
神經網路簡單入門
這是我們人工智慧課的作業。有助於大家理解神經網路。並且通過matlab簡單的程式碼實現。
前向型神經網路概述與應用實踐
摘 要 本文將介紹前向型神經網路,它是神經網路中一個十分常見並且重要的結構。本文首先將介紹神經網路的基本概念,之後介紹前向型神經網路的基本概念,並通過一些例項進行展示。第三部分介紹BP網路的基本概念,以及通過實踐分類和擬合問題,對神經網路有進一步的認識。最後一部分是總結全文,並對未來學習進行展望。
- 神經網路簡介
人工神經網路(Artificial Neural Network),它從資訊處理角度對人腦神經元網路進行抽象, 建立某種簡單模型,按不同的連線方式組成不同的網路。神經網路是一種運算模型,由大量的節點(或稱神經元)之間相互聯接構成。每個節點代表一種特定的輸出函式,稱為激勵函式(activation function)。每兩個節點間的連線都代表一個對於通過該連線訊號的加權值,稱之為權重,這相當於人工神經網路的記憶。而網路自身通常都是對自然界某種演算法或者函式的逼近,也可能是對一種邏輯策略的表達
- 前向型神經網路及應用實踐
本篇將介紹前向型神經網路,在計算輸出值的過程中,輸入值從輸入層單元向前逐層傳播,經過隱藏層最後到達輸出層,得到輸出。前向網路第一層的單元與第二層所有的單元相連,第二層又與其上一層單元相連,同一層中的各個單元之間沒有連線。前向網路中神經元的激發函式,可採用線性硬閾值函式或單元上升的非線性函式等來表示。訓練過程中,調節權值的演算法都是採用有教師(監督學習)的delta學習規則。
-
- 感知器神經網路
它是一個由線性閾值單元組成的網路,學習演算法採用delta演算法。感知器網路的結構和學習演算法簡單,其他型別的前向型神經網路都是在它的基礎上發展而來的。感知器網路,根據有沒有隱藏層分為單層感知器和多層感知器網路。
-
-
- 單層感知器模型:
-

圖1 單層感知器模型
如圖1所示,它包括一個線性的累加器(公式2-1)和一個二值閾值元件(公式2-2),同時還有一個外部偏差b。線性累加器的輸出作為二值閾值元件的輸入,這樣當二值閾值元件的輸入是正數,神經元就產生輸出+1,反之,若其輸入是負數,則產生輸出-1。
|
|
(2-1) |
|
|
(2-2) |
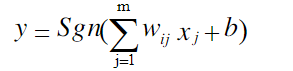
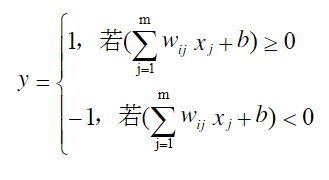
使用單層感知器的目的就是讓其對外部輸入 x1 , x2 …, xm 進行識別分類,單層感知器可將外部輸入分為兩類 l1 和 l 2 。當感知器的輸出為+1時,我們認為輸入 x1 , x2 ,…, xm 屬於 l1 類,當感知器的輸出為-1時,認為輸入 x1 , x2 ,…, xm 屬於 l 2 類,從而實現兩類目標的識別,如圖2所示。

圖2 兩類模式識別的判定問題
學習演算法如下:
第一步:設定變數和參量: X(n)= [1, x1(n), x2(n), …, xm(n)]T為輸入向量,或稱訓練樣本; W(n)= [b(n), w1(n), w2(n), …, wm(n)]T為權值向量; b(n) 為偏差; y(n)為實際輸出; d(n)為期望輸出; η為學習速率; n為迭代次數。
第二步:初始化,賦給Wj(0)各一個較小的隨機非零值;
第三步:對於一組輸入樣本X(n)= [1, x1(n), x2(n), …, xm(n)],指定它的期望輸出(亦稱之為導師訊號)。
第四步:計算實際輸出:
yn=Sgn(WT(n)X(n))![]()
第五步:調整感知器的權值向量:
Wn+1=Wn+η[dn-y(n)]X(n) ![]()
第六步:判斷是否滿足條件,若滿足演算法結束,若不滿足將n值增加1,轉到第三步重新執行。
感知器的侷限性:
(1)感知器神經網路的傳輸函式一般採用閾值函式,故輸出值只有兩種(0 或1,-1或l ) ;
(2)單層感知器網路只能解決線性可分的分類問題,而對線性不可分的分類問題無能為力;
(3)感知器學習演算法只適於單層感知器網路,所以一般感知器網路都是單層的。
Matlab演示:
這裡我們實現一個很簡單的一個神經元神經網路。輸入向量P以及目標向量T表示為圖3左圖。利用matlab模擬,我們可以得到圖3右圖感知層訓練後得到的分類線。


圖3 單層感知器模型實驗圖
|
P = [-0.6 -0.7 0.8; 0.9 0 1];%為輸入向量 T = [ 1 1 0 ];%輸出向量 net = newp ([-1 1;-1 1],1);%建立一個感知器神經網路,引數分別為輸入向量的取值範圍和網路層神經元數目 net.trainParam.epochs = 15;設定訓練的最大次數 net = train(net,P,T);%開始訓練 plotpv(P,T);%繪製點 plotpc(net.iw{1},net.b{1});%繪製分類線 |
-
-
- 多層感知器神經網路
-
單層感知器由於其結構和學習規則的侷限性,其應用也收到一定的限制。為了解決線性不可分的輸入向量的分類問題,可以增加網路層。
由於感知神經網路學習規則的限制,他只能對單層感知器神經網路進行訓練,這裡提供了一種二層感知器神經網路的設計方法。
(1)把神經網路的第一層設計為隨機感知器層,且不對它進行訓練,而隨機的初始化她的權值和閾值,當它接受個輸入元素值時,其輸出也是隨機的。但其權值和閾值一旦固定下來,對輸入向量模式的對映也隨之確定下來。
(2)以第一層的輸出作為第二感知層的輸入,並對應輸入模式,確定第二感知層的目標向量,然後對第二感知器層進行訓練。
(3)由於第一感知器層的輸入是隨機的,所以在訓練過程中,整個網路可能達到訓練誤差的指標,也可能達不到。所以當達不到訓練誤差效能指標時,需要重新對隨機感知器層的權值和閾值進行初始化賦值,直到達到要求為止。
-
- 線性神經網路
與感知器神經元不同的是,線性神經元採用的傳遞函式為線性函式purelin,其他輸入與輸出到之間是簡單的純比例關係。
a=purelin(wp+b)=wp+b![]()
線性神經網路權值和閾值的學習規則採用的是基於最小二乘法是Widrow-Hoff學習演算法。
Wk+1=Wk+∆W(k)![]() ,bk+1=bk+∆b(k)
,bk+1=bk+∆b(k)![]()
其中
∆Wk=-α∂e2k∂W=-α 2e(k)∂e∂W![]()
∆bk=-α∂e2(k)∂b=-α 2e(k)∂e∂b![]()
且有
∂e∂W=∂∂Wtk-W×pk+b=-p(k)![]()
∂e∂b=-1![]()
所以調節公式為
Wk+1=Wk+2αe(k)pT(k)![]()
bk+1=bk+2αe(k)![]()
2α![]() 為學習率,一般記為η
為學習率,一般記為η![]() ,當η
,當η![]() 較大時,學習速率加快,反之亦然。
較大時,學習速率加快,反之亦然。
- BP網路
感知器神經網路的學習規則只能訓練單層神經網路,而單層神經網路只能解決線性可分的分類問題。多層神經網路可以用於非線性分類問題,但是需要尋找訓練多層網路的學習演算法。
BP神經元模型,如圖4所示

圖4 BP神經元模型
BP神經元與其他神經元類似,不同的是BP神經元的傳輸函式為非線性函式,最常用的函式是logsig和tansig以及純線性函式pureline。
在確定了BP網路的結構後,要通過輸入輸出樣本集對網路進行訓練,即對網路的閾值和權值進行學習和修正,以使網路實現給定的輸入和輸出關係、
BP網路的學習過程分為兩個階段:
第一個極端是輸入已知學習樣本,通過設定網路的結構和前一次迭代的權值和閾值,從網路第一向後計算各神經元的輸出。
第二個階段是對權值和閾值進行修改,從最後一層向前計算各權值和閾值對總誤差的影響(梯度),據此對各權值和閾值進行修改。
以上兩個過程反覆交替,直到達到收斂為止。由於誤差逐層往回傳遞,以修正層與層之間的權值和閾值,所以稱該演算法為誤差反向傳播演算法,這種誤差反傳學習演算法可以推廣到有若干個中間層的多層網路
Matlab演示
下面將通過分類和擬合兩個例子來對BP網路進行演示。
1.分類
在單感知器網路解構中,我們只能解決線性分類的問題,通過BP網路可以解決非線性的分類問題。這裡我們的輸入向量和目標向量表示如圖5左所示。


圖5 BP網路模擬
這裡構建了一個前向BP網路newff,構建網路程式碼如下:
newff([-1 1;-1 1],[3 1],{'logsig' 'logsig'},'traingdx');
第一個引數為輸入向量的取值範圍,第二個引數為神經網路的每層神經元個數,第三個為每層網路的轉移函式,最後一個為訓練函式。
通過訓練之後,我們可以看到如圖5右的分類線。
但是隨著神經網路每層的神經元的增加,以及神經網路的增加,每個神經元所做的工作也就越來越不容易解釋,這也是目前神經網路以及。所面臨的的問題,為了能夠相對清楚的瞭解簡單結構神經網路推薦網站:http://playground.tensorflow.org/ 如圖6所示,對於類似的資料集,展示了神經網路是如何進行分類的。

圖6 模擬平臺演示1
通過增加神經網路的層數,我們可以發現分類效果變得相較之前更好一些,如圖7所示。

圖7 模擬平臺演示2
2.擬合
已知系統輸入點如圖8座標中表現所示。可以通過BP網路來實現曲線的擬合。

圖8 擬合座標
newff([-1,1],[15 1],{'tansig' 'purelin'},'traingdx','learngdm');
這個函式和分類的函式相似,只是多了最後的一項引數,為神經網路權值/偏差的學習函式。我們可以看到當隱層為15個神經元(圖9(1))和10個(圖9(2))以及5個(圖9(3))的時候表現的擬合效果。以及當訓練函式為‘trainbr’,並且隱層為15個神經元時(圖9(4))的擬合效果。


(1) (2)


(3) (4)
圖9 擬合結果
通過這個對比試驗,可以發現基於traingdx即自適應學習速率動量梯度下降反向傳播的方法進行訓練神經元個數在15個的時候效果非常好,但是有些過度擬合,在10個的時候擬合效果較好。當使用trainbr即貝葉斯正則化演算法的方法時,相同神經元個數,擬合曲線更為光滑。因而不同的學習方法會展現出不同的特性,導致訓練出不一樣的結果,因此在日後的學習中,需要通過這樣的實踐操作來更好的理解演算法。