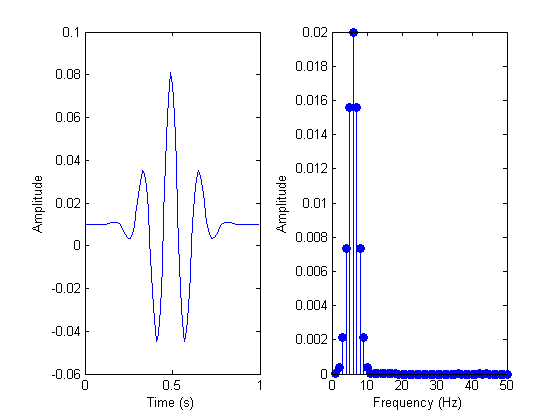
5. 提取音訊指紋
FFT的一個很大缺陷是我們丟失了原始訊號的時間資訊(雖然理論上我們可以獲得時間資訊,但是代價非常大)。例如,對一個3分鐘長的音樂來說,我們傅立葉變換之後看到的只是一系列頻率和頻率的幅值,而無法知道這些頻率在音樂的什麼位置出現。但是這些位置資訊非常重要,因為正是這些頻率位置決定了這首歌!
所以我們需要引入另一項技術:滑動視窗。滑動視窗只對一塊原始訊號進行傅立葉變換。資料塊的大小可以通過多種方式確定。例如,我們錄製了一段音樂,雙聲道,16-bit精度,44100Hz取樣。這時1s的資料大小為44100*2byte*2聲道≈176kB。如果選擇4kB當作資料塊大小,則每秒鐘我們需要對44塊資料進行傅立葉變換。這樣的切分密度足以應對大多數需求。
下面對分塊的資料進行傅立葉變換:
-
byte audio [] = out.toByteArray()
-
int totalSize = audio.length
-
int sampledChunkSize = totalSize/chunkSize;
-
Complex[][] result = ComplexMatrix[sampledChunkSize][];
-
-
for(
int j =
0;i < sampledChunkSize; j++) {
-
Complex[chunkSize] complexArray;
-
-
for(
int i =
0; i < chunkSize; i++) {
-
complexArray[i] = Complex(audio[(j*chunkSize)+i],
0);
-
}
-
-
result[j] = FFT.fft(complexArray);
-
}
程式碼的內層迴圈將取樣資料放入一個複數陣列中(虛部為0),外層迴圈遍歷每一塊資料,並進行FFT變換。
當我們對每一幀音訊訊號進行傅立葉變換之後,就可以開始構造音訊指紋了,這是shazam整個系統中最核心的部分。構造指紋最大的挑戰在於怎樣從眾多頻率中選出區分度最大的來。直觀上來說,選擇具有最大幅值的頻率(峰值)較為靠譜。
令人失望的一點是,幅值較大的頻率跨度可能很廣,從低音C(32.70Hz)到高音C(4186.01Hz)都可能出現。為了避免分析整個頻譜,我們通常將頻譜分成多個子帶,從每個子帶中選擇一個頻率峰值。在CreatingShazam in Java部落格中,作者選擇瞭如下幾個子帶:低音子帶為30 Hz - 40 Hz, 40 Hz - 80 Hz 和80 Hz - 120 Hz (貝司吉他等樂器的基頻會出現低音子帶),中音和高音子帶分別為120 Hz - 180 Hz 和180 Hz - 300Hz(人聲和大部分其他樂器的基頻出現在這兩個子帶)。每個子帶的最大頻率就構成了這一幀訊號的簽名,而這個簽名又是整首歌指紋的一部分。
-
public
final
int[] RANGE =
new
int[] {
40,
80,
120,
180,
300 };
-
-
// find out in which range is frequency
-
public int getIndex(int freq) {
-
int i =
0;
-
while (RANGE[i] < freq)
-
i++;
-
return i;
-
}
-
-
// result is complex matrix obtained in previous step
-
for (
int t =
0; t < result.length; t++) {
-
for (
int freq =
40; freq <
300 ; freq++) {
-
// Get the magnitude:
-
double mag = Math.log(results[t][freq].abs() +
1);
-
-
// Find out which range we are in:
-
int index = getIndex(freq);
-
-
// Save the highest magnitude and corresponding frequency:
-
if (mag > highscores[t][index]) {
-
points[t][index] = freq;
-
}
-
}
-
-
// form hash tag
-
long h = hash(points[t][
0], points[t][
1], points[t][
2], points[t][
3]);
-
}
-
-
private
static
final
int FUZ_FACTOR =
2;
-
-
private long hash(long p1, long p2, long p3, long p4) {
-
return (p4 - (p4 % FUZ_FACTOR)) *
100000000 + (p3 - (p3 % FUZ_FACTOR))
-
*
100000 + (p2 - (p2 % FUZ_FACTOR)) *
100
-
+ (p1 - (p1 % FUZ_FACTOR));
-
}
在構造指紋的過程中,我們要特別注意一點:使用者所處的環境會非常複雜,所以錄製的音訊質量差異很大。這就需要我們的演算法抗噪能力非常強,有必要在演算法中引入模糊化操作。模糊化操作非常重要,其直接影響最終的檢索質量。
為了查詢方便,指紋通常會作為散列表的鍵值,鍵值指向的部分包括該指紋在音樂中出現的時間和該音樂ID。下面是一個例子:
| Hash Tag |
Time in Seconds |
Song |
| 30 51 99 121 195 |
53.52 |
Song A by artist A |
| 33 56 92 151 185 |
12.32 |
Song B by artist B |
| 39 26 89 141 251 |
15.34 |
Song C by artist C |
| 32 67 100 128 270 |
78.43 |
Song D by artist D |
| 30 51 99 121 195 |
10.89 |
Song E by artist E |
| 34 57 95 111 200 |
54.52 |
Song A by artist A |
| 34 41 93 161 202 |
11.89 |
Song E by artist E |
如果對一個很大的音樂庫都執行上面的指紋提取操作,我們就可以構造一個該音樂庫對應的指紋庫。
6. 匹配音樂
為了識別正在播放的音樂,我們用手機錄製一段,然後按照上面的步驟提取指紋就可以從指紋庫中查詢音樂名了。
在查詢指紋庫的過程中,不可避免地會遇到一個指紋在多首歌中出現的問題,也即兩首原始音樂不同時刻提取的指紋相同。雖然我們可以通過多個指紋的匹配來縮小要匹配的音樂範圍,但是不足以少到只保留一首歌。這時就需要利用指紋庫中的另一個特徵:每個指紋出現的時間。
我們錄製的音樂片段可能從整首音樂的任意位置開始,所以我們不能直接比較兩個時間戳。但是,隨著匹配的指紋越來越多,我們可以分析匹配指紋的相對時間。例如,在查詢上面給定的指紋庫的過程中,我們發現指紋30 51 99 121 195在音樂A和E中出現。過了1s,我們又匹配上另一個指紋34 57 95 111 200,這個指紋在A中出現,而且和前一個指紋的時間差距也是1s。所以有很大可能,我們目前正在聽的歌就是A。
-
// Class that represents specific moment in a song
-
private
class DataPoint {
-
-
private
int time;
-
private
int songId;
-
-
public DataPoint(int songId, int time) {
-
this.songId = songId;
-
this.time = time;
-
}
-
-
public int getTime() {
-
return time;
-
}
-
public int getSongId() {
-
return songId;
-
}
-
}
假設i1和i2分別表示錄製音樂的兩個時刻,j1和j2表示指紋庫中原始音樂的兩個時刻。兩個指紋匹配的條件必須滿足兩條:
- RecordedHash(i1)= SongInDBHash(j1) AND RecordedHash(i2) = SongInDBHash(j2)
- abs(i1 -i2) = abs (j1 - j2)
利用相對時間來匹配指紋可以允許使用者從任意位置錄製歌曲。在前面我們也提到,使用者錄製的片段質量差異很大,所以很難出現片段中提取的指紋都和庫中的指紋匹配。錄製的片段會引入大量的錯誤匹配,所以我們不可能通過排除的方法找到正確的音樂。比較可靠的方式是對相對時間進行排序,然後選擇top1作為正確結果。
7. 自頂向下架構圖
下圖是聽歌識曲自頂向下的架構圖:
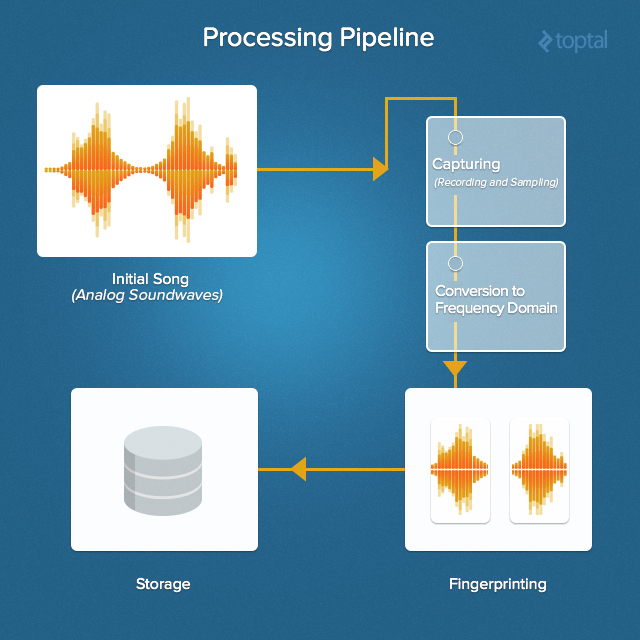
在上面的架構中,指紋庫會非常龐大,所以我們需要將指紋庫做得具有擴充套件性。由於儲存的資料沒有特別的依賴關係,所以NoSQL是一個非常好的選擇。
8. 結論
作者巴拉巴拉說了一大堆,主要是說shazam不光能搜歌,我們還可以拓展它的應用領域。一個很容易想到的點是用它來識別音樂是否存在剽竊。