
天天聊爬蟲,今天我們來聊聊反爬

反爬蟲的幾重措施
1.IP限制
如果是個人編寫的爬蟲,IP可能是固定的,那麼發現某個IP請求過於頻繁並且短時間內訪問大量的頁面,有爬蟲的嫌疑,作為網站的管理或者運維人員,你可能就得想辦法禁止這個IP地址訪問你的網頁了。那麼也就是說這個IP發出的請求在短時間內不能再訪問你的網頁了,也就暫時擋住了爬蟲。
學習Python中有不明白推薦加入交流裙
號:735934841
群裡有志同道合的小夥伴,互幫互助,
群裡有免費的視訊學習教程和PDF!
2.User-Agent
User-Agent是使用者訪問網站時候的瀏覽器的標識
下面我列出了常見的幾種正常的系統的User-Agent大家可以參考一下,
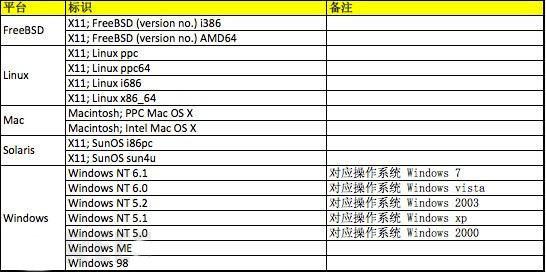
並且在實際發生的時候,根據瀏覽器的不同,還有各種其他的User-Agent,我舉幾個例子方便大家理解:
safari 5.1 – MAC
User-Agent:Mozilla/5.0 (Macintosh; U; IntelMac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1Safari/534.50
Firefox 4.0.1 – MAC
User-Agent: Mozilla/5.0 (Macintosh; IntelMac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1
Firefox 4.0.1 – Windows
User-Agent:Mozilla/5.0 (Windows NT 6.1;rv:2.0.1) Gecko/20100101 Firefox/4.0.1
同樣的也有很多的合法的User-Agent,只要使用者訪問不是正常的User-Agent極有可能是爬蟲再訪問,這樣你就可以針對使用者的User-Agent進行限制了。
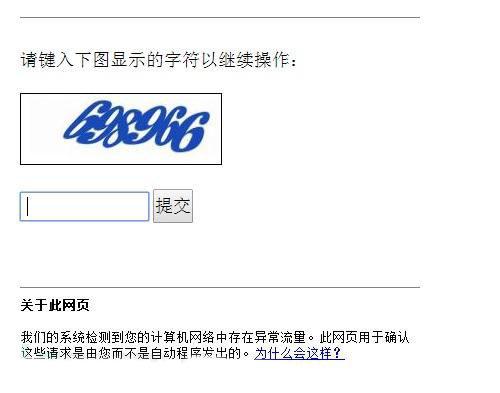
3、 驗證碼反爬蟲
這個辦法也是相當古老並且相當的有效果,如果一個爬蟲要解釋一個驗證碼中的內容,這在以前通過簡單的影象識別是可以完成的,但是就現在來講,驗證碼的干擾線,噪點都很多,甚至還出現了人類都難以認識的驗證碼(某二三零六)。

4.Ajax非同步載入
5.Noscript標籤的使用
<noscript>標籤是在瀏覽器(或者使用者瀏覽標識),沒有啟動指令碼支援的情況下觸發的標籤,在低階爬蟲中,基本都沒有配置js引擎,通常這種方式和Ajax非同步載入同時使用。用於保護自己不想讓爬蟲接觸的資訊。
6.Cookie限制
第一次開啟網頁會生成一個隨機cookie,如果再次開啟網頁這個cookie不存在,那麼再次設定,第三次開啟仍然不存在,這就非常有可能是爬蟲在工作了。很簡單,在三番屢次沒有帶有該帶的cookie,就禁止訪問。
爬蟲編寫注意事項
在這一部分,筆者希望就自己的經驗給大家編寫爬蟲提供比較可行的建議,也為大家提一個醒:
1.道德問題,是否遵守robots協議;
2.小心不要出現卡死在死迴圈中,儘量使用urlparser去解析分離url決定如何處理,如果簡單的想當然的分析url很容易出現死迴圈的問題;
3.單頁面響應超時設定,預設是200秒,建議調短,在網路允許的條件下,找到一個平衡點,避免所有的爬蟲執行緒都在等待200,結果出現效率降低;
4.高效準確的判重模式,如果判重出現問題,就會造成訪問大量已經訪問過的頁面浪費時間;
5.可以採用先下載,後分析的方法,加快爬蟲速度;
6.在非同步程式設計的時候要注意資源死鎖問題;
7.定位元素要精準(xpath)儘量避免dirty data。