
DQN 從入門到放棄1 DQN與增強學習
1 前言
深度增強學習Deep Reinforcement Learning是將深度學習與增強學習結合起來從而實現從Perception感知到Action動作的端對端學習End-to-End Learning的一種全新的演算法。簡單的說,就是和人類一樣,輸入感知資訊比如視覺,然後通過深度神經網路,直接輸出動作,中間沒有hand-crafted engineering的工作。深度增強學習具備使機器人實現真正完全自主的學習一種甚至多種技能的潛力。
雖然將深度學習和增強學習結合的想法在幾年前就有人嘗試,但真正成功的開端就是DeepMind在NIPS 2013上發表的一文,在該文中第一次提出Deep Reinforcement Learning 這個名稱,並且提出DQN(Deep Q-Network)演算法,實現從純影象輸入完全通過學習來玩Atari遊戲的成果。之後DeepMind在Nature上發表了改進版的DQN文章Human-level Control through Deep Reinforcement Learning

而Hinton,Bengio及Lecun三位大神在Nature上發表的Deep Learning綜述一文最後也將Deep Reinforcement Learning作為未來Deep Learning的發展方向。引用一下原文的說法:
We expect much of the future progress in vision to come from systems that are trained end-to-end and combine ConvNets with RNNs that use reinforcement learning to decide where to look.
從上面的原文可見三位大神對於Deep Reinforcement Learning的期待。而顯然這一年來的發展沒有讓大家失望,AlphaGo橫空出世,將進一步推動Deep Reinforcement Learning的發展。
Deep Reinforcement Learning的重要關鍵在於其具備真正實現AI的潛力,它使得計算機能夠完全通過自學來掌握一項任務,甚至超過人類的水平。也因此,DeepMind很早受到了Google等企業的關注。DeepMind 50多人的團隊在2014年就被Google以4億美元的價格收購。而15年12月份剛剛由Elon Musk牽頭成立的OpenAI,則一開始就獲得了10億美元的投資,而OpenAI中的好幾位成員都來自UC Berkerley的Pieter Abbeel團隊。
Pieter Abbeel團隊緊隨DeepMind之後,採用基於引導式監督學習直接實現了機器人的End-to-End學習,其成果也引起了大量的媒體報道和廣泛關注。去年的NIPS 2015 更是由Pieter Abbeel及DeepMind的David Silver聯合組織了Deep Reinforcement Learning workshop。可以說,目前在Deep Reinforcement Learning取得開拓性進展的主要集中在DeepMind和UC Berkerley團隊。
為了研究Deep Reinforcement Learning,DQN的學習是首當其衝的。只有真正理解了DQN演算法,才能說對Deep Reinforcement Learning入門。要理解並掌握DQN演算法,需要增強學習和深度學習的多方面知識,筆者在2014年底開始接觸DQN,但由於對基礎知識掌握不全,導致竟然花了近1年的時間才真正理解DQN的整個演算法。因此,本專欄從今天開始推出 DQN 從入門到放棄 系列文章,意在通過對增強學習,深度學習等基礎知識的講解,以及基於Tensorflow的程式碼實現,使大家能夠紮實地從零開始理解DQN,入門Deep Reinforcement Learning。本系列文章將以一週一篇的速度更新。另外要說明的一點是DQN已被Google申請專利,因此只能做研究用,不能商用。
2 預備條件
雖然說是從零開始,但是DQN畢竟也還屬於深度學習領域的前沿演算法,為了理解本系列的文章,知友們還是需要有一定的基礎:
- 一定的概率論和線性代數基礎(數學基礎)
- 一定的Python程式設計基礎(程式設計基礎,後面的程式碼實現將完全基於Tensorflow實現)
考慮到目前理解深度學習的知友肯定比理解增強學習的知友多,並且專欄也在同步翻譯CS231N的內容,本系列文章計劃用極短的篇幅來介紹DQN所使用的深度學習知識,而用更多的篇幅介紹增強學習的知識。
如果知友們具備以上的基本預備條件,那麼我們就可以開始DQN學習之旅了。
接下來本文將介紹增強學習的基礎知識。
3 增強學習是什麼
在人工智慧領域,一般用智慧體Agent來表示一個具備行為能力的物體,比如機器人,無人車,人等等。那麼增強學習考慮的問題就是智慧體Agent和環境Environment之間互動的任務。比如一個機械臂要拿起一個手機,那麼機械臂周圍的物體包括手機就是環境,機械臂通過外部的比如攝像頭來感知環境,然後機械臂需要輸出動作來實現拿起手機這個任務。再舉玩遊戲的例子,比如我們玩極品飛車遊戲,我們只看到螢幕,這就是環境,然後我們輸出動作(鍵盤操作)來控制車的運動。
那麼,不管是什麼樣的任務,都包含了一系列的動作Action,觀察Observation還有反饋值Reward。所謂的Reward就是Agent執行了動作與環境進行互動後,環境會發生變化,變化的好與壞就用Reward來表示。如上面的例子。如果機械臂離手機變近了,那麼Reward就應該是正的,如果玩賽車遊戲賽車越來越偏離跑道,那麼Reward就是負的。接下來這裡用了Observation觀察一詞而不是環境那是因為Agent不一定能得到環境的所有資訊,比如機械臂上的攝像頭就只能得到某個特定角度的畫面。因此,只能用Observation來表示Agent獲取的感知資訊。
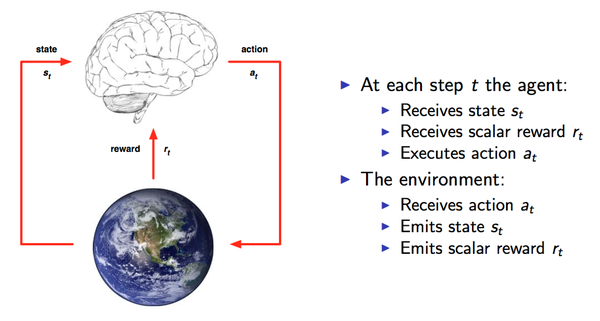 上面這張圖(來自David Silver的課程ppt)可以很清楚的看到整個互動過程。事實上,這就是人與環境互動的一種模型化表示。在每個時間點time-step Agent都會從可以選擇的動作集合A中選擇一個動作
上面這張圖(來自David Silver的課程ppt)可以很清楚的看到整個互動過程。事實上,這就是人與環境互動的一種模型化表示。在每個時間點time-step Agent都會從可以選擇的動作集合A中選擇一個動作執行.這個動作集合可以是連續的比如機器人的控制也可以是離散的比如遊戲中的幾個按鍵。動作集合的數量將直接影響整個任務的求解難度,因此DeepMind才從玩最簡單的遊戲做起,DQN演算法(不考慮其變種)僅適用於離散輸出問題。
那麼知道了整個過程,任務的目標就出來了,那就是要能獲取儘可能多的Reward。沒有目標,控制也就無從談起,因此,獲取Reward就是一個量化的標準,Reward越多,就表示執行得越好。每個時間片,Agent都是根據當前的觀察來確定下一步的動作。觀察Observation的集合就作為Agent的所處的狀態State,因此,狀態State和動作Action存在對映關係,也就是一個state可以對應一個action,或者對應不同動作的概率(常常用概率來表示,概率最高的就是最值得執行的動作)。狀態與動作的關係其實就是輸入與輸出的關係,而狀態State到動作Action的過程就稱之為一個策略Policy,一般用表示,也就是需要找到以下關係:
或者
其中a是action,s是state。第一種是一一對應的表示,第二種是概率的表示。
增強學習的任務就是找到一個最優的策略Policy從而使Reward最多。
我們一開始並不知道最優的策略是什麼,因此往往從隨機的策略開始,使用隨機的策略進行試驗,就可以得到一系列的狀態,動作和反饋:
這就是一系列的樣本Sample。增強學習的演算法就是需要根據這些樣本來改進Policy,從而使得得到的樣本中的Reward更好。由於這種讓Reward越來越好的特性,所以這種演算法就叫做增強學習Reinforcement Learning。
4 What's Next?
在下一篇文章中,筆者將和大家分享MDP馬爾科夫決策過程的知識,這是構建增強學習演算法的基礎。敬請關注!