
從零開始機器學習002-梯度下降演算法
阿新 • • 發佈:2018-12-26
老師的課程
1.從零開始進行機器學習
2.機器學習數學基礎(根據學生需求不斷更新)
3.機器學習Python基礎
4.最適合程式設計師的方式學習TensorFlow
上節課講完線性迴歸的數學推導,我們這節課說下如何用機器學習的思想把最合適的權重引數求解出來呢?這裡就涉及到了最優化演算法,其中梯度下降就是最優化演算法中的一種。我們看下梯度下降是怎麼完成最優化求解的。
一、概念:
梯度下降演算法是一個最優化演算法,它是沿梯度下降的方向求解極小值。
二、前提條件:
- 目標函式
使用梯度下降演算法是要求有前提條件的。第一個就是目標函式,梯度下降是求最優解的演算法沒錯,但是你一定要告訴梯度下降,你要求哪個函式的解。萬物得有源頭。目標函式就是源頭。本節課的源頭就是
- 訓練集
這個目標函式是根據上節課推匯出來的最小二乘的公式。只不過1/2後面多了個m。m是總的資料量。意味著是求多個數據之後的平均值。
第二個是訓練集,有了目標函式,還得有資料支撐。只有有了大量的資料,機器才能夠真正的掌握規律。(下方為資料集樣本)
最終的目標是求得是這個目標函式最小(或區域性最小)的引數θ。
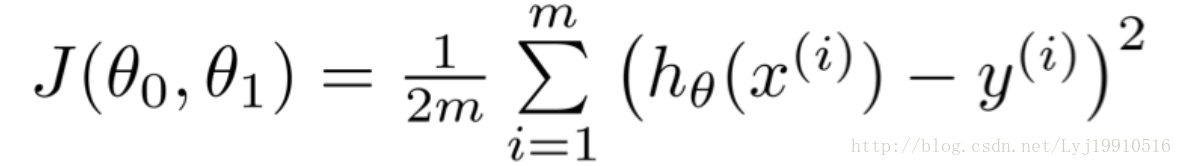


三、訓練步驟
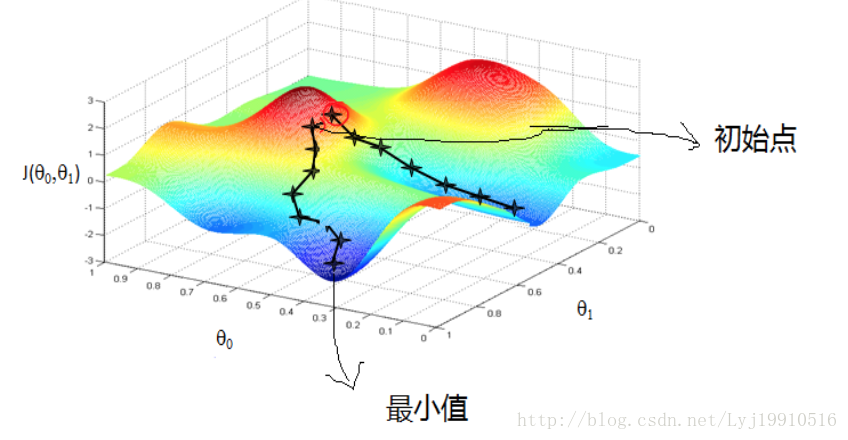
- 隨機生成一個初始點
圖片中紅圈上的點,從上面的圖可以看出:初始點不同,獲得的最小值也不同,因此梯度下降求得的只是區域性最小值; - 確定學習率(Learning rate)
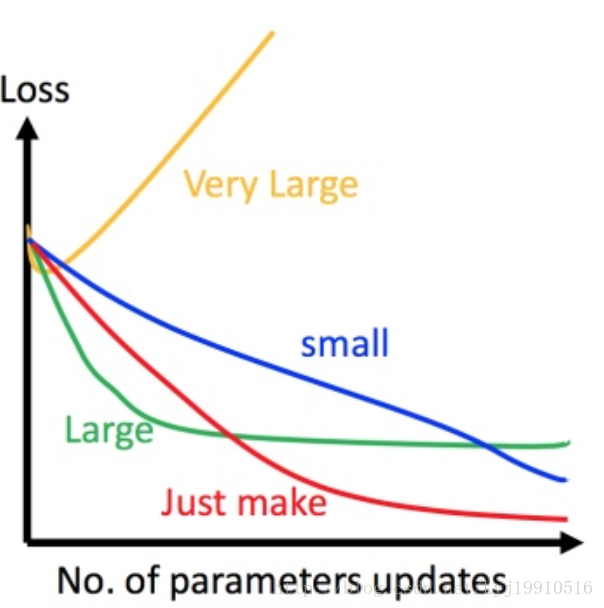
學習率可以理解為下山時每一步邁的大小。步子邁得太大有可能不收斂,步子邁的太小下山速度太慢。如下圖
上圖左邊黑色為損失函式的曲線,假設從左邊最高點開始,如果 learning rate 調整的剛剛好,比如紅色的線,就能順利找到最低點。如果 learning rate 調整的太小,比如藍色的線,就會走的太慢,雖然這種情況給足夠多的時間也可以找到最低點,實際情況可能會等不及出結果。如果 learning rate 調整的有點大,比如綠色的線,就會在上面震盪,走不下去,永遠無法到達最低點。還有可能非常大,比如黃色的線,直接就飛出去了,update引數的時候只會發現損失函式越更新越大。
工作經驗:先使用0.1試下,如果不收斂或者收斂慢,再試0.01、0.001。
還有一點,學習率並不一定全程不變,可以剛開始的時候大一些,後期的時候不斷調小。 - 輸入資料集,確定一個向下的方向,並更新θ。
資料集的輸入一般有三種。批量梯度下降、隨機梯度下降、小批量隨機梯度下降。
批量梯度下降:每調整一步,帶入所有的資料,
優點:所有資料都涉及到,訓練的結果應該是最精確的。
缺點:資料量非常大的時候,訓練速度奇慢無比。
隨機梯度下降:每次隨機獲取資料集裡面的一個值
優點:速度快
缺點:訓練結果可能不夠精確
小批量隨機梯度下降:前兩者的中間產物
速度相對較快,結果相對精確。
在google,TensorFlow中,訓練Mnist資料集的時候,採用的就是小批量隨機梯度下降。在平時工作,小批量隨機梯度下降也應用的最廣泛。 - 訓練終止
當損失函式達到預設值的一個值,或者收斂不明顯時,可以終止訓練。得到的值就是梯度下降優化演算法的最終值(極小值)。

四、其他
問:多個特徵值怎麼訓練?
答:並不是放在一起訓練,而是每個特徵自己訓練自己的。
如下圖:

關注微信公眾號:北國課堂

老師的課程
1.從零開始進行機器學習
2.機器學習數學基礎(根據學生需求不斷更新)
3.機器學習Python基礎
4.最適合程式設計師的方式學習TensorFlow
文章部分圖片及內容借鑑:
http://blog.csdn.net/zyq522376829/article/details/66632699#t3
http://blog.csdn.net/xiazdong/article/details/7950084