
Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation 論文詳解
Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation發表於2018年的cvpr,該文章通過結合角點檢測和影象分割來對影象文字進行定位
Introduction
目前文字定位方法分為兩個分支,一是基於物體檢測的方法(SSD,YOLO,DenseBox),如TextBoxes,FCRN,EAST等。還一種是基於影象分割的方法。本文是將上述兩種方法結合,提出的一種新的檢測方法。
通過文章的結果可以看出F-measure會比EAST高一點,但是速度比EAST慢。
文章中的網路結構採用FPN/DSSD的網路結構,如下圖所示
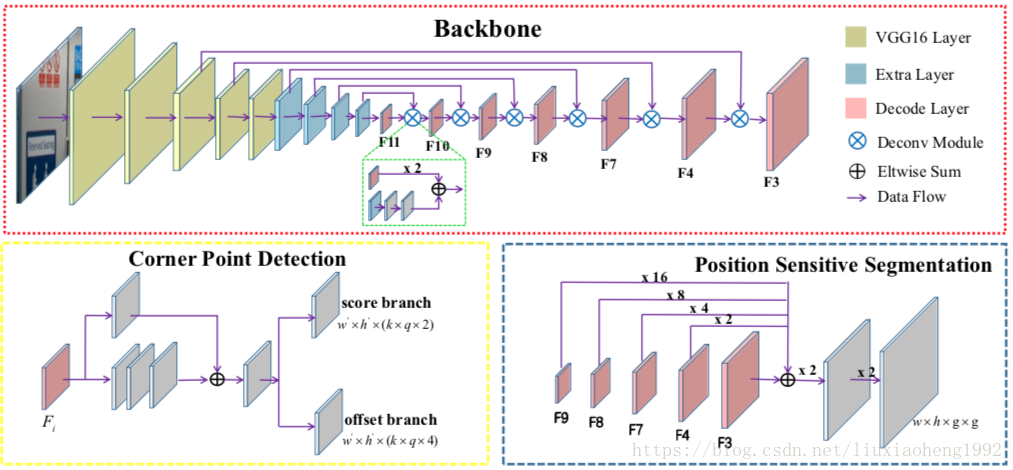
1. Feature Extraction
如上圖紅色框所示,文中採用VGG16,將fc6和fc7層換成卷積層conv6和conv7,並在後面添加了一些卷積層(conv8, conv9, conv10, conv11),用於增加感受野的範圍。之後採用DSSD的top-down pathway結構,解卷積採用了從conv11到conv3的feature map(其中conv10到conv3的featrue map被重用),輸出的feature命名為
。最後得到的conv11,和所有解卷積的feature maps用於角點和位置敏感圖(position-sensitive)的預測
2. Corner Detection
對於一個旋轉矩陣來講,可以通過順時針分佈的四個角點
來得到,這四個點位置分別為左上,右上,左下,右下。為了更方便的檢測角點,文中對角點進行的新的定義,
,其中
代表一個角點如(
這個左上角點),同時它也是一個水平矩形的中心點,ss代表的是待檢測旋轉矩形的短邊。這裡意思就是將待檢測角點用一個水平矩形表示,角點的位置就是這個水平矩形的中心,檢測出水平矩形就相當於檢測出角點的位置。
通過上面角點的重新定義,檢測角點的方法就可以類似於SSD和DSSD,利用定義的default boxes(類似於Faster RCNN中的anchor boxes)來進行矩形的檢測。與物體檢測有所不同的是,同一個位置可能存在多個角點(例如同一個位置可能同時為左下角點和右上角點)。所以對於大小為 的feature map同時有k個default boxes的情況,score branch輸出的類別分數(是否存在角點)通道數為 ,offset branch輸出的通道數為 ,其中q代表角點的型別,預設為4。這部分如上圖中的黃色框所示。
default boxes的scales設定如下表所示,其中default boxes的長寬高比為1。

3. Position-Sensitive Segmentation
這部分如上圖中的藍色框所示
對於一個文字框,可以將框等分為
部分,本文中分為
也就是四個區域,這部分的預測用於對上面檢測出的框打分使用。下面會說明。
這部分的輸出是重用了
,上採用至
大小然後相加,最後連續使用兩個Conv1x1- BN-ReLU-Deconv2x2 塊,得到
通道大小與輸入影象一樣的feature map。
Training and Inference
1.Training-Label Generation
對於每個輸入訓練樣本,首先將標註轉換成包圍字元區域最小的矩形,然後確定4個角點的位置。
對於一個旋轉矩形,4個角點的確定遵循下面兩個規則:
- 左上與左下兩個點的x座標小於右上和右下兩個點的x座標
- 左上與右上兩個點的y座標小於右上和右下兩個點的y座標
通過確定好的4個角點就可以確定旋轉矩陣的位置了,計算旋轉矩陣的短邊就可以使用一個水平正方形重新定義角點了,通過一件確定的旋轉矩陣可以很方便的求的position-sensitive segmentation掩碼,所得的label結果如下圖所示

2.Training-Optimization
損失函式如下:
其中, 和 表示角點檢測中score branch和offset branch輸出的loss, 表示position-sensitive segmentation的損失函式。 表示正例default boxes的個數, 表示分割maps中的畫素個數(分割)。 和 為loss函式的平衡因子,文中分別取值為1和10。
採用的是交叉熵計算