
分類器之adaboost
http://www.cnblogs.com/hrhguanli/p/3932488.html
Boosting簡單介紹
分類中通常使用將多個弱分類器組合成強分類器進行分類的方法,統稱為整合分類方法(Ensemble Method)。比較簡單的如在Boosting之前出現Bagging的方法,首先從從總體樣本集合中抽樣採取不同的訓練集訓練弱分類器,然後使用多個弱分類器進行voting,終於的結果是分類器投票的優勝結果。這樣的簡單的voting策略通常難以有非常好的效果。直到後來的Boosting方法問世,組合弱分類器的威力才被髮揮出來。Boosting意為加強、提升,也就是說將弱分類器提升為強分類器。而我們常聽到的AdaBoost是Boosting發展到後來最為代表性的一類。所謂AdaBoost,即Adaptive Boosting,是指弱分類器依據學習的結果反饋Adaptively調整如果的錯誤率,所以也不須要不論什麼的先驗知識就能夠自主訓練。Breiman在他的論文裡讚揚AdaBoost是最好的off-the-shelf方法。
兩類Discrete AdaBoos演算法流程
AdaBoosting方法大致有:Discrete Adaboost, Real AdaBoost, LogitBoost, 和Gentle AdaBoost。全部的方法訓練的框架的都是類似的。以Discrete Adaboost為例,其訓練流程例如以下:

首先初始化每一個樣本同樣的權重(步驟2);之後使用加權的樣本訓練每一個弱分類器 (步驟3.1);分類後得到加權的訓練錯誤率和比例因子 (步驟3.2);將被錯誤分類的樣本的權重加大,並將改動後的權重再次歸一化(步驟3.3);迴圈訓練過程,終於使用比例因子 組合組合弱分類器構成終於的強分類器。
以下看一個更形象的圖,多個弱分類器的組合過程和結果大致為:
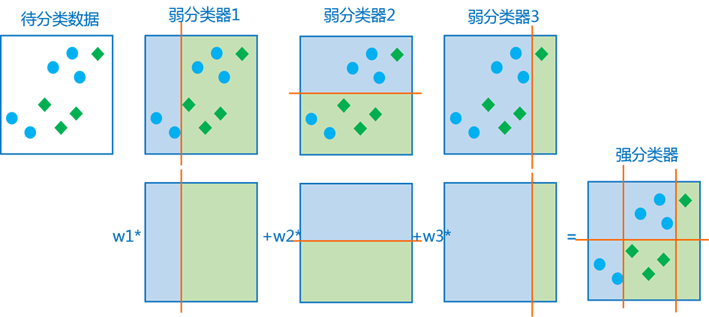
訓練的迴圈過程,加重被錯誤分類的樣本的權重是一種有效的加速訓練的方法。因為訓練中正確率高的弱分類器權重較大,新一輪的訓練中正確分類的樣本會越來越多,權重較小的訓練樣本對在新一輪的訓練中起作用較小,也就是,每一輪新的訓練都著重訓練被錯誤分類的樣本。
實際訓練中弱分類器是一樣的,但弱分類器實際使用的訓練資料不同,通常使用特徵向量的每一維分別構成一個弱分類器。而後來大名鼎鼎的Haar+Adaboost人臉檢測方法是使用每種Haar特徵構成一個弱分類器,基於Block的Haar特徵比簡單的基於pixel的特徵有帶有很多其它的資訊,通常能得到更好的檢測效果,而積分圖Integral的方法使其在計算速度上也有非常大優勢。有興趣可參考《
Real AdaBoost和Gentle AdaBoost
Discrete Adaboost是最簡單的兩類Boosting分類結果,而興許的Real AdaBoost(也稱為AdaBoost.MH)能夠看做Discrete Adaboost的泛化形式,弱分類器能夠輸出多個分類結果,並輸出這幾個分類結果的可能性,能夠看成每一個弱分類器都更不“武斷”。而Gentle AdaBoost則是改動了迭代訓練過程中錯誤樣本權重調整的方法,較少地強調難以分類的樣本,從而避免了原本AdaBoost對”非典型”的正樣本權值調整非常高而導致了分類器的效率下降的情況。,而產生的變種演算法。AdaBoost的Matlabe工具箱GML_AdaBoost_Matlab_Toolbox實現了Real AdaBoost, Gentle AdaBoost和Modest AdaBoost,且有個概況明瞭的介紹(工具箱的使用內部用手冊,也能夠參考下一篇《CART和GML AdaBoost Matlab Toolbox》):
至於LogitAdaBoost我事實上不太瞭解,詳細可參考《OpenCV關於AdaBoost的一些說明》。
adaboost 的幾種改進
- Modest adaboost
- real adaboost
- gentle adaboost
- logita daboost
