
Coursera機器學習基石筆記week15
Validation
Model Selection Problem

針對模型建立的過程,如上圖所示,不僅需要考慮演算法的選擇,還要考慮迭代次數,學習速率,特徵轉換,正則化,正則化係數的選擇等等,不同的搭配,都有不同的機器學習效果。那麼我們應該如何找一個最合適的搭配呢?
首先我們考慮通過找一個最好 來選擇模型。

但是相對來說, 小的模型總是偏向於使用較大指數的特徵以及儘量小的正則化,但是這又容易導致過擬合。而且假如每一種模型選擇+訓練會使模型複雜度變得比較高,從而使泛化能力變得比較差。
另外一種方法,如果有這樣一個獨立於訓練樣本的測試集,將M個模型在測試集上進行測試,看一下 的大小,則選取 最小的模型作為最佳模型:


但是,我們拿到的都是訓練集D,測試集是拿不到的。所以,尋找一種折中的辦法,我們可以使用已有的訓練集D來創造一個驗證集validation set,即從D中劃出一部分 作為驗證集。D另外的部分作為訓練模型使用, 獨立開來,用來測試各個模型的好壞,最小化 ,從而選擇最佳的 。

Validation
從訓練集D中抽出一部分K個數據作為驗證集 , 對應的error記為 。這樣做的一個前提是保證 獨立同分布(iid)於P(x,y),也就是說 的選擇是從D中平均隨機抽樣得到的,這樣能夠把 與 聯絡起來。D中去除 後的資料就是供模型選擇的訓練資料 ,其大小為N-k。從 中選擇最好的g,記為 。
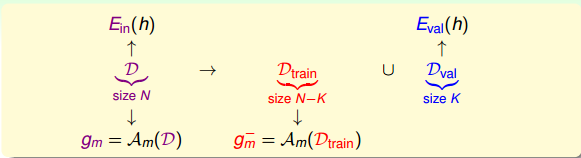
假如D共有1000個樣本,那麼可以選擇其中900個 ,剩下的100個作為 。使用 訓練模型,得到最佳的 ,使用 對 進行驗證,得到如下Hoffding不等式:
假設有M種模型hypothesis set, 的數量為K,那麼從每種模型m中得到一個在 上表現最好的g,再橫向比較,從M個g中選擇一個最好的 作為我們最終得到的模型。
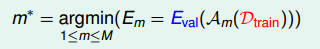
根據之前的leraning curve很容易知道,訓練樣本越多,得到的模型越準確,其hypothesis越接近target function,即D的
比
的
要小.
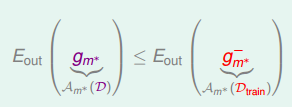
所以,我們通常的做法是通過
來選擇最好的矩
對應的模型
,再對整體樣本集D使用該模型進行訓練,最終得到最好的矩
。
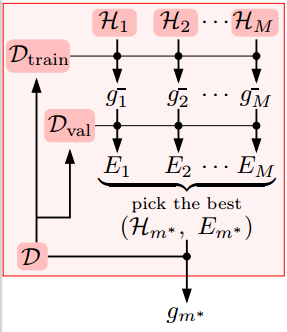
如上圖所示,我們先把資料集分為
,