
【天池學習】模型融合概述
在比賽中提高成績主要有3個地方
- 特徵工程
- 調參
- 模型融合
1. Voting
模型融合其實也沒有想象的那麼高大上,從最簡單的Voting說起,這也可以說是一種模型融合。假設對於一個二分類問題,有3個基礎模型,那麼就採取投票制的方法,投票多者確定為最終的分類。
2.Averaging
對於迴歸問題,一個簡單直接的思路是取平均。稍稍改進的方法是進行加權平均。權值可以用排序的方法確定,舉個例子,比如A、B、C三種基本模型,模型效果進行排名,假設排名分別是1,2,3,那麼給這三個模型賦予的權值分別是3/6、2/6、1/6 這兩種方法看似簡單,其實後面的高階演算法也可以說是基於此而產生的,Bagging或者Boosting都是一種把許多弱分類器這樣融合成強分類器的思想。
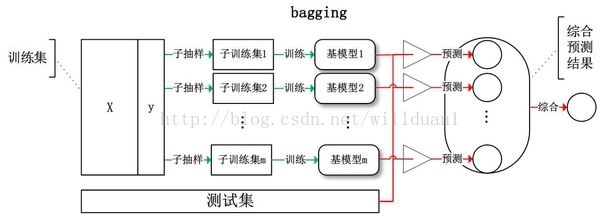
3. Bagging
Bagging就是採用有放回的方式進行抽樣,用抽樣的樣本建立子模型,對子模型進行訓練,這個過程重複多次,最後進行融合。大概分為這樣兩步:
-
重複K次
有放回地重複抽樣建模
訓練子模型 -
模型融合
分類問題:voting
迴歸問題:average
Bagging演算法不用我們自己實現,隨機森林就是基於Bagging演算法的一個典型例子,採用的基分類器是決策樹。R和python都整合好了,直接呼叫。
4. Boosting
Bagging演算法可以並行處理,而Boosting的思想是一種迭代的方法,每一次訓練的時候都更加關心分類錯誤的樣例,給這些分類錯誤的樣例增加更大的權重,下一次迭代的目標就是能夠更容易辨別出上一輪分類錯誤的樣例。最終將這些弱分類器進行加權相加。引用加州大學歐文分校Alex Ihler教授的兩頁PPT


同樣地,基於Boosting思想的有AdaBoost、GBDT等,在R和python也都是整合好了直接呼叫。
PS:理解了這兩點,面試的時候關於Bagging、Boosting的區別就可以說上來一些,問Randomfroest和AdaBoost的區別也可以從這方面入手回答。也算是留一個小問題,隨機森林、Adaboost、GBDT、XGBoost的區別是什麼?
5. Stacking
Stacking方法其實弄懂之後應該是比Boosting要簡單的,畢竟小几十行程式碼可以寫出一個Stacking演算法。我先從一種“錯誤”但是容易懂的Stacking方法講起。
Stacking模型本質上是一種分層的結構,這裡簡單起見,只分析二級Stacking.假設我們有3個基模型M1、M2、M3。
- 基模型M1,對訓練集train訓練,然後用於預測train和test的標籤列,分別是P1,T1

對於M2和M3,重複相同的工作,這樣也得到P2,T2,P3,T3。
- 分別把P1,P2,P3以及T1,T2,T3合併,得到一個新的訓練集和測試集train2,test2.

- 再用第二層的模型M4訓練train2,預測test2,得到最終的標籤列。

Stacking本質上就是這麼直接的思路,但是這樣肯定是不行的,問題在於P1的得到是有問題的,用整個訓練集訓練的模型反過來去預測訓練集的標籤,毫無疑問過擬合是非常非常嚴重的,因此現在的問題變成了如何在解決過擬合的前提下得到P1、P2、P3,這就變成了熟悉的節奏——K折交叉驗證。我們以2折交叉驗證得到P1為例,假設訓練集為4行3列

將其劃分為2部分

用traina訓練模型M1,然後在trainb上進行預測得到preb3和pred4

在trainb上訓練模型M1,然後在traina上進行預測得到pred1和pred2

然後把兩個預測集進行拼接

對於測試集T1的得到,有兩種方法。注意到剛剛是2折交叉驗證,M1相當於訓練了2次,所以一種方法是每一次訓練M1,可以直接對整個test進行預測,這樣2折交叉驗證後測試集相當於預測了2次,然後對這兩列求平均得到T1。 或者直接對測試集只用M1預測一次直接得到T1。 P1、T1得到之後,P2、T2、P3、T3也就是同樣的方法。理解了2折交叉驗證,對於K折的情況也就理解也就非常順利了。所以最終的程式碼是兩層迴圈,第一層迴圈控制基模型的數目,每一個基模型要這樣去得到P1,T1,第二層迴圈控制的是交叉驗證的次數K,對每一個基模型,會訓練K次最後拼接得到P1,取平均得到T1。

該圖是一個基模型得到P1和T1的過程,採用的是5折交叉驗證,所以迴圈了5次,拼接得到P1,測試集預測了5次,取平均得到T1。而這僅僅只是第二層輸入的一列/一個特徵,並不是整個訓練集。再分析作者的程式碼也就很清楚了。也就是剛剛提到的兩層迴圈。
5.1 stacking方法
將訓練好的所有基模型對整個訓練集進行預測,第j個基模型對第i個訓練樣本的預測值將作為新的訓練集中第i個樣本的第j個特徵值,最後基於新的訓練集進行訓練。同理,預測的過程也要先經過所有基模型的預測形成新的測試集,最後再對測試集進行預測:

下面我們介紹一款功能強大的stacking利器,mlxtend庫,它可以很快地完成對sklearn模型地stacking。
主要有以下幾種使用方法吧:
I. 最基本的使用方法,即使用前面分類器產生的特徵輸出作為最後總的meta-classifier的輸入資料
|
|
output
3-fold cross validation:
Accuracy: 0.91 (+/- 0.01) [KNN]
Accuracy: 0.91 (+/- 0.06) [Random Forest]
Accuracy: 0.92 (+/- 0.03) [Naive Bayes]
Accuracy: 0.95 (+/- 0.03) [StackingClassifier]
II. 另一種使用第一層基本分類器產生的類別概率值作為meta-classfier的輸入,這種情況下需要將StackingClassifier的引數設定為 use_probas=True。如果將引數設定為 average_probas=True,那麼這些基分類器對每一個類別產生的概率值會被平均,否則會拼接。
例如有兩個基分類器產生的概率輸出為:
classifier 1: [0.2, 0.5, 0.3]
classifier 2: [0.3, 0.4, 0.4]
1) average = True :
產生的meta-feature 為:[0.25, 0.45, 0.35]
2) average = False:
產生的meta-feature為:[0.2, 0.5, 0.3, 0.3, 0.4, 0.4]
|
|
output
3-fold cross validation:
Accuracy: 0.91 (+/- 0.01) [KNN]
Accuracy: 0.91 (+/- 0.06) [Random Forest]
Accuracy: 0.92 (+/- 0.03) [Naive Bayes]
Accuracy: 0.94 (+/- 0.03) [StackingClassifier]
III. 另外一種方法是對訓練基中的特徵維度進行操作的,這次不是給每一個基分類器全部的特徵,而是給不同的基分類器分不同的特徵,即比如基分類器1訓練前半部分特徵,基分類器2訓練後半部分特徵(可以通過sklearn 的pipelines 實現)。最終通過StackingClassifier組合起來。
|
|
output
StackingClassifier(average_probas=False,
classifiers=[Pipeline(memory=None,
steps=[('columnselector', ColumnSelector(cols=(0, 2), drop_axis=False)), ('logisticregression', LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
pen...='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))])],
meta_classifier=LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False),
store_train_meta_features=False, use_clones=True,
use_features_in_secondary=False, use_probas=False, verbose=0)StackingClassifier 使用API及引數解析:
StackingClassifier(classifiers, meta_classifier, use_probas=False, average_probas=False, verbose=0, use_features_in_secondary=False)
引數:
classifiers : 基分類器,陣列形式,[cl1, cl2, cl3]. 每個基分類器的屬性被儲存在類屬性 self.clfs_. meta_classifier : 目標分類器,即將前面分類器合起來的分類器
use_probas : bool (default: False) ,如果設定為True, 那麼目標分類器的輸入就是前面分類輸出的類別概率值而不是類別標籤
average_probas : bool (default: False),用來設定上一個引數當使用概率值輸出的時候是否使用平均值。
verbose : int, optional (default=0)。用來控制使用過程中的日誌輸出,當 verbose = 0時,什麼也不輸出, verbose = 1,輸出迴歸器的序號和名字。verbose = 2,輸出詳細的引數資訊。verbose > 2, 自動將verbose設定為小於2的,verbose -2.
use_features_in_secondary : bool (default: False). 如果設定為True,那麼最終的目標分類器就被基分類器產生的資料和最初的資料集同時訓練。如果設定為False,最終的分類器只會使用基分類器產生的資料訓練。
屬性:
clfs_ : 每個基分類器的屬性,list, shape 為 [n_classifiers]。 meta_clf_ : 最終目標分類器的屬性
方法:
fit(X, y)
fit_transform(X, y=None, fit_params)
get_params(deep=True),如果是使用sklearn的 GridSearch方法,那麼返回分類器的各項引數。 predict(X)
predict_proba(X)
score(X, y, sample_weight=None), 對於給定資料集和給定label,返回評價accuracy
set_params(params),設定分類器的引數,params的設定方法和sklearn的格式一樣。
參考連結: