
Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation
摘要
先前基於深度學習的最先進的場景文字檢測方法可大致分為兩類。第一類將場景文字視為一般物件的型別,並遵循一般物件檢測範例,通過迴歸文字框位置來定位場景文字,但是受到場景文字的任意方向和大縱橫比的困擾。第二個直接分割文字區域,但大多數需要複雜的後期處理。在本文中,我們提出了一種方法,它結合了兩種方法的思想,同時避免了它們的缺點。我們建議通過定位文字邊界框的角點並在相對位置分割文字區域來檢測場景文字。在推理階段,通過對角點進行取樣和分組來生成候選框,其通過分割圖進一步評分並由NMS抑制。與以前的方法相比,我們的方法可以自然地處理長方向文字,不需要複雜的後處理。在ICDAR2013,ICDAR2015,MSRA-TD500,MLT和COCO-Text上的實驗表明,所提出的演算法在準確性和效率方面實現了更好或相當的結果。基於VGG16,它在ICDAR2015上實現了84:3%的F測量,在MSRA-TD500上實現了81:5%的F測量。
1、介紹
最近,由於對現實世界應用(例如,產品搜尋[4],影象檢索[20]和自動駕駛)的不斷增長的需求,從自然場景影象中提取文字資訊已變得越來越流行。場景文字檢測旨在定位自然影象中的文字,在各種文字閱讀系統中起著重要作用[35,11,50,6,21,52,5,42,41,14,8,26]。
由於外部和內部因素,場景文字檢測具有挑戰性。外部因素來自環境,例如噪聲,模糊和遮擋,這也是擾亂一般物體檢測的主要問題。內部因素是由場景文字的屬性和變化引起的。與一般物體檢測相比,場景文字檢測更復雜,因為:1)場景文字可能存在於任意方向的自然影象中,因此邊界框也可以是旋轉矩形或四邊形; 2)場景文字邊界框的寬高比變化很大; 3)由於場景文字可以是字元,單詞或文字行的形式,因此在定位邊界時可能會混淆演算法。
近年來,隨著一般目標檢測和語義分割的快速發展,現場文字檢測已被廣泛研究[58,11,6,53,21,46,56,40,45],並取得了明顯的進展。 基於一般物件檢測和語義分割模型,進行了幾個精心設計的修改以更準確地檢測文字。那些場景文字檢測器可以分成兩個分支。第一個分支基於通用物件檢測器(SSD [31],YOLO [38]和DenseBox [19]),如TextBoxes [28],FCRN [15]和EAST [57]等,它們預測候選邊界框直。第二個分支基於語義分割,例如[56]和[54],它們生成分割圖並通過後處理生成最終文字框。
與以前的方法不同,在本文中,我們結合了物件檢測和語義分割的思想,並以另一種方式應用它們。
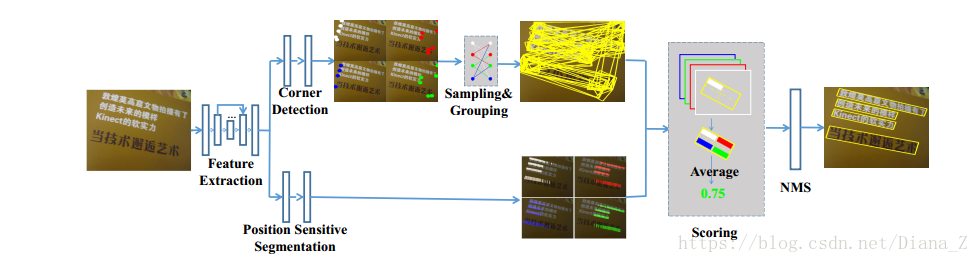
該方法的主要優點如下:1)由於我們通過對角點進行取樣和分組來檢測場景文字,因此我們的方法可以自然地處理任意文字; 2)當我們檢測角點而不是文字邊界框時,我們的方法可以自發地避免寬高比變化大的問題; 3)通過位置敏感分割,它可以很好地分割文字例項,無論例項是字元,單詞還是文字行; 4)在我們的方法中,候選框的邊界由角點確定。與從錨點([28,33])或文字區域([57,17])迴歸文字邊界框相比,生成的邊界框更準確,特別是對於長文字。
我們驗證了我們的方法在橫向,定向,長和定向文字以及公共基準的多語言文字方面的有效性。結果表明了該演算法在精度和速度方面的優勢。具體而言,我們對ICDAR2015 [23],MSRA-TD500 [53]和MLT [2]的方法的F-測量值分別為84:3%,81:5%和72:4%,優於以前的狀態。藝術方法顯著。此外,我們的方法在效率方面也具有競爭力。它每秒可以處理超過10.4張影象(512x512大小)。
本文的貢獻有四個方面:(1)我們提出了一種新的場景文字檢測器,它結合了物體檢測和分割的思想,可以進行端到端的訓練和評估。 (2)基於位置敏感的ROI池[10],我們提出了一個旋轉的位置敏感ROI平均池層,可以處理任意導向的提議。 (3)我們的方法可以同時處理多方面場景文字中的挑戰(例如旋轉,變化的寬高比,非常接近的例項),這些都是以前的方法所遇到的。 (4)我們的方法在準確性和效率方面都取得了更好或更具競爭力的結果
2 相關工作
2.1. 基於迴歸的文字檢測
基於迴歸的文字檢測已成為近兩年來場景文字檢測的主流。在一般目標檢測器的基礎上,幾種文字檢測方法被提出,並取得了實質性進展。源自SSD [31],TextBoxes [28]使用“長”預設框和“長”卷積濾波器來應對極端寬高比。 同樣,在[33] Ma等人利用Faster-RCNN [39]的架構,在RPN中新增旋轉錨點,以檢測任意導向的場景文字。 SegLink [40]預測文字片段及其在SSD樣式網路中的連結,並將片段連結到文字框,以便處理自然場景中的長向文字。 基於DenseBox [19],EAST [57]直接回歸文字框。
我們的方法也適用於一般物體探測器DSSD [12]。 但與上述直接回歸文字框或段的方法不同,我們建議區域性化角點的位置,然後通過對檢測到的角進行取樣和分組來生成文字框。
2.2。 基於分割的文字檢測
基於分段的文字檢測是文字檢測的另一個方向。 受FCN [32]的啟發,提出了一些使用分割圖檢測場景文字的方法。 在[56],張等人首先嚐試通過FCN從分段對映中提取文字塊。 然後他們用MSER [35]檢測那些文字塊中的字元,並通過一些先驗規則將字元分組為單詞或文字行。 在[54]中,姚等人使用FCN預測輸入影象的三種類型的地圖(文字區域,字元和連結方向)。 然後進行一些後處理以獲得具有分割圖的文字邊界框。
與以前基於分割的文字檢測方法不同,後者通常需要複雜的後處理,我們的方法更簡單,更清晰。 在推理階段,位置敏感的分割圖用於對我們提出的旋轉位置敏感平均ROI池層對候選框進行評分。
2.3。基於角點的通用目標檢測
基於角點的一般物件檢測是一種通用物件檢測方法的新流。在DeNet [48]中,Tychsen-Smith等人提出角點檢測層和稀疏樣本層以替換Faster-RCNN樣式的兩階段模型中的RPN。在[51]中,Wang等人提出PLN(點連結網路),它使用完全卷積網路對邊界框的角點/中心點及其連結進行迴歸。然後使用角點/中心點及其連結形成物件的邊界框。
我們的方法受到基於角點的物體檢測方法的啟發,但存在關鍵差異。首先,我們方法的角點檢測器是不同的。其次,我們使用分割圖來對候選框進行評分。第三,它可以為物件(文字)生成任意導向的框。
2.4。位置敏感分割
最近,提出了具有位置敏感圖的例項感知語義分割方法。在[9]中,戴等人首先介紹分段的相對位置,併為例項段提議提出InstanceFCN。在FCIS [27]中,在位置敏感的內/外得分圖的幫助下,Li等人提出用於例項感知語義分段的端到端網路。
我們也採用位置敏感的分割圖來預測文字區域。與上述方法相比,有三個主要區別:1)我們直接利用位置敏感的實況優化網路(詳見4.1.1節); 2)我們的位置敏感地圖可用於同時預測文字區域和評分建議(詳見4.2.2節),與使用兩種位置敏感地圖(內部和外部)的FCIS不同; 3)我們提出的輪換位置敏感ROI平均池可以處理任意導向的提議。
3.網路
我們用到的網路是一個全卷積網路,作用是特徵提取、角點檢測和位置敏感分割。 網路架構如圖3所示。給定影象,網路產生候選角點和分割圖。
3.1. 特徵提取
我們模型的主幹是從預先訓練的VGG16 [44]網路改編而來,其設計考慮了以下因素:1)場景文字的大小差異很大,因此骨幹必須有足夠的能力來很好地處理這個問題; 2)自然場景中的背景很複雜,因此特徵應該更好地包含更多的上下文。受到FPN [29]和DSSD [12]在這些問題上取得的良好效能的啟發,我們採用FPN / DSSD架構中的主幹來提取特徵。
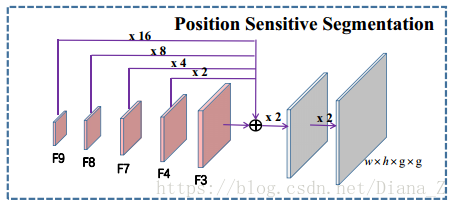
詳細地說,我們將VGG16中的fc6和fc7轉換為卷積層,並將它們分別命名為conv6和conv7。然後在conv7上方堆疊幾個額外的卷積層(conv8,conv9,conv10,conv11)以擴大提取的特徵的感知域。之後,DSSD [12]中提出的一些反捲積模組用於自上而下的途徑(圖3)。特別是,為了很好地檢測不同大小的文字,我們使用256個通道將反捲積從conv11到conv3串聯起來(來自conv10,conv9,conv8,conv7,conv4,conv3的特徵被重用),並且總共構建了6個反捲積模組。為方便起見,我們將那些輸出特徵命名為F3; F4; F7; F8; F9; F10和F11。最後,由具有更豐富的特徵表示的conv11和反捲積模組提取的特徵用於檢測角點並預測位置敏感的地圖。

3.2. 角點檢測
對於給定的旋轉矩形邊界框R =(x; y; w; h;θ),有4個角點(左上角,右上角,右下角,左下角),可以表示為順時針方向的二維角點座標{(x1; y1); (x2; y2); (x3; y3); (x4; y4)}。為了方便地檢測角點,這裡我們重新定義並用水平方格C =(xc; yc; ss; ss)表示角點,其中xc; yc是角點的座標(例如x1;y1表示左上角角點的座標),也是方格C的中心座標點。 ss是旋轉的矩形邊界框R的短邊長度。
與SSD和DSSD一樣,我們使用預設框檢測角點。與SSD或DSSD中每個預設框輸出相應候選框的分類分數和偏移的方式不同,角點檢測更復雜,因為在同一位置可能有多個角點(例如一個位置可以同時是一個選框的左下角和領一個選框的右上角)。所以在我們的方法中,預設框應輸出候選框4種角點的四個分類分數和偏移。
我們調整[12]中提出的預測模組,以卷積方式預測兩個分支中的分數和偏移。為了降低計算複雜度,將所有卷積的濾波器設定為256。在一張m×n的特徵圖中,每個單元中有k個預設框,對於每個預設框的每種角點,“得分”分支和“偏移”分支分別輸出2個分數和4個偏移。這裡,“得分”分支的2個分數分別表示該位置是否存在角點。總的來說,“得分”分支和“偏移”分支的輸出矩陣是k×q×2和k×q×4,其中q表示角點的型別。預設情況下,q等於4。
在訓練階段,我們遵循SSD中預設框和地面例項的匹配策略。要檢測具有不同大小的場景文字,我們在多個圖層要素上使用多個大小的預設框。表1中列出了所有預設框的比例。預設框的縱橫比設定為1。


3.3. 位置敏感分割
在先前基於分割的文字檢測方法[56,54]中,分割圖用以表示每個畫素屬於文字區域的概率。然而,由於文字區域的重疊和文字畫素的不準確預測,得分圖中的那些文字區域總是不能很好的被區分。為了從分割圖獲得文字邊界框,進行復雜的後期處理,方法如[56,54]。
受InstanceFCN [9]的啟發,我們使用位置敏感分割來生成文字分割圖。與先前的文字分割方法相比,相對位置被使用了。詳細地,對於文字邊界框R,使用一個g×g規則網格將文字邊界框劃分為多個區間(比如,對於一個2×2網格,文字區域可以分成4個區間,即頂部 - 左,右上,右下,左下)。對於每個區間,使用分割圖來確定該地圖中的畫素是否屬於該區間。
在統一網路中,我們使用角點檢測構建位置敏感分段。我們重用F3,F4,F7,F8,F9的特徵,並在它們上構建一些卷積塊,在角點檢測分支當中遵循殘餘塊體系結構(如圖3所示)。通過雙線性上取樣將這些塊的輸出調整為F3的比例,比例因子被設定為1,2,4,8,16。然後將具有相同比例的輸出相加以產生更豐富的特徵。我們通過兩個連續的Conv1x1-BN-ReLU-Deconv2x2塊進一步擴大融合特徵的解析度,並將最後一個去卷積層的核心設定為g×g。因此,最終的位置敏感分割圖具有g×g個通道並且具有與輸入影象相同的大小。在這項工作中,我們預設將g設定為2。
4.培訓和推理
4.1. 訓練
4.1.1 標籤生成
對於輸入訓練樣本,我們首先將每個文字框轉換為最小外切矩形,然後確定4個角點的相對位置。
我們通過以下規則確定旋轉矩形的相對位置:1)頂部和左下角點的x座標必須小於右上角和右下角點的x座標; 2)左上角和右上角點的y座標必須分別小於左下角和右下角點的y座標。之後,實際選框可以表示為具有角點相對位置的旋轉矩形。為方便起見,我們將旋轉的矩形稱為,其中Pi =(xi; yi)是旋轉矩形的角點,包括左上角,右上角,右下角,左下角。
我們使用R生成角點檢測和位置敏感分割的標籤。對於角點檢測,我們首先計算R的短邊並用水平方塊表示4個角點,如圖4(a)所示。對於位置敏感的分割,我們使用R生成文字/非文字的畫素掩碼。我們首先初始化4個與輸入影象具有相同比例的掩碼,並將所有畫素值設定為0。然後我們將R分成四個帶有2×2規則網格的區間,並將每個區域分配給一個掩碼,例如左上方的區域到第一個掩碼。之後,我們將這些區域中所有畫素的值設定為1,如圖4(b)所示。

4.1.2優化
我們同時訓練角點檢測和位置敏感分割。損失函式定義為:
其中 Lconf 和 Lloc 是角點檢測模組中預測置信度得分的得分分支和角點檢測模組中的偏移分支的損失函式。 Lseg是位置敏感分割的損失函式。 Nc是預設框的數量,Ns是分割圖中的畫素數。 Nc和Ns用於歸一化角點檢測和分割的損失。 λ1和λ2是三個任務的平衡因子。預設情況下,我們將λ1設定為1,將λ2設定為10。
我們遵循SSD的匹配策略,並使用交叉熵損失訓練得分分支:
其中yc是所有預設框,1表示正確,0表示錯誤。 pc是預測的分數。考慮到正樣品和負樣品之間的極端不平衡,類別均質化是必要的。我們使用[43]中提出的online hard negative mining proposed 來平衡訓練樣本,並將正樣本與負樣本比率設定為1:3。

*************************************************************************
初始化:針對每一個Fi,初始化一個深度為2*4(4個角)*default box,大小與feature map一樣的矩陣,然後reshape到[?,2]的矩陣
yc:初始化一個深度為2*4*default box,大小與feature map一樣的矩陣,如果該點對應存在gtbox,其值為[0,1],否則值為[1,0]。通過實際的gtbox與feature map對映到原圖之後對應的感受野的default box的交併比來判斷是否存在角點。比如feature map大小為4*4,其中一個點對應原圖中128*128的感受野,存在4個default box,在感受野中存在一個30*30的焦點框,將每一個default box與gt box進行交併比的運算,小於0.5則認為不存在角點框,大於0.5則認為存在角點框,認為feature map上該點的default box都不存在角點矩陣,所以該點的深度值為32
pc:得到的feature map Fi,Fi通過Corner Point Decection的網路卷積得到了一個與yc一樣大小的預測矩陣,reshape到[?,2],使用softmax標準化引數,使兩兩之間的資料的和為1,再reshape回feature map大小
將pc與yc同樣進行reshape到[?,2],由於第二列的1表示存在角點框,所以取第二列作為標籤進行運算。
由於pos的標籤前會遠大於neg的標籤,因此選擇neg的標籤中score的值從大到小的3*pos的點進行計算
使用交叉熵計算損失
*************************************************************************
對於偏移分支,我們將相對於預設框的偏移量作為fast-RCNN [13]進行迴歸,並使用平滑L1損失對其進行優化:
其中yl是真實框的便宜量,pl是預測的偏移。y1可以通過預設框B =(xb; yb; ssb; ssb)和角點框C =(xc; yc; ssc; ssc)來計算 [13]。
*************************************************************************
初始化:針對每一個Fi初始化一個與之一樣大小的矩陣,深度為default*4(4個角)*4。
yl:Fi的每一個點都有一定數量的default box,每個default box與真實的gt box進行計算,得到4個值,
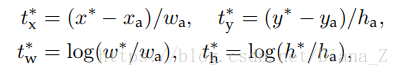
其中x*表示gt box,xa表示defaule box
pl:Fi通過Corner Point Decection的網路卷積得到的一個與yl同樣大小的矩陣
然後將yl與pl分別reshape到[?,4]的大小,然後使用平滑L1損失進行損失計算
*************************************************************************
我們通過最小化Dice 損失來訓練位置敏感的分割[34]:
其中ys是位置敏感分段的標籤,ps是我們分段模組的預測。

*************************************************************************
ys:是一個與feature map一樣大的矩陣,深度為4,四個深度每一層的內容見圖4(b),其中黑色部分為0,白色部分為1。
ps:通過postion sensitive segmentation卷積得到
通過dice損失計算損失。
*************************************************************************
4.2. 推論
4.2.1 取樣和分組
在推理階段,許多角點都符合預測位置、短邊和置信度得分。保留高分(預設值大於0.5)的分數。在NMS之後,基於相對位置資訊組成4個角點集。
我們通過對預測的角點進行取樣和分組來生成候選邊界框。理論上,旋轉的矩形可以由兩個點和垂直於由兩個點構成的線段的一側構成。對於預測點,短邊是已知的,因此我們可以通過對角點集中的兩個角點進行任意取樣和分組來形成旋轉矩形,例如(左上角,右上角),(右上角,下角 - 右),(左下,右下)和(左上,左下)對。
幾個先驗規則用於過濾不合適的對:1)不能違反相對位置關係,例如左上角點的x座標必須小於(左上角,右上角)對中的頂點的x座標; 2)構造的旋轉矩形的最短邊必須大於閾值(預設值為5); 3)一對中兩點的預測短邊ss1和ss2必須滿足:


4.2.2 評分
在對角點進行取樣和分組之後,可以生成大量候選邊界框。 受InstanceFCN [9]和RFCN [10]的啟發,我們通過位置敏感的分割圖對候選邊界框進行評分。 這些過程如圖5所示。為了處理旋轉的文字邊界框,我們在[10]中調整了位置敏感的ROI池層,並提出了旋轉位置敏感的ROI平均池化層。 具體來說,對於旋轉的候選框,我們首先將候選框分成g×g區域。 然後我們為每個區域生成一個矩形,其最小區域覆蓋。 我們遍歷最小矩形中的所有畫素,並計算區域中所有畫素的平均值。 最後,通過平均g×g區間的平均值來獲得旋轉的邊界框的得分。 演算法1中顯示了具體的過程。低分的候選框將被過濾掉。 我們預設將閾值τ設定為0.6。
