
Cs231n-assignment 1作業筆記
assignment 1
assignment1講解參見:
https://blog.csdn.net/u014485485/article/details/79433514?utm_source=blogxgwz5
np. flatnonzero(a) 返回a的展平版本中非零的索引。
a1 = np.random.choice(a=5, size=3, replace=False, p=None) 引數分別從a 中以概率p,隨機選擇3個, p沒有指定的時候相當於是一致的分佈。replacement的意思是抽樣之後還放不放回去,如果是False的話,那麼出來的三個數都不一樣,如果是True的話, 有可能會出現重複的,因為前面抽的放回去了。
subplot(nrows, ncols, plot_number) 作用是把一個繪圖區域(可以理解成畫布)分成多個小區域,用來繪製多個子圖。nrows和ncols表示將畫布分成(nrows*ncols)個小區域,每個小區域可以單獨繪製圖形;plot_number表示將圖繪製在第plot_number個子區域。舉例: createPlot = subplot(222),表示畫布分成(2*2=4)個小區域,並將圖createPlot繪製在畫布中的第二個子區域,也就是右上角位置。
imshow():https://matplotlib.org/api/pyplot_api.html#matplotlib.pyplot.imshow
astype('uint8'): 把影象資料型別轉換為無符號八位整型,範圍是0-255。如果輸入影象是無符號八位整型的,返回的影象和源影象相同。
plt.axis('off') 不顯示座標尺寸,區別見下圖:

numpy.reshape(a, newshape, order='C'):
a:array_like。要重新形成的陣列。
newshape:int或tuple的整數。新的形狀應該與原始形狀相容。如果是整數,則結果將是該長度的1-D陣列。一個形狀維度可以是-1。在這種情況下,從陣列的長度和其餘維度推斷該值。
order:{'C','F','A'}可選。使用此索引順序讀取a的元素,並使用此索引順序將元素放置到重新形成的陣列中。'C'意味著使用C樣索引順序讀取/寫入元素,最後一個軸索引變化最快,回到第一個軸索引變化最慢。'F'意味著使用Fortran樣索引順序讀取/寫入元素,第一個索引變化最快,最後一個索引變化最慢。注意,'C'和'F'選項不考慮底層陣列的記憶體佈局,而只是參考索引的順序。'A'意味著在Fortran類索引順序中讀/寫元素,如果a 是Fortran 在記憶體中連續的,否則為C樣順序。
歐式距離(對應L2範數):最常見的兩點之間或多點之間的距離表示法,又稱之為歐幾里得度量,它定義於歐幾里得空間中。n維空間中兩個點x1(x11,x12,…,x1n)與 x2(x21,x22,…,x2n)間的歐氏距離:
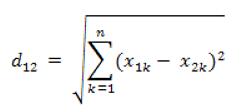
np.bincount():它大致說bin的數量比x中的最大值大1,每個bin給出了它的索引值在x中出現的次數。下面,我舉個例子讓大家更好的理解一下:x中最大的數為7,因此bin的數量為8,那麼它的索引值為0->7
x = np.array([0, 1, 1, 3, 2, 1, 7])
索引0出現了1次,索引1出現了3次......索引5出現了0次......
np.bincount(x)
因此,輸出結果為:array([1, 3, 1, 1, 0, 0, 0, 1])
np.argmax():取出a中元素最大值所對應的索引a = np.array([3, 1, 2, 4, 6, 1]),b=np.argmax(a) 此時最大值位6,其對應的位置索引值為4,(索引值預設從0開始)
np.argsort():將x中的元素從小到大排列,提取其對應的index(索引),然後輸出到y。
KNN原理:找出距離最近的k個點對應的標籤,然後找出出現次數最多的標籤作為預測標籤。
F範數:設A是mxn的矩陣,其F範數定義為:
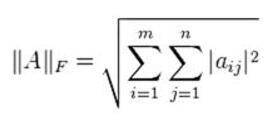
numpy.split(ary, indices_or_sections, axis=0):Split an array into multiple sub-arrays.
>>> x = np.arange(9.0) >>> np.split(x,3) [array([ 0., 1., 2.]), array([ 3., 4., 5.]), array([ 6., 7., 8.])]