
scala spark程式設計常見問題總結
阿新 • • 發佈:2018-12-25
問題:ERROR ActorSystemImpl: Uncaught fatal error from thread [sparkDriver-akka.remote.default-remote-dispatcher-8] shutting down ActorSystem [sparkDriver]
15/07/28 13:46:59 ERROR ActorSystemImpl: Uncaught fatal error from thread [sparkDriver-akka.remote.default-remote-dispatcher-8] shutting down ActorSystem [sparkDriver]
java.lang.OutOfMemoryError: 由於叢集較小,只有4臺機器,在其中master上面提交了任務,結果出現上述異常。即driver 記憶體不足,因此使用spark-sumbit指令碼時,提供–executor-memory –driver-memory選項,來相應的設定記憶體。
問題:空指標異常
導致這個問題的原因有很多,和spark本身相關的主要有兩種情況:
- 巢狀使用了RDD操作,比如在一個RDD map中又對另一個RDD進行了map操作。主要原因在於spark不支援RDD的巢狀操作。
- 在RDD操作中引用了object非原始型別(非int long等簡單型別)的成員變數。貌似是由於object的成員變數預設是無法序列化的。解決方法:可以先將成員變數賦值給一個臨時變數,然後使用該臨時變數即可
調整分割槽數的重要性
剛開始執行的時候,預設分割槽數為2,結果在叢集上面執行的時間甚至比本地都慢。通過Web UI檢視任務狀態,如下圖:
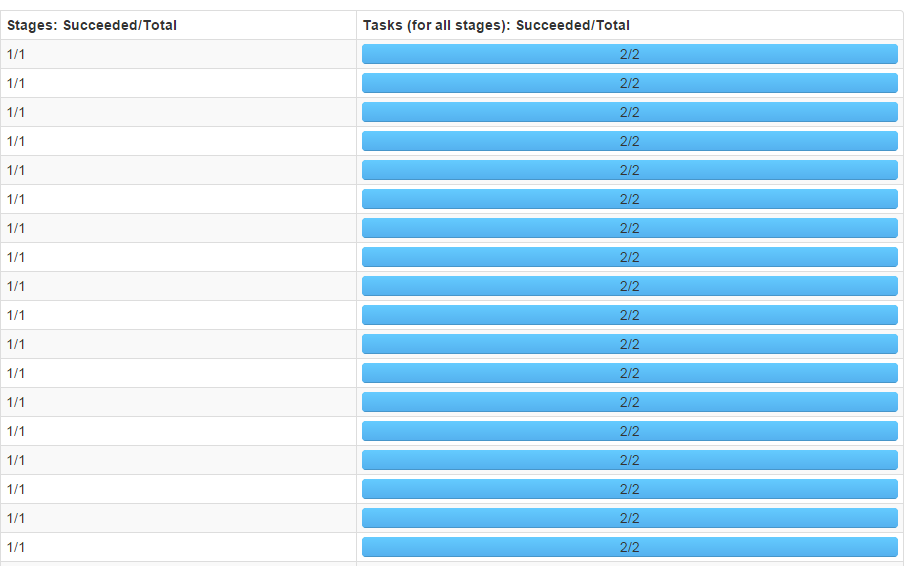
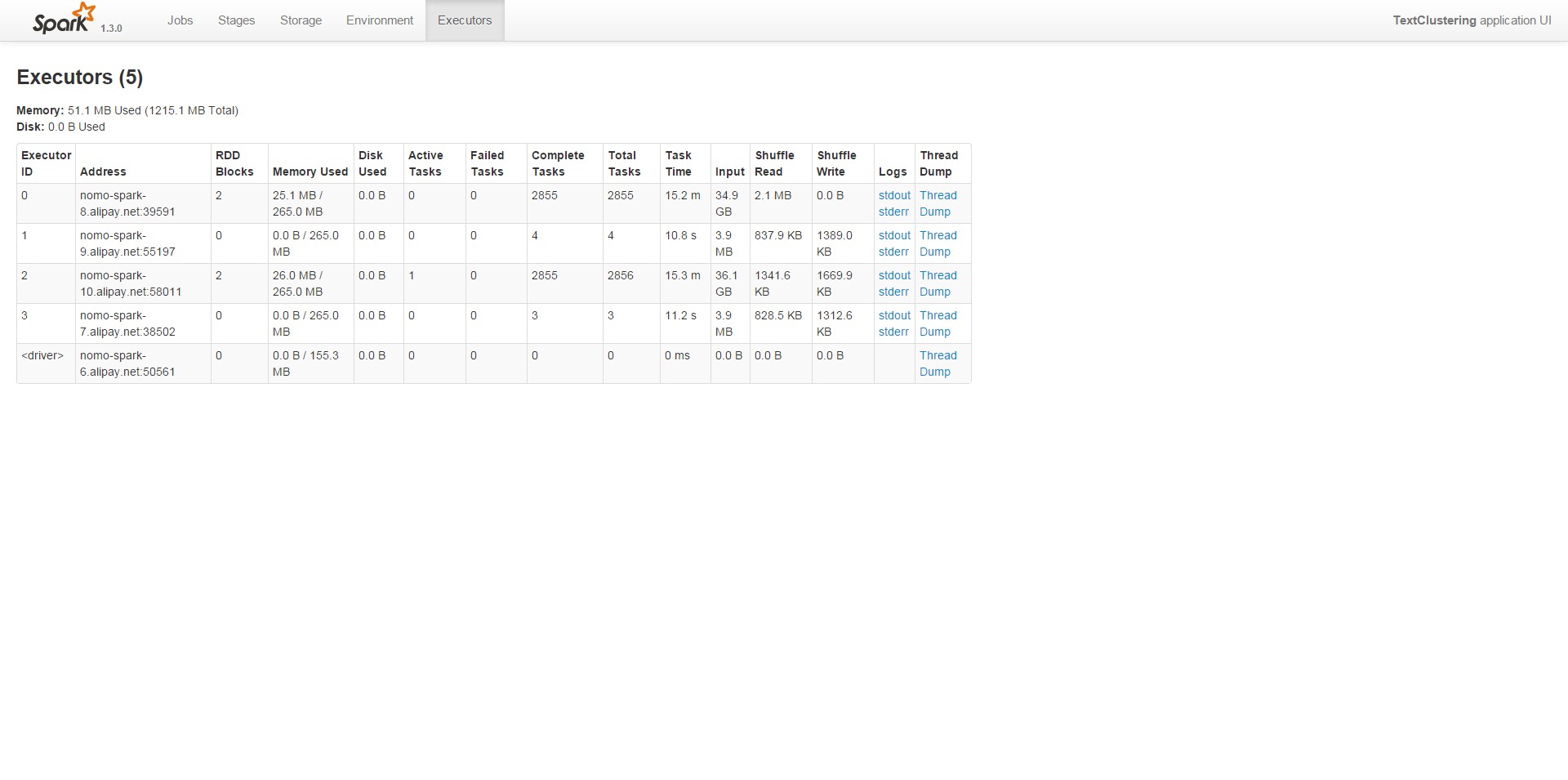
可以看到每個stage只有2個task,4個executor實際上只有兩個參與了運算,並行度真是夠低的。
調整方式:在用textFile函式讀取檔案的時候指定分割槽數,由於叢集中有4個executor,而分割槽數最好是executor數量的整數倍,因此將分割槽數指定為8,調整後,結果如下所示:
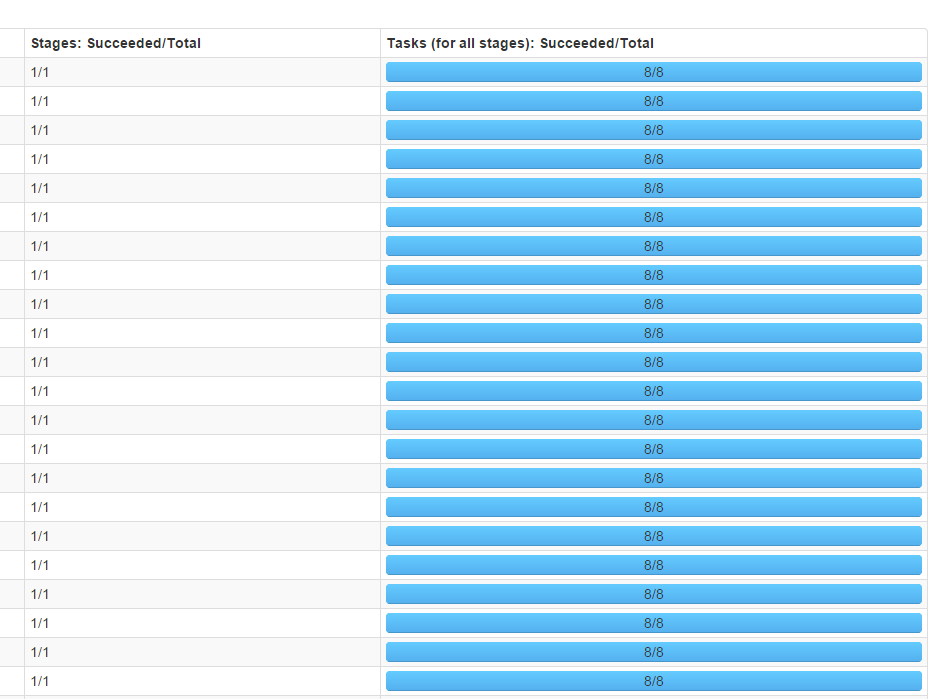
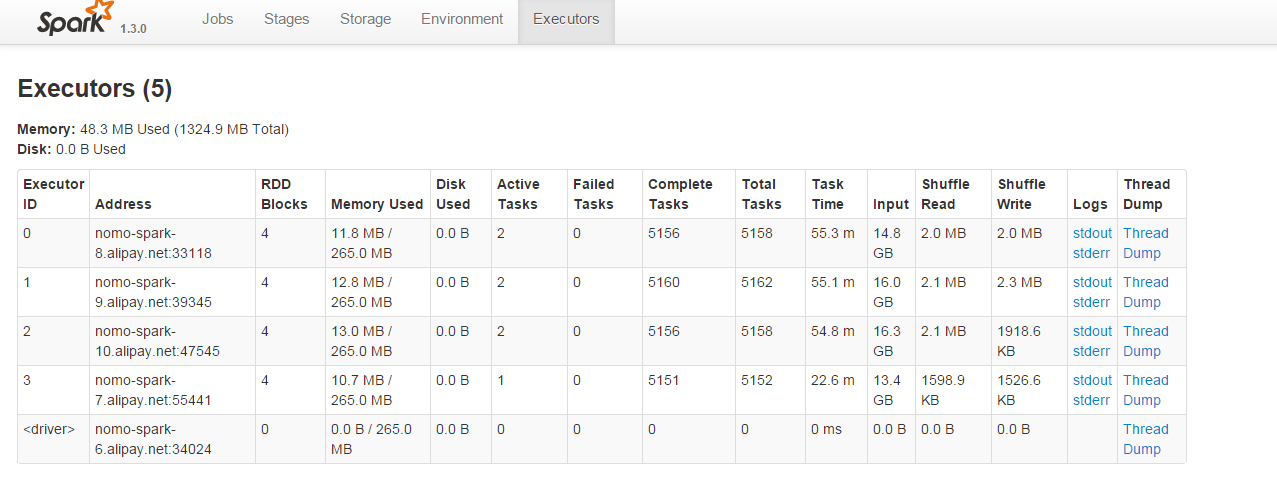
可見4個executor都參與了運算,並行度有了顯著提升。