
爬蟲(一):爬蟲原理與資料抓取
1.通用爬蟲和聚焦爬蟲
根據使用場景,網路爬蟲可分為 通用爬蟲 和 聚焦爬蟲 兩種.
通用爬蟲
通用網路爬蟲 是 捜索引擎抓取系統(Baidu、Google、Yahoo等)的重要組成部分。主要目的是將網際網路上的網頁下載到本地,形成一個網際網路內容的映象備份
聚焦爬蟲
聚焦爬蟲,是"面向特定主題需求"的一種網路爬蟲程式,它與通用搜索引擎爬蟲的區別在於: 聚焦爬蟲在實施網頁抓取時會對內容進行處理篩選,儘量保證只抓取與需求相關的網頁資訊。
2.HTTP和HTTPS
HTTP協議(HyperText Transfer Protocol,超文字傳輸協議):是一種釋出和接收 HTML頁面的方法。
HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)簡單講是HTTP的安全版,在HTTP下加入SSL層。
HTTP的埠號為80HTTPS的埠號為443
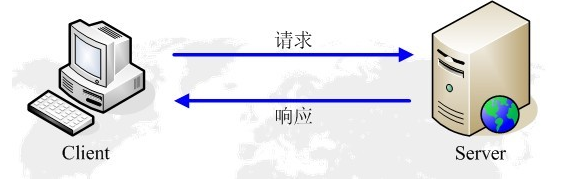
2.1 HTTP工作原理
絡爬蟲抓取過程可以理解為模擬瀏覽器操作的過程。
瀏覽器的主要功能是向伺服器發出請求,在瀏覽器視窗中展示您選擇的網路資源,HTTP是一套計算機通過網路進行通訊的規則。HTTP通訊由兩部分組成: 客戶端請求訊息 與 伺服器響應訊息
2.2客戶端HTTP請求
URL只是標識資源的位置,而HTTP是用來提交和獲取資源。客戶端傳送一個HTTP請求到伺服器的請求訊息,包括以下格式:
請求行、請求頭部、空行、請求資料
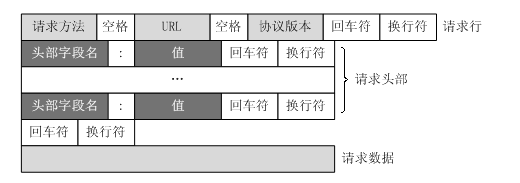
常用的請求報頭
Host (主機和埠號)
Connection (連結型別)
Upgrade-Insecure-Requests (升級為HTTPS請求)
User-Agent (瀏覽器名稱)
Accept (傳輸檔案型別)
Referer (頁面跳轉處)
Accept-Encoding(檔案編解碼格式)
Accept-Language(語言種類)
Accept-Charset(字元編碼)
Cookie (Cookie)
Content-Type (POST資料型別)
2.3 服務端HTTP響應
HTTP響應也由四個部分組成,分別是: 狀態行
訊息報頭、空行、響應正文
常用的響應報頭:
Cache-Control:must-revalidate, no-cache, private。
Connection:keep-alive
Content-Encoding:gzip
Content-Type:text/html;charset=UTF-8
Date:Sun, 21 Sep 2016 06:18:21 GMT
Expires:Sun, 1 Jan 2000 01:00:00 GMT
Pragma:no-cache
Server:Tengine/1.4.6
Transfer-Encoding:chunked
Vary: Accept-Encoding
2.4 響應狀態碼
響應狀態程式碼有三位數字組成,第一個數字定義了響應的類別,且有五種可能取值。
常見狀態碼:
-
100~199:表示伺服器成功接收部分請求,要求客戶端繼續提交其餘請求才能完成整個處理過程。 -
200~299:表示伺服器成功接收請求並已完成整個處理過程。常用200(OK 請求成功)。 300~399:為完成請求,客戶需進一步細化請求。例如:請求的資源已經移動一個新地址、常用302(所請求的頁面已經臨時轉移至新的url)、307和304(使用快取資源)。400~499:客戶端的請求有錯誤,常用404(伺服器無法找到被請求的頁面)、403(伺服器拒絕訪問,許可權不夠)。500~599:伺服器端出現錯誤,常用500(請求未完成。伺服器遇到不可預知的情況)。
2.5Cookie 和 Session:
伺服器和客戶端的互動僅限於請求/響應過程,結束之後便斷開,在下一次請求時,伺服器會認為新的客戶端。
為了維護他們之間的連結,讓伺服器知道這是前一個使用者傳送的請求,必須在一個地方儲存客戶端的資訊。
Cookie:通過在 客戶端 記錄的資訊確定使用者的身份。
Session:通過在 伺服器端 記錄的資訊確定使用者的身份。
3.urllib庫的基本使用
在Python 3以後的版本中,urllib2這個模組已經不單獨存在(也就是說當你import urllib2時,系統提示你沒這個模組),urllib2被合併到了urllib中,叫做urllib.request 和 urllib.error 。
例:
urllib2.urlopen()變成了urllib.request.urlopen()
urllib2.Request()變成了urllib.request.Request()
urllib整個模組分為urllib.request, urllib.parse, urllib.error,urllib.robotparser。
urllib.request開啟和瀏覽url中內容
urllib.error包含從 urllib.request發生的錯誤或異常
urllib.parse解析url
urllib.robotparser解析 robots.txt檔案
在python3.X以上版本通過如下命令安裝。
pip install urllib33.1urllib.request.urlopen()
向指定的url傳送請求,並返回伺服器響應的類檔案物件;支援一系列類檔案讀取方法,如:read()。其引數時url地址。
urllib.request.Request()
建立request物件,在需要執行更復雜的操作,比如增加HTTP報頭,必須建立一個 Request 例項來作為urlopen()的引數;而需要訪問的url地址則作為 Request 例項的引數。
3.2 User-Agent
給一個網站傳送請求的話,通常會比較唐突很容易被拒絕,因此需要使用一個合法的身份進行訪問,此時就涉及到代理身份,這就是所謂user-agent頭,也可以理解為給我們的爬蟲加上一個偽裝的身份。
ua_header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}import urllib.request
url = "http://www.itcase.com"
ua_header = {"User-Agent":"Mozilla/5.0 (compatible;MSIE 9.0;Windows NT 6.1;\
Trident/5.0;"}
request = urllib.request.Request(url, headers=ua_header)
response = urllib.request.urlopen(request)
html = response.read()
print(html)新增更多的Header資訊
在 HTTP Request 中加入特定的 Header,來構造一個完整的HTTP請求訊息。
- 通過呼叫Request的add_header()方法新增/修改一個特定的header;get_header()來檢視已有的header
import urllib.request
url = "http://www.itcase.com"
ua_header = {"User-Agent":"Mozilla/5.0 (compatible;MSIE 9.0;Windows NT 6.1;\
Trident/5.0;"}
request = urllib.request.Request(url, headers=ua_header)
#新增/修改一個特定的header
request.add_header("Connection", "keep-alive")
#檢視已有的header
#request.get_header(header_name="Connection")
response = urllib.request.urlopen(request)
#檢視響應碼狀態
print(response.code)
html = response.read()
print(html)- 隨機新增/修改User-Agent
import urllib.request
import random
url = "http://www.itcase.cn"
ua_list = [
"Mozilla/5.0 (Windows NT 6.1;) Apple...",
"Mozilla/5.0 (X11;CrOS i686 2268.111.0...",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X...",
"Mozilla/5.0 (Macintosh; Intel Mac OS..."
]
#ua_header = {"User-Agent":"Mozilla/5.0 (compatible;MSIE 9.0;Windows NT 6.1;\
# Trident/5.0;"}
user_agent = random.choice(ua_list)
print(user_agent)
request = urllib.request.Request(url)
#新增/修改一個特定的header
request.add_header("User_agent", user_agent)
#檢視已有的header
print(request.get_header("User_agent"))
response = urllib.request.urlopen(request)
#檢視響應碼狀態
#print(response.code)
html = response.read()
print(html)
注意:User_agent中U需要大寫。
4.HTTP/HTTPS的GET和POST方法
在python3.X中,urllib.parse替代urllib2中的urllib。urllib.parse僅接受URL,不能建立設定了header的Request例項。但其提供的urllib.parse.urlencode()方法可以get查詢字串的產生,編碼工作可以將key:value這樣的鍵值對轉換成“key=value”這樣的字串;相反urllib.parse.unquote(),把URL編碼字串轉換會原先的字串
import urllib.parse
word = {"wd":"人工智慧"}
encode = urllib.parse.urlencode(word)
print(encode)
print(urllib.parse.unquote(encode))wd=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD
wd=人工智慧通常HTTP請求提交資料,需要編碼成 URL編碼格式,然後做為url的一部分,或者作為引數傳到Request物件中。
4.1 Get方式:
一般用於我們向伺服器獲取資料,比如說,我們用百度搜索“人工智慧”:https://www.baidu.com/s?wd=人工智慧
其實是以https://www.baidu.com/s?wd=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD傳送請求的,基於這種方式,我們可以使用Get方式來發送請求。
import urllib.parse
import urllib.request
url = "http://www.baidu.com/s"
word = {"wd":"人工智慧"}
word = urllib.parse.urlencode(word)
newrul = url + "?" + word
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
request = urllib.request.Request(newrul, headers=headers)
response = urllib.request.urlopen(request)
print(response.read())4.2 POST方式:
Request請求物件的裡有data引數,它就是用在POST裡的,我們要傳送的資料就是這個引數data,data是一個字典,裡面要匹配鍵值對。
import urllib.parse
import urllib.request
url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
headers = {"User-Agent":"Mozilla..."}
formdata = {"type":"AUTO","i":"i love python","doctype":"json","xmlVersion":"1.8","keyfrom":"fanyi.web","ue":"UTF-8","action":"FY_BY_ENTER","typoResult":"true"}
data = urllib.parse.urlencode(formdata)
request = urllib.request.Request(url, data=data, headers=headers)
response = urllib.request.urlopen(request)
print(response.read())4.3 獲取AJAX載入的內容
有些網頁內容使用AJAX載入,只要記得,AJAX一般返回的是JSON,直接對AJAX地址進行post或get,就返回JSON資料了。
import urllib.parse
import urllib.request
# demo1
url = "https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action"
headers={"User-Agent": "Mozilla...."}
# 變動的是這兩個引數,從start開始往後顯示limit個
formdata = {'start':'0','limit':'10'}
data = urllib.parse.urlencode(formdata).encode("utf-8")
request = urllib.request.Request(url, data = data, headers = headers)
response = urllib.request.urlopen(request)
print (response.read().decode("utf-8"))4.4 處理HTTPS請求 SSL證書驗證
某些https協議的網站需要進行驗證SSL證書,如果SSL驗證不通過或作業系統不信任伺服器的安全證書,則無法訪問,urllib可以為HTTPS請求驗證SSL證書。如果以後遇到這種網站,我們需要單獨處理SSL證書,讓程式忽略SSL證書驗證錯誤,即可正常訪問。
import urllib.request
import urllib.parse
import ssl
context = ssl._create_unverified_context()
url = "https://www.12306.cn/mormhweb/"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
request = urllib.request.Request(url, headers=headers)
reponse = urllib.request.urlopen(request, context=context)
print(reponse.read())注:urllib目前在python3.x的版本中貌似已經不用ssl也可以爬取資料。
4.5 CA(Certificate Authority)
是數字證書認證中心的簡稱,是指發放、管理、廢除數字證書的受信任的第三方機構。CA的作用是檢查證書持有者身份的合法性,並簽發證書,以防證書被偽造或篡改,以及對證書和金鑰進行管理。可以看做網路中的身份證。
5.Handler處理器 和 自定義Opener
在上文中用到的urlopen其實就是一個Opener,是系統預定義的一個OpenerDirector例項。但是urlopen()不支援代理、cookie等高階功能,因此我們還需要自己建立一個Opener來承載更強大的功能。構建步驟如下程式碼:
import urllib.request
#構建HTTPHandler處理器
http_handler = urllib.request.HTTPHandler()
#建立支援處理http請求的opener物件
opener = urllib.request.build_opener(http_handler)
#構建request請求
request = urllib.request.Request("http://baidu.com/")
#呼叫自定義的opner的open方法,傳送request請求
response = opener.open(request)
#獲取伺服器響應內容
print(response.read())上述程式碼實現的功能和urlopen作用一樣,為了說明自定義的opener的妙用,我們只舉個簡單例子:檢視Debug log
http_handler = urllib.request.HTTPHandler(debuglevel=1)5.1 ProxyHandler處理器(新增代理)
想必大家都聽說反爬蟲這個概念,對付這個問題最好用的方式就是使用代理IP。原理就是每隔一段時間更換一個代理,這樣即使IP被禁用了也可以換個IP繼續爬取。在urllib中通過ProxyHandler來設定使用代理伺服器。使用方法見下列程式碼
import urllib.request
httpproxy_handler = urllib.request.ProxyHandler({"http":"124.88.67.81.80"})
nullproxy_handler = urllib.request.ProxyHandler({})
#驗證有無代理的區別而設定的開關
proxySwitch = True
#使用代理handler物件
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request("http://baidu.com/")
response = opener.open(request)
print(response.read())5.2 密碼管理的類:HTTPPasswordMgrWithDefaultRealm()
主要用途有如下兩種:
-
代理授權驗證:ProxyBasicAuthHandler()
作用是驗證代理授權的使用者名稱和密碼,防止407錯誤,構造方法如下程式碼。
import urllib.request
import urllib.parse
user = "mr_mao_hacker"
passwd = "sffqry9r"
proxyserver = "61.158.163.130:16816"
#構建密碼管理物件,儲存需要處理的使用者名稱和密碼
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
#新增賬戶資訊,add_password中的引數分別是:realm與遠端伺服器相關的域,常為NONE
#代理伺服器,使用者名稱,密碼
passwdmgr.add_password(None, proxyserver, user, passwd)
#構建ProxyBasicAuthHandler物件
proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr)
#通過build_opener()使用Handler物件
opener = urllib.request.build_opener(proxyauth_handler)
request = urllib.request.Request("http://www.baidu.com/")
response = opener.open(request)
print(response.read())
-
Web客戶端授權驗證:HTTPBasicAuthHandler()
防止在web伺服器需要身份驗證時,發生401錯誤。
import urllib.request
import urllib.parse
user = "test"
passwd = "124"
webserver = "http://192.168.199.107"
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
passwdmgr.add_password(None, webserver, user, passwd)
#構建HTTP基礎使用者名稱/密碼驗證的HTTPBasicAuthHandler
httpauth_handler = urllib.request.HTTPBasicAuthHandler(passwdmgr)
opener = urllib.request.build_opener(httpauth_handler)
request = urllib.request.Request("http://192.168.199.107")
response = opener.open(request)
print(response.read())6.Cookie
網站伺服器為了辨別使用者身份和進行Session跟蹤,而儲存在使用者瀏覽器上的文字檔案,Cookie可以保持登入資訊到使用者下次與伺服器的會話。由於HTTP是無狀態的面向連線的協議, 為了保持連線狀態, 引入了Cookie機制。
Cookie是http訊息頭中的一種屬性,包括:
Cookie名字(Name)
Cookie的值(Value)
Cookie的過期時間(Expires/Max-Age)
Cookie作用路徑(Path)
Cookie所在域名(Domain)
Cookie安全連線(Secure)在寫爬蟲中cookie的重要作用是判斷註冊使用者是否已經登入網址,此時在網頁上使用者會看到是否儲存使用者資訊的提示。獲取一個有登入資訊的Cookie模擬登入程式碼如下:
6.1 cookielib庫 和 HTTPCookieProcessor處理器
cookielib:主要作用是建立儲存cookie的物件,常用的物件有:CookieJar(最為常用)、FileCookieJar(檢索cookie資訊並將cookie儲存到檔案中)、MozillaCookieJar(建立與Mozilla瀏覽器 cookies.txt相容)、LWPCookieJar (建立與libwww-perl標準的 Set-Cookie3 檔案格式相容),通常如果和本地檔案互動會使用MozillaCookieJar或LWPCookieJar。
HTTPCookieProcessor:主要作用是處理cookie物件,並構建handler物件。
-
獲取Cookie,並儲存到CookieJar()物件中
import urllib.request
from http import cookiejar
cookiejar = cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookiejar)
opener = urllib.request.build_opener(handler)
opener.open("http://www.baidu.com/")
cookieStr = ""
for item in cookiejar:
cookieStr = cookieStr + item.name + "=" +item.value + ";"
print(cookieStr[:-1])
-
訪問網站獲得cookie,並把獲得的cookie儲存在cookie檔案中
import urllib.request
from http import cookiejar
filename = "cookie.txt"
cookiejar = cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookiejar)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com/")
cookiejar.save()-
從檔案中獲取cookies,做為請求的一部分去訪問
import urllib.request
from http import cookiejar
cookiejar = cookiejar.MozillaCookieJar()
cookiejar.load('cookie.txt')
handler = urllib.request.HTTPCookieProcessor(cookiejar)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com/")參考: