
Flume資料採集元件
1、資料收集工具/系統產生背景
Hadoop 業務的整體開發流程:
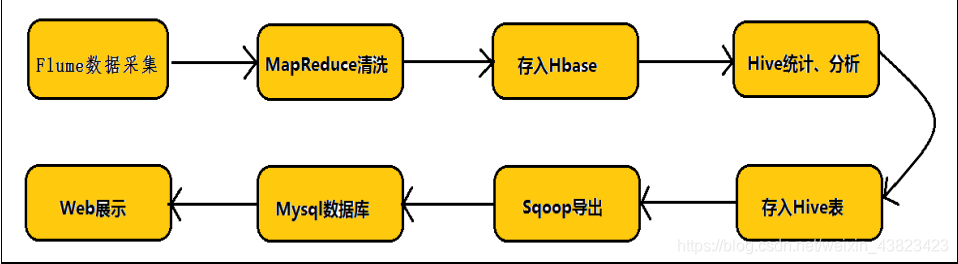
任何完整的大資料平臺,一般都會包括以下的基本處理過程:
總結:
資料的來源大體上包括:
1、業務資料
2、爬蟲爬取的網路公開資料
3、購買資料
4、自行採集手機的日誌資料
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and
moving large amounts of log data. It has a simple and flexible architecture based on streaming data
flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and
recovery mechanisms. It uses a simple extensible data model that allows for online analytic
application.
Flume 是一個分散式、可靠、高可用的海量日誌聚合系統,支援在系統中定製各類資料傳送
方,用於收集資料,同時,Flume 提供對資料的簡單處理,並寫到各種資料接收方的能力。
1、 Apache Flume 是一個分散式、可靠、和高可用的海量日誌採集、聚合和傳輸的系統,和
Sqoop 同屬於資料採集系統元件,但是 Sqoop 用來採集關係型資料庫資料,而 Flume 用
來採集流動型資料。
2、 Flume 名字來源於原始的近乎實時的日誌資料採集工具,現在被廣泛用於任何流事件數
據的採集,它支援從很多資料來源聚合資料到 HDFS。
3、 一般的採集需求,通過對 flume 的簡單配置即可實現。Flume 針對特殊場景也具備良好
的自定義擴充套件能力,因此,flume 可以適用於大部分的日常資料採集場景
4、 Flume 最初由 Cloudera 開發,在 2011 年貢獻給了 Apache 基金會,2012 年變成了 Apache
的頂級專案。Flume OG(Original Generation)是 Flume 最初版本,後升級換代成 Flume
NG(Next/New Generation)
5、 Flume 的優勢:可橫向擴充套件、延展性、可靠性
Flume 資料來源和輸出方式
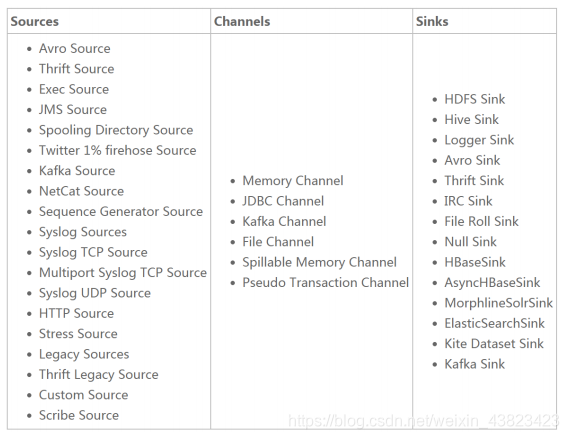
Flume 提供了從 console(控制檯)、RPC(Thrift-RPC)、text(檔案)、tail(UNIX tail)、syslog(syslog 日誌系統,支援 TCP 和 UDP 等 2 種模式),exec(命令執行)等資料來源上收集資料的能力,在我們的系統中目前使用 exec 方式進行日誌採集。
Flume 的資料接受方,可以是 console(控制檯)、text(檔案)、dfs(HDFS 檔案)、RPC(Thrift-RPC)和 syslogTCP(TCP syslog 日誌系統)等。最常用的是 Kafka。
3、Flume 體系結構/核心元件
3.1、概述
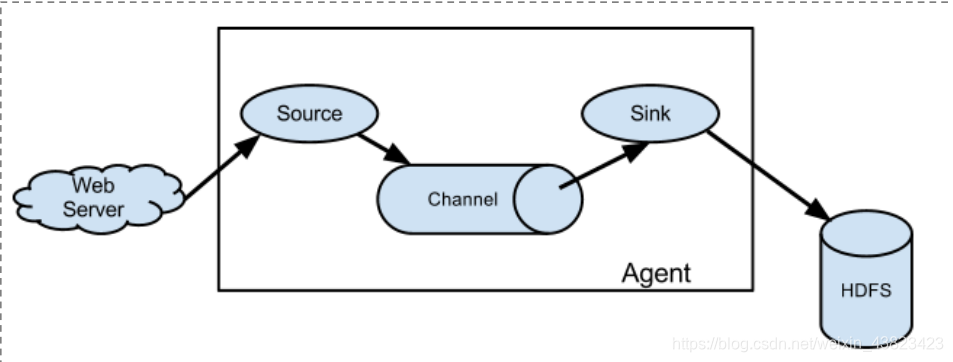
Flume 的資料流由事件(Event)貫穿始終。事件是 Flume 的基本資料單位,它攜帶日誌資料(位元組陣列形式)並且攜帶有頭資訊,這些 Event 由 Agent 外部的 Source 生成,當 Source 捕獲事件後會進行特定的格式化,然後 Source 會把事件推入(單個或多個)Channel 中。你可以把Channel 看作是一個緩衝區,它將儲存事件直到 Sink 處理完該事件。Sink 負責持久化日誌或者把事件推向另一個 Source。
Flume 以 agent 為最小的獨立執行單位。
一個 agent 就是一個 JVM。
單 agent 由 Source、Sink 和 Channel 三大元件構成。
如下圖:
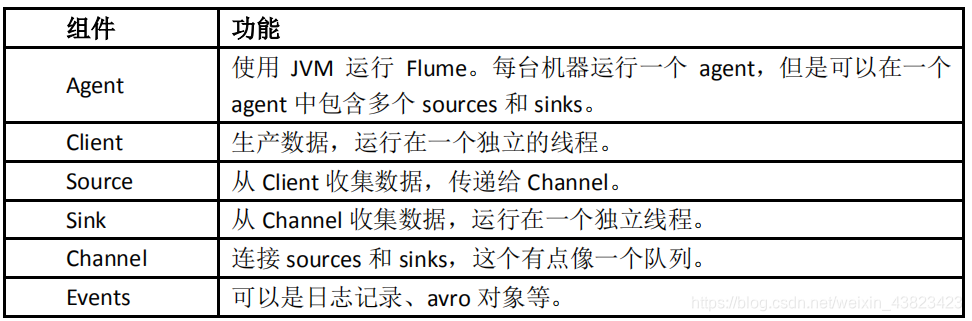
3.2、Flume 三大核心元件
Event
- Event 是 Flume 資料傳輸的基本單元。 Flume 以事件的形式將資料從源頭傳送到最終的目的地。
Event由可選的header 和載有資料的一個 byte array 構成。
元件 功能
Agent
- 使用 JVM 執行 Flume。每臺機器執行一個 agent,但是可以在一個 agent 中包含多個 sources 和 sinks。
Client 生產資料,執行在一個獨立的執行緒。 Source 從 Client 收集資料,傳遞給 Channel。 Sink 從
Channel 收集資料,執行在一個獨立執行緒。 Channel 連線 sources 和 sinks,這個有點像一個佇列。 Events
可以是日誌記錄、avro 物件等。 載有的資料度 flume 是不透明的。 Header 是容納了 key-value
字串對的無序集合,key 在集合內是唯一的。 Header 可以在上下文路由中使用擴充套件
Client
- Client 是一個將原始 log 包裝成 events 並且傳送他們到一個或多個 agent 的實體 目的是從資料來源系統中解耦
Flume 在 Flume 的拓撲結構中不是必須的。 Client 例項 flume log4j Appender 可以使用
Client SDK(org.apache.flume.api)定製特定的 Client
Agent
- 一個 Agent 包含 source,channel,sink 和其他元件。 它利用這些元件將 events
從一個節點傳輸到另一個節點或最終目的地 agent 是 flume 流的基礎部分。 flume
為這些元件提供了配置,宣告週期管理,監控支援。 Source Source 負責接收 event 或通過特殊機制產生 event,並將
events 批量的放到一個或多個 Channel 包含 event 驅動和輪詢兩種型別。 不同型別的 Source 與系統整合的
Source:Syslog,Netcat,監測目錄池 自動生成事件的 Source:Exec 用於 Agent 和 Agent
之間通訊的 IPC source:avro,thrift source 必須至少和一個 channel 關聯
Agent 之 Channel
- Channel 位於 Source 和 Sink 之間,用於快取進來的 event 當 sink 成功的將 event 傳送到下一個的
channel 或最終目的 event 從 channel 刪除 不同的 channel 提供的持久化水平也是不一樣的 Memory
channel:volatile(不穩定的) File Channel:基於 WAL(預寫式日誌 Write-Ahead
logging)實現 JDBC channel:基於嵌入式 database 實現 channel 支援事務,提供較弱的順序保證
可以和任何數量的 source 和 sink 工作
Agent 之 Sink
- Sink 負責將 event 傳輸到嚇一跳或最終目的地,成功後將 event 從 channel 移除 不同型別的 sink 儲存
event 到最終目的地終端 sink,比如 HDFS,HBase 自動消耗的 sink 比如 null sink 用於 agent
間通訊的 IPC:sink:Avro 必須作用於一個確切的 channel
Iterator
- 作用於 Source,按照預設的順序在必要地方裝飾和過濾 events
Channel Selector
- 允許 Source 基於預設的標準,從所有 channel 中,選擇一個或者多個 channel
Sink Processor
- 多個 sink 可以構成一個 sink group sink processor 可以通過組中所有 sink 實現負載均衡 也可以在一個 sink 失敗時轉移到另一個。
4、Flume 實戰案例
4.1、安裝部署 Flume
1、Flume 的安裝非常簡單,只需要解壓即可,當然,前提是已有 Hadoop 環境上傳安裝包到資料來源所在節點上,然後解壓 tar -zxvf apache-flume-1.8.0-bin.tar.gz,然後進入 flume 的目錄,修改 conf 下的 flume-env.sh,在裡面配置 JAVA_HOME
2、根據資料採集的需求配置採集方案,描述在配置檔案中(檔名可任意自定義)
3、指定採集方案配置檔案,在相應的節點上啟動 flume agent先用一個最簡單的例子來測試一下程式環境是否正常
1、在$FLUME_HOME/agentconf 目錄下建立一個數據採集方案,該方案就是從一個網路埠
收集資料,也就是創一個任意命名的配置檔案如下:netcat-logger.properties
檔案內容如下:
# 定義這個 agent 中各個元件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 元件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述和配置 sink 元件:k1
a1.sinks.k1.type = logger
# 描述和配置 channel 元件,此處使用是記憶體快取的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置 source channel sink 之間的連線關係
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2、啟動 agent 去採集資料:
在$FLUME_HOME 下執行如下命令:
bin/flume-ng agent -c conf -f agentconf/netcat-logger.properties -n a1 -Dflume.root.logger=INFO,console
-c conf 指定 flume 自身的配置檔案所在目錄
-f conf/netcat-logger.perproties 指定我們所描述的採集方案
-n a1 指定我們這個 agent 的名字
3、測試
先要往 agent 的 source 所監聽的埠上傳送資料,讓 agent 有資料可採
例如在本機節點,使用 telnet localhost 44444 命令就可以,如果這個命令的執行過程中發現丟擲異常說:command not found ,那麼請使用:sudo yum -y install telnet 這個命令進行 telnet 的安裝
輸入兩行資料:
hello huangbo
1 2 3 4
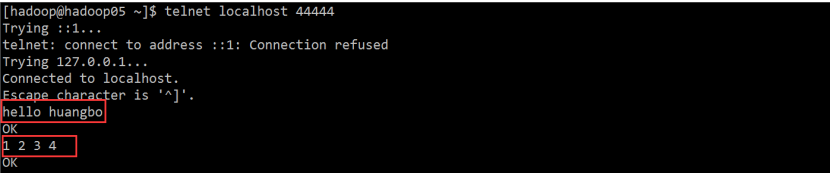
4、Flume-Agent 接收的結果
