
機器學習中的常用超引數
steps:訓練迭代的總次數。一步計算一批樣本產生的損失,然後使用該值修改一次模型的權重。
batch size:單步的樣本數量(隨機選擇)。例如,SGD 的批次大小為 1。
以下公式成立:
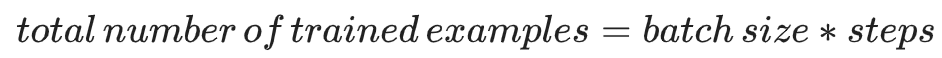
periods:控制報告的粒度。例如,如果 periods 設為 7 且 steps 設為 70,則練習將每 10 步輸出一次損失值(即 7 次)。與超引數不同,我們不希望您修改 periods 的值。請注意,修改 periods 不會更改模型所學習的規律。
以下公式成立: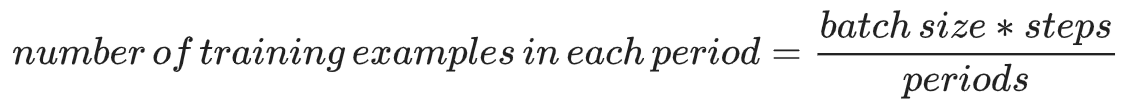
相關推薦
機器學習中常用的矩陣向量求導公式
學習機器學習的時候有很的線性代數的知識,其中有一些矩陣向量求導的東西不是很熟悉,今天查了很久覺得做一個總結。 定義1.梯度(Gradient) [標量對列向量微分] 設是一個變數為的標量函式,其中。那麼定義對的梯度為: 定義2. 海森矩
機器學習中常用損失函式
1. 損失函式 損失函式(Loss function)是用來估量你模型的預測值 f(x)f(x)值。 2. 常用損失函式 常見的損失誤差有五種: 1. 鉸鏈損失(Hinge Loss):主要用於支援向量機(SVM) 中
機器學習中的超平面理解(SVM開篇之超平面詳解)
目錄 一、什麼是超平面 二、點到超平面的距離 三、 判斷超平面的正反 一、什麼是超平面 以上是三維為例子。 通過查閱資料對超平面有了一定的認識, n 維空間中的超平面由下面的方程確定: 其中,w&nb
機器學習中常用演算法總結
參考:http://www.shuju.net/article/MDAwMDAyM4DM0.html 在垃圾郵件分類器專案中,隨機森林被用作最終的分類器模型。面試官可能會就此提出以下問題:為什麼選擇隨機森林而非其他模型,比如樸素貝葉斯或者支援向量機。一般來說,面試者可以從數
機器學習中的超平面
一、仿射空間 (1)直線——1維仿射空間 給定n維的空間中,一條直線是方向向量v以及直線上的一點P決定。如下圖所示: 圖1:line figure illustration 因此直線方程如下所示,其中i表示直線上任一點,t表示標量。
機器學習中常用的資料集處理方法
1.離散值的處理: 因為離散值的差值是沒有實際意義的。比如如果用0,1,2代表紅黃藍,1-0的差值代表黃-紅,是沒有意義的。因此,我們往往會把擁有d個取值的離散值變為d個取值為0,1的離散值或者將其對映為多維向量。 2.屬性歸一化: 歸一化的目標是把各位屬
機器學習中常用的傳遞函式總結
傳遞函式是在神經網路中用到的,在這裡先列舉一下: 函式名稱 對映關係 影象 縮寫 說明 階梯函式 a=0,n<=0 a=1,n>0 Step n大於等 於0時, 輸出1, 否則輸
機器學習中常用到的知識點總結
寫在前面的話 都是什麼鬼,為什麼學校的洗手液和老闆用的沐浴乳是一個味道的,我現在在敲程式碼,整個手上都瀰漫著一股老闆的味道,深深的恐懼感油然而生 1.基本概念 監督學習(supervised learning) 分類問題 資料是有標籤的 無監督
機器學習中常用的Numpy函式
1、numpy.nonzeros() 返回非0元素的索引 如果是二維矩陣的話,返回兩個陣列。第一個陣列包含矩陣非0元素按從左到右從上到下在行上的索引,第二個陣列包含矩陣非0元素按從左到右從上到下在列上的索引 2、numpy.flatten() 返回矩
機器學習中的常用超引數
steps:訓練迭代的總次數。一步計算一批樣本產生的損失,然後使用該值修改一次模型的權重。 batch size:單步的樣本數量(隨機選擇)。例如,SGD 的批次大小為 1。 以下公式成立: peri
關於機器學習中的一些常用方法的補充
機器學習 k近鄰 apriori pagerank前言 機器學習相關算法數量龐大,很難一一窮盡,網上有好事之人也評選了相關所謂十大算法(可能排名不分先後),它們分別是: 1. 決策樹2. 隨機森林算法3. 邏輯回歸4. 支持向量機5. 樸素貝葉斯6
機器學習中的常用操作
機器學習中的常用操作 輸入節點到隱藏節點,特徵數量n可能會變化,這個取決於我們定義的隱藏層的節點個數,但是樣本數量m是不變的,從隱藏層出來還是m 在預測的時候,我們需要不斷的迭代輸入的特徵 提高精度 增加樣本數量 增加特徵 根據現有的特徵生成多項式(從\(x_1\
機器學習中 遠端終端模擬器 Xshell的使用,及一些常用的命令
在上一篇部落格中,我已經介紹瞭如何利用Pycharm 將我們的程式碼上傳至遠端伺服器上,在本篇部落格中,我將進一步介紹,如何使用終端模擬器Xshell 在自己的電腦上執行伺服器上的程式碼。Step 1 Xshell的下載及安裝在這裡我推薦安裝學生版的Xshell
【ML學習筆記】5:機器學習中的數學基礎5(張量,哈達瑪積,生成子空間,超平面,範數)
向量/矩陣/張量 向量 向量可以表示成一維陣列,每個分量可以理解為向量所表示的點在空間中座標的分量。 矩陣 矩陣可以表示成二維陣列,上節理解了矩陣可以理解為線性對映在特定基下的一種定量描述。 張量 張量可以表示成任意維的陣列,張量是向量概
機器學習中三類引數估計的方法
本文主要介紹三類引數估計方法-最大似然估計MLE、最大後驗概率估計MAP及貝葉斯估計。 1、最大似然估計MLE 首先回顧一下貝葉斯公式 這個公式也稱為逆概率公式,可以將後驗概率轉化為基於似然函式和先驗概率的計算表示式,即 最大似然估計就是要用似然
機器學習中的範數規則化之(一)L0、L1與L2範數、核範數與規則項引數選擇
今天我們聊聊機器學習中出現的非常頻繁的問題:過擬合與規則化。我們先簡單的來理解下常用的L0、L1、L2和核範數規則化。最後聊下規則化項引數的選擇問題。這裡因為篇幅比較龐大,為了不嚇到大家,我將這個五個部分分成兩篇博文。知識有限,以下都是我一些淺顯的看法,如果理解存在錯誤,希
機器學習中的回歸理解
機器學習中的線性模型理解機器學習中的類別均衡問題?分為類別平衡問題和類別不平衡問題類別平衡問題:可以采用回歸類別不平衡問題:可以采用在縮放針對類別的回歸問題有線性回歸:非線性回本文出自 “簡答生活” 博客,謝絕轉載!機器學習中的回歸理解
機器學習中的範數規則化之(一)L0、L1與L2範數
[0 證明 基本上 復雜度 所有 img 方法 風險 機器學習 機器學習中的範數規則化之(一)L0、L1與L2範數 [email protected]/* */ http://blog.csdn.net/zouxy09 轉自:http://blog.csdn.n
專家坐堂:機器學習中對核函數的理解
wechat size 學習 blank weixin itl cti title redirect 專家坐堂:機器學習中對核函數的理解 專家坐堂:機器學習中對核函數的理解
機器學習中防止過擬合方法
從數據 tro 輸出 效果 沒有 imagenet neu 效率 公式 過擬合 ??在進行數據挖掘或者機器學習模型建立的時候,因為在統計學習中,假設數據滿足獨立同分布,即當前已產生的數據可以對未來的數據進行推測與模擬,因此都是使用歷史數據建立模型,即使用已經產生的數據去訓練