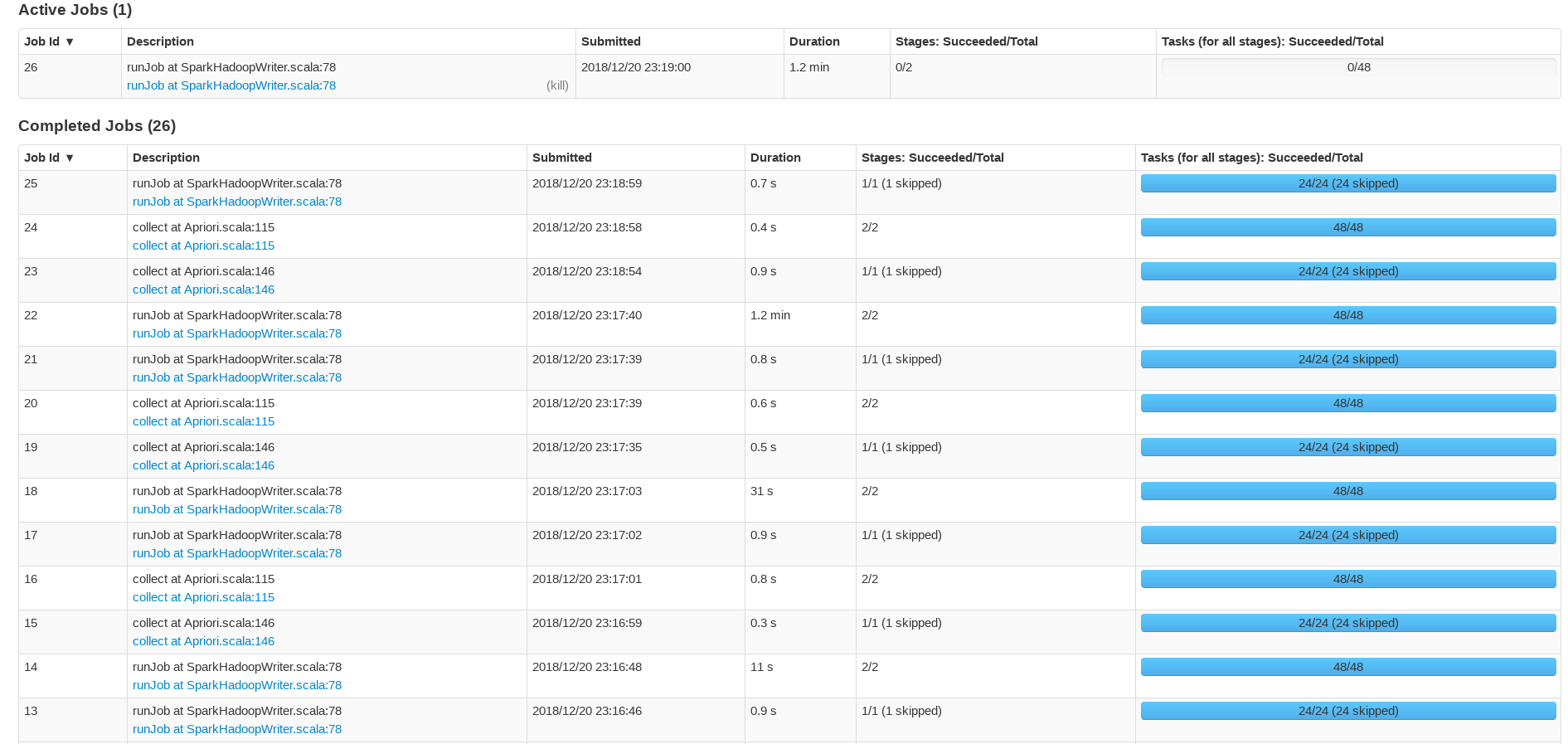
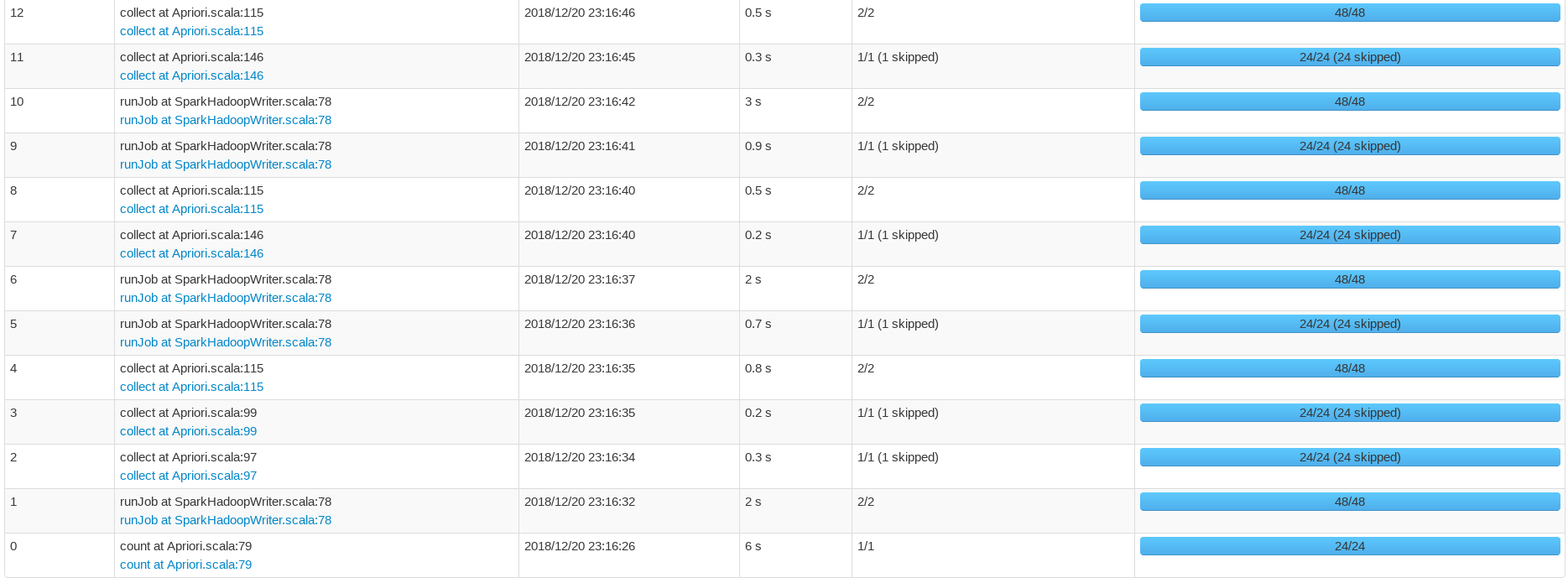
基於spark實現並行化Apriori演算法
詳細程式碼我已上傳到github:click me
一、 實驗要求
在 Spark2.3 平臺上實現 Apriori 頻繁項集挖掘的並行化演算法。要求程式利用 Spark 進
行平行計算。
二、演算法設計
2.1 設計思路
- 變數定義
- D為資料集,設Lk是k項頻繁項集,Ck是k項候選集,每一行資料定義為一筆交易(transaction),交易中的每個商品為項item。
- 支援度: support, 即該項集在資料集D中出現的次數
- 演算法流程
- 單機Apriori演算法的主要步驟如下:
- 獲取輸入資料,產生頻繁1項集,以及和I作為候選集,掃描資料集D,獲取候選集C1的支援度,並找出最小支援度min_sup的元素作為頻繁1項集L1.
- 掃描資料集D,獲取候選集Ck的支援度,並找出其中滿足最小支援度的元素作為頻繁k項集Lk
- 通過頻繁k項集Lk產生k+1候選集Ck+1
- 通過迭代步驟2和3,直到找不到k+1項集結束
- 單機Apriori演算法的主要步驟如下:
並行化設計的思路主要是考慮將對於支援度計數的過程使用wordcount來進行統計。
2.2 並行化演算法設計
Apriori演算法產生頻繁項集有兩個特點:第一,它是逐層的,即從頻繁1-項集到頻繁k-項集;第二,它使用產生-測試的策略來發現頻繁項,每次迭代後都由前一次產生的頻繁項來產生新的候選項,然後對新產生的候選項集進行支援度計數得到新的頻繁項集。根據演算法的特點,我們將演算法分為兩個階段:
如下圖1.1演算法的並行化框架圖,主節點每次迭代時需要將候選項集以廣播的形式分發到每個從節點,每個從節點收到之後進行一些列的操作得到新的頻繁項集,如此反覆直至求得最大頻繁項集。

階段1:從HDFS上獲取原始的資料集SparkRDD,載入到分散式記憶體中。掃描所有的RDD事務,進行支援度計數,產生頻繁1-項集;如圖1.2所示為Ap演算法並行化第一階段的Lineage圖。

圖1.2 Apriori演算法並行化第一階段的Lineage圖 原始事務集由flatMap函式去讀取事務,並將所有的事務轉化為Spark RDD並cache到分散式記憶體中。接下來,在每一個事務中執行flatMap函式來獲取所有的Items項集,之後執行map函式,發射<Item, 1>的key/value形式,接下來執行reduceByKey函式統計每一個候選1-項集的支援度,最後並利用事先設好的支援度閾值進行剪枝,所有超過支援度閾值的項集將會生成頻繁1-項集,下面給出了第一階段的演算法虛擬碼

階段2:在這個階段,不斷迭代使用頻繁k-項集去產生頻繁k+1項集

圖1.3 Apriori演算法並行化第二階段的Lineage圖 如圖1.3所示,首先讀取頻繁k-項集並且以<itemSet, Count>的形式將其儲存為Spark RDD。接下來,從頻繁k-項集得到候選(k+1)-項集。為加速從候選項集中查詢(k+1)-項集的過程,將候選(k+1)-項集存放在雜湊表中,並將其broadcast到每個worker節點。接下來,通過flatMap函式獲取每個候選項集在原始事務集中的支援度,進一步對每個候選項使用map函式得到<ItemSet, 1>,之後通過reduceBykey函式蒐集每個事務的最終的支援度計數,最後利用實現設定好的支援度閾值剪枝,支援度大於等於最小閾值的頻繁項集將會以key/value的形式輸出,作為頻繁(k+1)-項集,下面給出了演算法第二階段的虛擬碼。

2.3 程式設計與效能分析
讀取資料集,按空格劃分每行內容,並用HashSet儲存,方便後期求子集以及一些集合操作
// 將輸入資料分割槽,由於後面要頻繁使用。因此快取起來 val transations = sc.textFile(input, num) .map(x => { val content = x.split("\\s+") val tmp = new HashSet[String] for (i <- 0 until content.length) { tmp.add(content(i)) } tmp }).cache()根據支援度和資料總量計算頻繁項閾值,便於後期統計集合頻度後直接對比
// 計算頻繁項閾值 val numRecords = transations.count().toDouble val freqThre = numRecords * support println("frequency threshold:" + freqThre)計算頻繁1項集用於後續的迴圈迭代計算
// 計算頻繁1項集 val oneFreqSet = transations .flatMap(_.seq) .map(x => (x, 1)) .reduceByKey(_ + _) .filter(x => x._2 >= freqThre) .map(x => (HashSet(x._1), x._2 / numRecords))利用上一輪迭代計算生成的頻繁k項集來構造候選k+1項集,然後通過比頻繁項閾值比對篩選出頻繁k+1項集。這裡有一點要注意的,由於從檔案讀入的源資料transaction被劃分在各個partition上,而候選集candidates要與transaction中每條記錄比對來統計頻度,因此需要spark呼叫broadcast將候選集廣播到每個partition上
// 生成頻繁項的候選集 val candidates = generateCandidates(preFreSets, round) // 將候選項集廣播到各個分割槽 val broadcastCandidates = sc.broadcast(candidates) //複雜度:len(transactions) * len(candidates) * round * transaction項的平均長度 //這裡的len(transaction)是指各個partition上transaction的平均長度 val curFreqSet = transations .flatMap(x => verifyCandidates(x, broadcastCandidates.value)) .reduceByKey(_ + _) .filter(x => x._2 >= freqThre) // 寫入頻繁round項集結果到hdfs curFreqSet.map(a => { val out = a._1.mkString(",") + ":" + (a._2 / numRecords).toString out }).saveAsTextFile(output + "/" + infileName + "freqset-" + round) // 生成頻繁round-Itemsets,用於下一輪迭代生成候選集 preFreSets = curFreqSet.collect().map(x => x._1)第round輪迭代,由候選項集生成頻繁項集的複雜度:len(transactions) * len(candidates) * round * transaction項的平均長度,這裡的len(transaction)是指各個partition上transaction的平均長度,儘管我們通過提高併發度的方式將複雜度的稍微將了一些,可是演算法的整體複雜度還是很高,特別是當源資料集很大時,這樣查表式地驗證候選集很費時,有考慮將項集索引,但是如果全部項集都存那這個儲存開銷太大了,目前沒有很好的優化思路,時間有限也沒有進一步深入怎麼優化這一步了。
對於候選集生成方法generateCandidates的具體實現,我們首先拆分上一輪頻繁項集preFreSets中的每個項再合併成一個元素集,相當於一個詞彙表,然後遍歷preFreSets中每個項,如果該項中不包含元素表中的某個元素,則將該元素與該項合併成一個候選項。具體實現如下:
def generateCandidates(preFreSets : Array[HashSet[String]], curRound: Int): Array[HashSet[String]] = { // 複雜度:len(elements) * len(preFrestats)^2 * curRound^2 val elements = preFreSets.reduce((a,b) => a.union(b)) val canSets = preFreSets.flatMap( t => for (ele <- elements if(!t.contains(ele))) yield t.+(ele) ).distinct canSets.filter( set => { val iter = set.subsets(curRound - 1) var flag = true while (iter.hasNext && flag){ flag = preFreSets.contains(iter.next()) } flag }) }但是這個過程複雜度太高:len(elements) * len(preFrestats)^2 * curRound^2,當資料來源中元素過多,迭代更深以後,這個複雜度將變得讓人難以接受,花了大量的時間再前一輪的候選項集中驗證候選項,需要想一個辦法來避免順序式的查表,但限於時間有限,這個地方沒有深入展開研究怎麼優化。
2.4 關聯規則的實現
利用當前這一輪迭代生成的頻繁項集curFreqSet來計算關聯規則,利用curFreqSet建立頻繁項索引freqSetIndex,同統計候選項頻度的原因一樣,我們需要將freqSetIndex廣播到各個partition以統計規則A->B左項A的頻度,再利用freqSetIndex索引AB頻繁項的頻度即可計算規則A->B的置信度,然後與設定的置信度對比即可篩選出需要的關聯規則,程式碼實現如下:
// 生成關聯規則 val asst1 = System.nanoTime() // 建立頻繁round-Itemsets的索引Map val freqSetIndex = HashMap[HashSet[String], Int]() curFreqSet.collect().foreach(fs => freqSetIndex.put(fs._1, fs._2)) // 將頻繁round-Itemsets的索引Map廣播到各個partition val broadcastCurFreqSet = sc.broadcast(freqSetIndex) // 生成所有可能的關聯規則,然後篩選出置信度>=confidence的關聯規則 val associationRules = transations .flatMap(x => verifyRules(x, broadcastCurFreqSet.value.keys.toArray, round)) .reduceByKey(_ + _) .map(x => ((x._1._1, x._1._2), broadcastCurFreqSet.value.get(x._1._1.union(x._1._2)).getOrElse(0) * 1.0 / x._2)) .filter(x => x._2 >= confidence)對於規則構造verifyRules的具體實現,我們通過遍歷規則左項的長度來構造,具體實現如下:
def verifyRules(transaction: HashSet[String], candidates: Array[HashSet[String]], curRound: Int): Array[((HashSet[String], HashSet[String]), Int)] = { // yield會根據第一個迴圈型別返回對應的型別,這裡的candidates是Array,因此返回的也是Array型別 for { set <- candidates i <- 1 until curRound iter = set.subsets(i) l <- iter if (l.subsetOf(transaction)) r = set.diff(l) } yield ((l, r), 1) }
三、實驗環境、執行方式及結果
3.1 環境
spark分散式環境的安裝
在本地配置好java,scala,hadoop(Spark會用到hadoop的hdfs)
版本: jdk 1.8.0_161, scala 2.11.8, hadoop 2.7.5在spark官網下載spark-2.3.0-bin-hadoop2.7,解壓安裝
tar -zxvf spark-2.3.0-bin-hadoop2.7 -C ~/bigdata/spark- 配置環境變數,並使環境變數生效
$ vim ~/.bashrc
# Spark Environment Variables
export JAVA_HOME=~/bigdata/java/jdk1.8.0_161
export JRE_HOME=${JAVA_HOME}/jre
export SCALA_HOME=~/bigdata/scala/scala-2.11.8
export HADOOP_HOME=~/bigdata/hadoop/hadoop-2.7.5
export SPARK_HOME=~/bigdata/spark/spark-2.3.0-bin-hadoop2.7
export CLASS_PATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:${SCALA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH
$ source /etc/profile- 配置,spark的配置檔案位於$SPARK_HOME/conf目錄下,需要修改的檔案有spark-env.sh, spark-defaluts.conf和slaves。
$ cd ~/bigdata/spark/spark-2.3.0-bin-hadoop2.7/conf
$ cp spark-env.sh.template spark-env.sh
$ vim spark-env,sh
# spark-env.sh configuration
export JAVA_HOME=~/bigdata/java/jdk1.8.0_161
export SCALA_HOME=~/bigdata/scala/scala-2.11.8
export SPARK_HOME=~/bigdata/spark/spark-2.3.0-bin-hadoop2.7
export HADOOP_HOME=~/bigdata/hadoop/hadoop-2.7.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$HADOOP_HOME/bin
export SPARK_MASTER_IP=slave103
$ cp spark-defaluts.conf.template spark-defaults.conf
$ vim saprk-defaults.conf
# spark-defaults.conf configuration
spark.executor.extraJavaOptions -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
spark.eventLog.enabled true
spark.eventLog.dir hdfs://slave103:9000/spark_event
spark.yarn.historyServer.address slave103:18080
spark.history.fs.logDirectory hdfs://slave103:9000/history_log
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.memory 2g
spark.executor.cores 2
spark.driver.memory 2g
spark.driver.cores 2
spark.yarn.am.memory 2g
spark.yarn.am.cores 2
spark.local.dir /tmp/sparklocaldir
spark.yarn.jars hdfs://slave103:9000/spark/jars/*
$ cp slaves.template slaves
$ vim slaves
# slaves configuration(主機名在/etc/hosts中配置)
slave101
slave103- 啟動和停止
# 啟動
$ bash $SPARK_HOME/sbin/start-all.sh
# 停止
$ bash $SPARK_HOME/sbin/stop-all.sh- 啟動hadoop和spark執行jps命令,顯示的程序如下圖3.1和3.2所示:
3.2 jar包執行方式
假設輸入資料檔案為chess.dat,shell下執行方式如下:
spark-submit --class main.scala.Apriori.distributed.Apriori --master spark://slave103:7077 --conf spark.driver.memory=4g --conf spark.executor.cores=2 original-MapReduce-1.0.jar input/apriori/chess.dat output 0.8 20 24 0.9
# jar後面的引數說明:輸入檔案 輸出目錄 支援度 迭代輪數 併發度即partition數目 置信度3.3 結果
- 測試connect.dat資料集生成頻繁項集的執行時間,圖3.3是單機版的,圖3.4是並行版的:
.png)
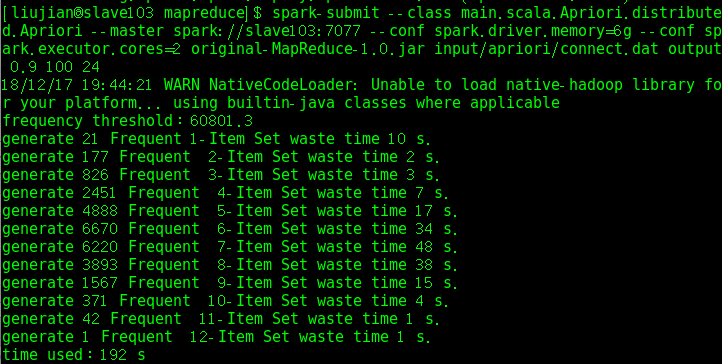
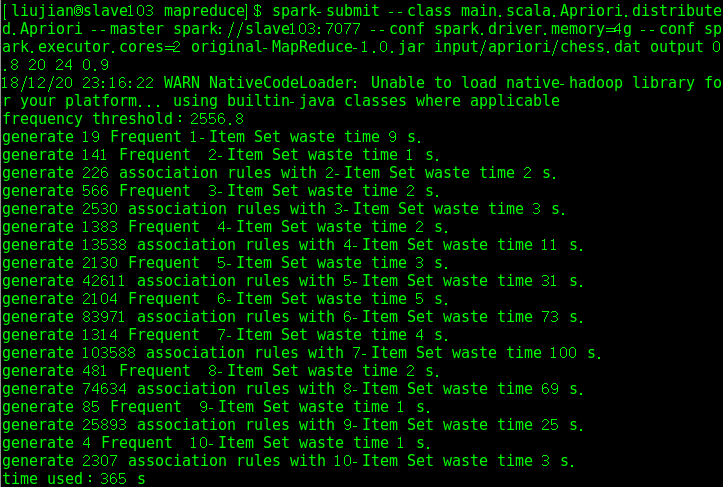
在chess.dat資料集上測試並行版本的頻繁項集生成和關聯規則挖掘的執行時間如下:
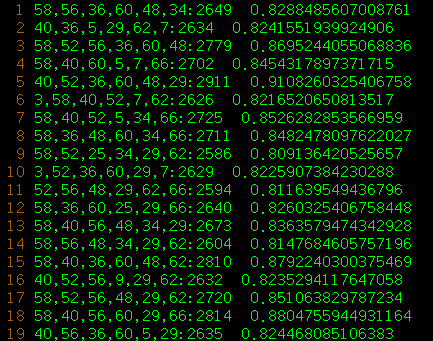
chess.dat頻繁項集生成結果
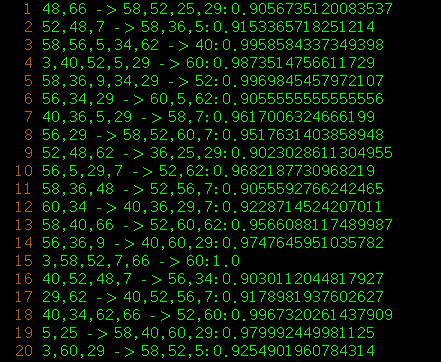
- chess.dat關聯規則挖掘結果
四、WebUI執行報告