
Softmax Regression簡介
阿新 • • 發佈:2018-12-22
Softmax Regression簡介
處理多分類任務時,通常使用Softmax Regression模型。
在神經網路中,如果問題是分類模型(即使是CNN或者RNN),一般最後一層是Softmax Regression。
它的工作原理是將可以判定為某類的特徵相加,然後將這些特徵轉化為判定是這一類的概率。
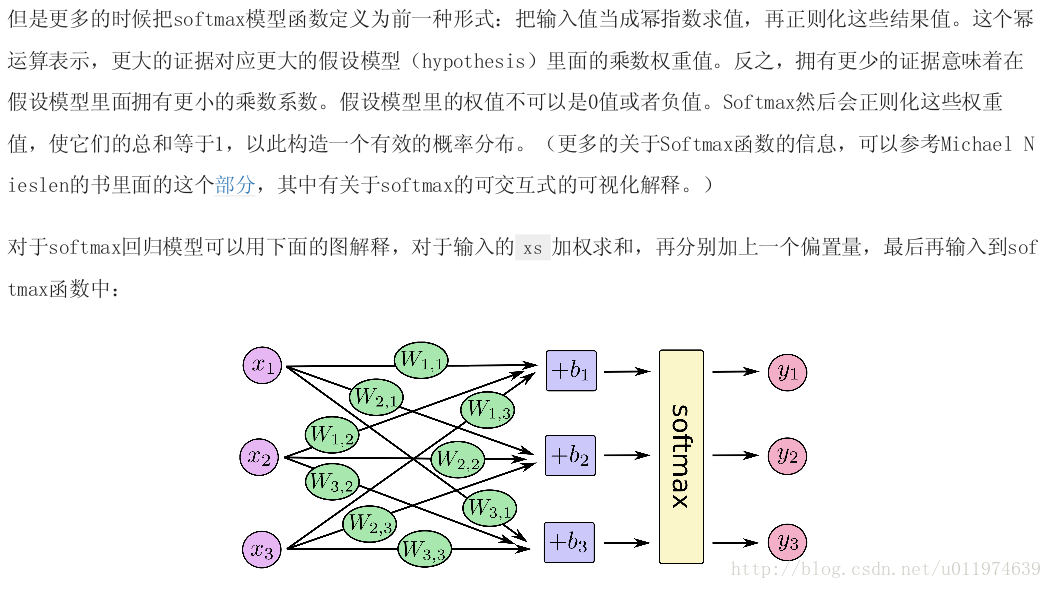
實現Softmax Regression
建立一個神經網路模型步驟如下:
- 定義網路結構(即網路前向演算法)
- 定義loss function,確定Optimizer
- 迭代訓練
- 在測試集/驗證集上測評
1. 定義網路結構
import tensorflow as tf sess = tf.InteractiveSession() #註冊預設Session #輸入資料佔位符,None代表輸入條數不限制(取決訓練的batch_size) x = tf.placeholder("float", [None, 784]) W = tf.Variable(tf.zeros([784,10])) #權重張量,weights無隱藏層 b = tf.Variable(tf.zeros([10])) #偏置biases #實現softmax Regression y=softmax(Wx+b) y = tf.nn.softmax(tf.matmul(x,W) + b)
2. 定義loss function,確定Optimizer
#y_為標籤值 y_ = tf.placeholder("float", [None,10]) #交叉熵損失函式定義 cross_entropy = -tf.reduce_mean(tf.reduce_sum(y_*tf.log(y))) #學習率定義 learn_rate = 0.001 #優化器選擇 train_step = tf.train.GradientDescentOptimizer(learn_rate).minimize(cross_entropy)
3. 迭代訓練
with Session() as sess: #初始化所有變數 init_op = tf.global_variables_initializer() sess.run(init_op) #迭代次數 STEPS = 1000 for i in range(STEPS): #使用mnist.train.next_batch隨機選取batch batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
4. 在測試集/驗證集上測評
#tf.argmax函式可以在一個張量裡沿著某條軸的最高條目的索引值
#tf.argmax(y,1) 是模型認為每個輸入最有可能對應的那些標籤
#而 tf.argmax(y_,1) 代表正確的標籤
#我們可以用 tf.equal 來檢測我們的預測是否真實標籤匹配
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
#這行程式碼會給我們一組布林值。
#為了確定正確預測項的比例,我們可以把布林值轉換成浮點數,然後取平均值。例如, [True, False, True, True] 會變成 [1,0,1,1] ,取平均值後得到 0.75
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#我們計算所學習到的模型在測試資料集上面的正確率
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})下面給出一個完整的TensorFlow訓練神經網路
這裡會用到啟用函式去線性化,使用更深層網路,使用帶指數衰減的學習率設定,同時使用正則化避免過擬合,以及使用滑動平均模型來使最終模型更加健壯。
# coding=utf-8
# 在MNIST 資料集上實現神經網路
# 包含一個隱層
# 5種優化方案:啟用函式,多層隱層,指數衰減的學習率,正則化損失,滑動平均模型
import tensorflow as tf
import tensorflow.contrib.layers as tflayers
from tensorflow.examples.tutorials.mnist import input_data
#MNIST資料集相關引數
INPUT_NODE = 784 #輸入節點數
OUTPUT_NODE = 10 #輸出節點數
LAYER1_NODE = 500 #選擇一個隱藏層,節點數為500
BATCH_SIZE = 100 #一個batch大小
'''
指數衰減學習率
函式定義exponential_decay(learning_rate, global_step, decay_steps, decay_rate, staircase=False, name=None):
計算公式:decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
learning_rate = LEARNING_RATE_BASE;
decay_rate = LEARNING_RATE_DECAY
global_step=TRAINING_STEPS;
decay_steps = mnist.train.num_examples/batch_size
'''
LEARNING_RATE_BASE = 0.8 # 基礎的學習率,使用指數衰減設定學習率
LEARNING_RATE_DECAY = 0.99 # 學習率的初始衰減率
# 正則化損失的係數
LAMADA = 0.0001
# 訓練輪數
TRAINING_STEPS = 30000
# 滑動平均衰減率
MOVING_AVERAGE_DECAY = 0.99
def get_weight(shape, llamada):
'''
function:生成權重變數,並加入L2正則化損失到losses集合裡
:param shape: 權重張量維度
:param llamada: 正則引數
:return: 權重張量(所有權重都新增在losses集合中,簡化計算loss操作)
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
從截斷的正態分佈中輸出隨機值
生成的值服從具有指定平均值和標準偏差的正態分佈,如果生成的值大於平均值2個標準偏差的值則丟棄重新選擇。
:shape: 一維的張量,也是輸出的張量
:mean: 正態分佈的均值。
:stddev: 正態分佈的標準差。
:dtype: 輸出的型別。
:seed: 一個整數,當設定之後,每次生成的隨機數都一樣。
:name: 操作的名字。
'''
weights = tf.Variable(tf.truncated_normal(shape, stddev=0.1))
if llamada != None:
tf.add_to_collection('losses', tflayers.l2_regularizer(llamada)(weights))
return weights
def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2):
'''
對神經網路進行前向計算,如果avg_class為空計算普通的前向傳播,否則計算包含滑動平均的前向傳播
使用了RELU啟用函式實現了去線性化
:param input_tensor: 輸入張量
:param avg_class: 平均滑動類
:param weights1: 一級層權重
:param biases1: 一級層偏置
:param weights2: 二級層權重
:param biases2: 二級層權重
:return: 前向傳播的計算結果(預設隱藏層一層,所以輸出層沒有ReLU)
計算輸出層的前向傳播結果。
因為在計算損失函式的時候會一併計算softmax函式,因此這裡不加入softmax函式
同時,這裡不加入softmax層不會影響最後的結果。
因為,預測時使用的是不同類別對應節點輸出值的相對大小,因此有無softmax層對最後的結果沒有影響。
'''
if avg_class == None:
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
return tf.matmul(layer1, weights2) + biases2
else:
# 首先需要使用avg_class.average函式計算變數的滑動平均值,然後再計算相應的神經網路前向傳播結果
layer1 = tf.nn.relu(
tf.matmul(input_tensor, avg_class.average(weights1)) + avg_class.average(biases1))
return tf.matmul(layer1, avg_class.average(weights2)) + avg_class.average(biases2)
# 訓練模型的過程
def train(mnist):
'''
訓練函式過程:
1.定義網路結構,計算前向傳播結果
2.定義loss和優化器
3.迭代訓練
4.評估訓練模型
:param mnist: 資料集合
:return:
'''
x = tf.placeholder(tf.float32, shape=(None, INPUT_NODE), name='x_input')
y_ = tf.placeholder(tf.float32, shape=(None, OUTPUT_NODE), name='y_input')
# 生成隱藏層(使用get_weight帶L2正則化)
weights1 = get_weight([INPUT_NODE, LAYER1_NODE], LAMADA)
biaes1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
# 生成輸出層的引數
weights2 = get_weight([LAYER1_NODE, OUTPUT_NODE], LAMADA)
biaes2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
# 計算神經網路的前向傳播結果,注意滑動平均的類函式為None
y = inference(x, None, weights1, biaes1, weights2, biaes2)
# 定義儲存模型訓練輪數的變數,並指明為不可訓練的引數
global_step = tf.Variable(0, trainable=False)
'''
使用平均滑動模型
1.初始化滑動平均的函式類,加入訓練輪數的變數可以加快需年早期變數的更新速度
2.對神經網路裡所有可訓練引數(列表)應用滑動平均模型,每次進行這個操作,列表裡的元素都會得到更新
3.計算使用了滑動平均的網路前向傳播結果,滑動是維護影子變數來記錄其滑動平均值,需要使用時要明確呼叫average函式
'''
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
average_y = inference(x, variable_averages, weights1, biaes1, weights2, biaes2)
'''
定義loss
當只有一個標準答案的時候,使用sprase_softmax_cross_entropy_with_logits計算損失,可以加速計算
引數:不包含softma層的前向傳播結果,訓練資料的正確答案
因為標準答案是一個長度為10的一維陣列,而該函式需要提供一個正確答案的數字
因此需要使用tf.argmax函式得到正確答案的對應類別編號
'''
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
# 計算在當前batch裡所有樣例的交叉熵平均值,並加入損失集合
cross_entropy_mean = tf.reduce_mean(cross_entropy)
tf.add_to_collection('losses', cross_entropy_mean)
# get_collection返回一個列表,列表是所有這個集合的所有元素(在本例中,元素代表了其他部分的損失,加起來就得到了所有的損失)
loss = tf.add_n(tf.get_collection('losses'))
'''
設定指數衰減的學習率
使用GradientDescentOptimizer()優化演算法的損失函式
'''
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, # 基礎的學習率,在此基礎上進行遞減
global_step, # 迭代的輪數
mnist.train.num_examples / BATCH_SIZE, # 所有的資料得到訓練所需要的輪數
LEARNING_RATE_DECAY) # 學習率衰減速度
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
'''
在訓練神經網路模型的時候,每過一次資料既需要BP更新引數又要更新引數的滑動平均值。
為了一次完成多種操作,tensroflow提供了兩種機制:tf.control_dependencies和tf.group
下面的兩行程式和:train_op = tf.group(train_step,variables_average_op)等價
tf.group(*inputs, **kwargs )
Create an op that groups multiple operations.
When this op finishes, all ops in input have finished. This op has no output.
control_dependencies(control_inputs)
Use with the with keyword to specify that all operations constructed within
the context should have control dependencies on control_inputs.
For example:
with g.control_dependencies([a, b, c]):
# `d` and `e` will only run after `a`, `b`, and `c` have executed.
d = ...
e = ...
'''
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
'''
進行驗證集上的準確率計算,這時需要使用滑動平均模型
判斷兩個張量的每一維是否相等,如果相等就返回True,否則返回False
這個運算先將布林型的數值轉為實數型,然後計算平均值,平均值就是準確率
'''
correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
# init_op = tf.global_variables_initializer() sess.run(init_op) 這種寫法視覺化更加清晰
tf.global_variables_initializer().run()
# 準備驗證資料,一般在神經網路的訓練過程中會通過驗證資料來判斷大致停止的條件和評判訓練的效果
validate_feed = {x: mnist.validation.images, y_: mnist.validation.labels}
# 準備測試資料,在實際中,這部分資料在訓練時是不可見的,這個資料只是作為模型優劣的最後評價標準
test_feed = {x: mnist.test.images, y_: mnist.test.labels}
# 迭代的訓練神經網路
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
if i % 1000 == 0:
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
validate_acc = sess.run(accuracy, feed_dict=validate_feed)
print "After %d training step(s),validation accuracy using average model is %g " % (step, validate_acc)
test_acc = sess.run(accuracy, feed_dict=test_feed)
print("After %d training step(s) testing accuracy using average model is %g" % (step, test_acc))
#TensorFlow主程式入口
def main(argv=None):
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
train(mnist)
#TensorFlow提供了一個主程式入口,tf.app.run會呼叫上面定義的main函式
if __name__ == '__main__':
tf.app.run()輸出
After 1 training step(s), loss on training batch is 3.30849.
After 1 training step(s),validation accuracy using average model is 0.1098
After 1 training step(s) testing accuracy using average model is 0.1132
After 1001 training step(s), loss on training batch is 0.19373.
After 1001 training step(s),validation accuracy using average model is 0.9772
After 1001 training step(s) testing accuracy using average model is 0.9738
After 2001 training step(s), loss on training batch is 0.169665.
After 2001 training step(s),validation accuracy using average model is 0.9794
After 2001 training step(s) testing accuracy using average model is 0.9796
After 3001 training step(s), loss on training batch is 0.147636.
After 3001 training step(s),validation accuracy using average model is 0.9818
After 3001 training step(s) testing accuracy using average model is 0.9813
After 4001 training step(s), loss on training batch is 0.129015.
After 4001 training step(s),validation accuracy using average model is 0.9808
After 4001 training step(s) testing accuracy using average model is 0.9825
After 5001 training step(s), loss on training batch is 0.109033.
After 5001 training step(s),validation accuracy using average model is 0.982
After 5001 training step(s) testing accuracy using average model is 0.982
After 6001 training step(s), loss on training batch is 0.108935.
After 6001 training step(s),validation accuracy using average model is 0.9818
After 6001 training step(s) testing accuracy using average model is 0.982
.......
.......
.......
After 27001 training step(s), loss on training batch is 0.0393247.
After 27001 training step(s),validation accuracy using average model is 0.9828
After 27001 training step(s) testing accuracy using average model is 0.9827
After 28001 training step(s), loss on training batch is 0.0422536.
After 28001 training step(s),validation accuracy using average model is 0.984
After 28001 training step(s) testing accuracy using average model is 0.9822
After 29001 training step(s), loss on training batch is 0.0512684.
After 29001 training step(s),validation accuracy using average model is 0.9832
After 29001 training step(s) testing accuracy using average model is 0.9831
判斷模型效果
tensorflow實戰