
分散式服務鏈路追蹤系統Zipkin學習記錄
阿新 • • 發佈:2018-12-24
Zipkin是一個分散式追蹤系統。它有助於收集解決微服務架構中延遲問題所需的時序資料。它管理這些資料的收集和查詢。Zipkin的設計基於Google Dapper論文。
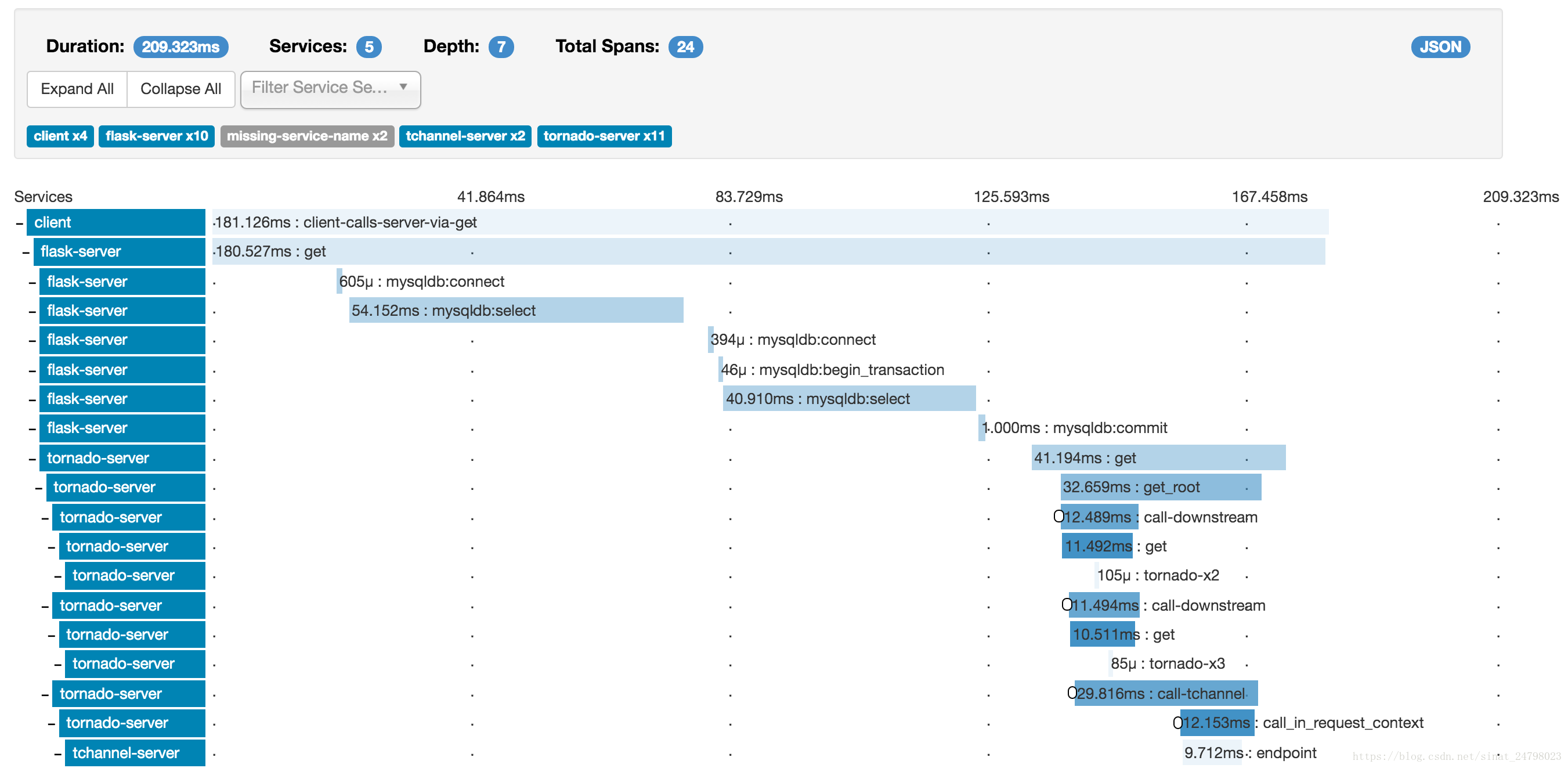
應用程式用於向Zipkin報告時間資料。Zipkin使用者介面還提供了一個依賴關係圖,顯示每個應用程式有多少跟蹤請求。如果您正在解決延遲問題或錯誤問題,則可以根據應用程式,跟蹤長度,註釋或時間戳過濾或排序所有跟蹤。一旦選擇了一個跟蹤,您可以看到每個跨度所花費的總跟蹤時間的百分比,從而可以確定問題應用程式。
為什麼使用Zipkin
隨著業務越來越複雜,系統也隨之進行各種拆分,特別是隨著微服務架構和容器技術的興起,看似簡單的一個應用,後臺可能有幾十個甚至幾百個服務在支撐;一個前端的請求可能需要多次的服務呼叫最後才能完成;當請求變慢或者不可用時,我們無法得知是哪個後臺服務引起的,這時就需要解決如何快速定位服務故障點,Zipkin分散式跟蹤系統就能很好的解決這樣的問題。
三種啟動方式
docker 啟動
docker run -d -p 9411:9411 openzipkin/zipkinjava 啟動
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jarspringboot 啟動
依賴
<dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-server</artifactId> </dependency> <dependency><groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> </dependency>
預設記憶體儲存
新增mysql 儲存
<dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-storage-mysql</artifactId> </dependency>配置 資料庫<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>com.zaxxer</groupId> <artifactId>HikariCP</artifactId> </dependency>
#資料庫指令碼建立地址,當有多個是可使用[x]表示集合第幾個元素 spring.datasource.schema[0]=classpath:/sql/zipkin.sql spring.datasource.name=zipkin spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://local-pc-node1:3306/snjx?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false spring.datasource.username=snjx spring.datasource.password=kRqKjGw1s;RH spring.datasource.type=com.zaxxer.hikari.HikariDataSource spring.datasource.hikari.minimum-idle=5 spring.datasource.hikari.maximum-pool-size=15 spring.datasource.hikari.auto-commit=true spring.datasource.hikari.idle-timeout=30000 spring.datasource.hikari.pool-name=DatebookHikariCP spring.datasource.hikari.max-lifetime=1800000 spring.datasource.hikari.connection-timeout=30000 spring.datasource.hikari.connection-test-query=SELECT 1
zipkin.sql 檔案
CREATE TABLE IF NOT EXISTS zipkin_spans ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL, `id` BIGINT NOT NULL, `name` VARCHAR(255) NOT NULL, `parent_id` BIGINT, `debug` BIT(1), `start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL', `duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate'; ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations'; ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds'; ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames'; ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range'; CREATE TABLE IF NOT EXISTS zipkin_annotations ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id', `span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id', `a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1', `a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB', `a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation', `a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp', `endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address', `endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds'; ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames'; ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces'; ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job'; CREATE TABLE IF NOT EXISTS zipkin_dependencies ( `day` DATE NOT NULL, `parent` VARCHAR(255) NOT NULL, `child` VARCHAR(255) NOT NULL, `call_count` BIGINT, `error_count` BIGINT ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);
client 端的配置
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin</artifactId> </dependency>
#zipkin取樣率,預設為0.1,改為1後全取樣,但是會降低介面呼叫效率 spring.sleuth.sampler.percentage=1.0 #服務鏈路追蹤 spring.zipkin.base-url=http://localhost:8867
spring.zipkin.base-url=http://localhost:8867 這個主意不需要新增/zipkin 字尾
啟動執行的結果圖
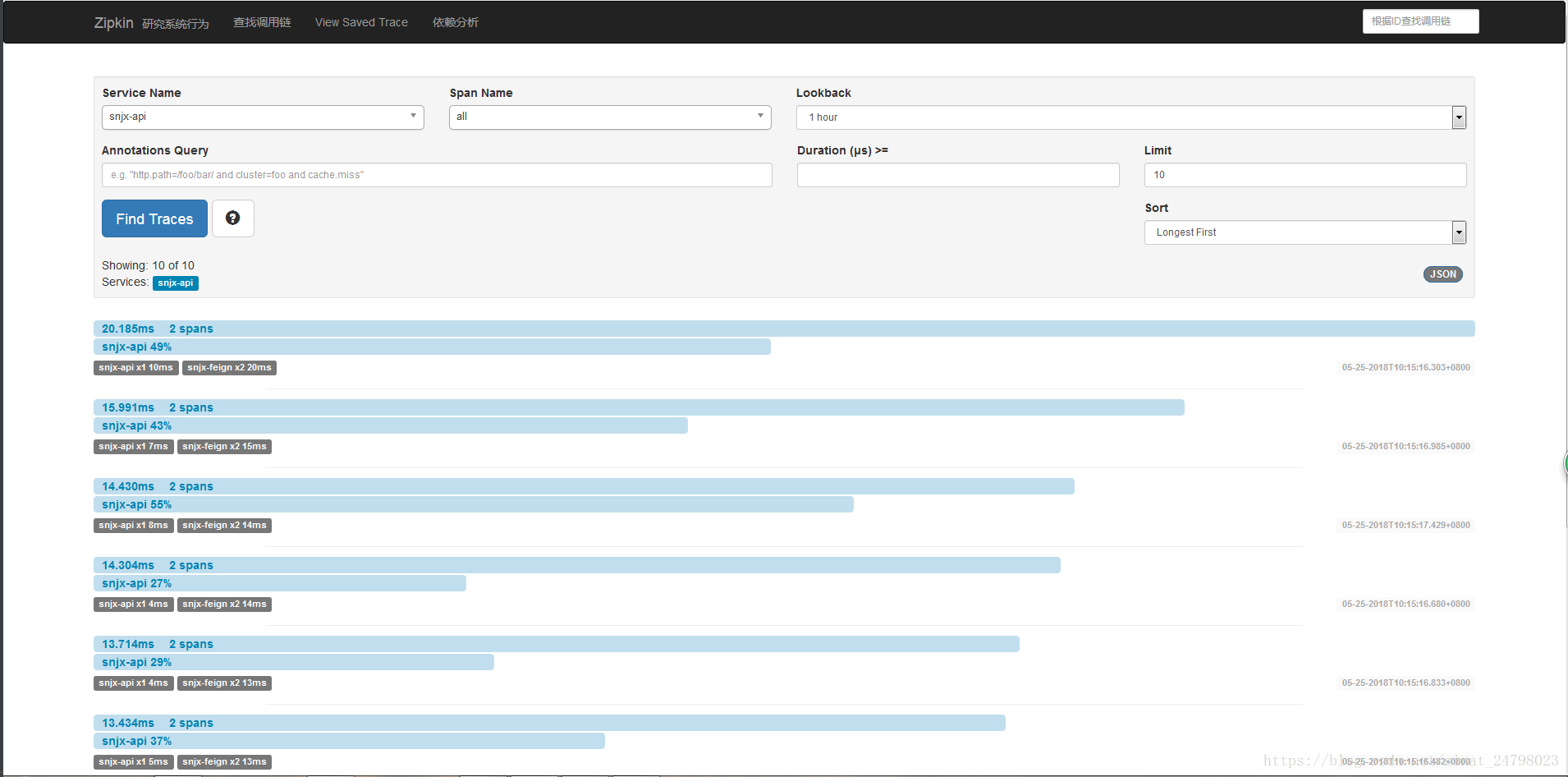
服務之間依賴呼叫關係圖

ps : zikpin 還提供其他方式的存貯 如 Cassandra,Elasticsearch