
由rand7生成rand10以及隨機數生成方法的討論
阿新 • • 發佈:2018-12-27
2. 直接法——利用rand7做計算
由於捨去法每次呼叫rand7的次數未知,所以希望能夠找到一種直接的方法。當然最直接的方法就是用線性同餘這樣的隨機數生成法直接寫一個,但是這就用不上rand7了,與題意不符合。有人希望用rand7的各種組合計算來完成,比如(rand7+rand7+rand7+...)%10+1或者(rand7*rand7*rand7*...)%10+1,有些計算確實能夠達到很好的均勻度,但卻是近似均勻。
從統計學的角度看, 一個rand7就相當於符合均勻分佈的隨機變數X1,當n個rand7做運算的時候,相當於X1...Xn是符合均勻分佈的邊緣隨機變數,而F(X1, X2,...,Xn)是他們的聯合分佈
1) 對rand7的一元運算只能有7種結果,不可能產生10個隨機數 2) 現在有二元運算(X)可以是加減乘除或者任何函式任何對映關係,rand7(X)rand7的可能運算方式是7*7種,,n次二元(X)運算後的可能是運算方式是7^(n+1)種,現在要用7^(n+1)種運算過程得到均勻的10種結果,這是不可能的,(因為7^(n+1)不能被10整除),所以只能是近似均勻
下面來看怎樣獲得近似的均勻, ju136提醒我注意到,其中的一個比較好的方法是: (rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7())%10+1 他獲得的均勻度非常好,1出現的最多,5出現的最少,但是概率上僅僅相差0.00002,人類的感覺已經分辨不出來了。但是這個方法需要呼叫10次rand7,效率上差一些。
有人希望用這樣的方法:呼叫兩次rand7從而生成一個7進位制的數,然後轉換成0-49,剛好是50個數的均勻分佈,再取模10。這個方法貌似可行,可是很遺憾的是,這樣生成的7進位制0-66對應到10進位制是0-48,而不是49,少了一個數。
下面這個方法也比較好,(rand7+(rand7+7) +(rand7+14)+...+(rand7+42))%10,這個表示式生成7個隨機數,分別均勻分佈在1-7,8-14,...7個區間,相加之後再做模10運算,對映到0-9這10個數字。這7^7種運算,統計每個數字可以得到次數,其中5最高,0最低,但是他們機率的差僅為0.00041,人的感覺幾乎分辨不出來了。這個方法需要呼叫7次rand7,效率比上面的程式碼高一些,因此有: 程式碼3
{
return (rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+147)%10+1;
}
這種直接方法,無論怎樣在理論上都做不到均勻分佈,所以,我們要想一些辦法來提高。
3. 直接法——利用組合方法進一步提高
考慮陣列 {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} {6, 5, 4, 3, 2, 1, 10, 9, 8, 7 }
用rand7_plus在第一行中選擇的時候6的機會最大,1的機會最小,但是在第二行選擇的時候1的機會最大,6的機會最小,這兩行有一定的互補性,所以如果輪流選擇這兩行,會得到更均勻的分佈,根據上面的計數結果,可以得知,最小几率與最大機率的差僅為萬分之一。推廣一下,如果在陣列 int seed10[10][10] = {
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10},
{10, 1, 2, 3, 4, 5, 6, 7, 8, 9},
{9, 10, 1, 2, 3, 4, 5, 6, 7, 8 },
{8, 9, 10, 1, 2, 3, 4, 5, 6, 7 },
{7, 8, 9, 10, 1, 2, 3, 4, 5, 6 },
{6, 7, 8, 9, 10, 1, 2, 3, 4, 5 },
{5, 6, 7, 8, 9, 10, 1, 2, 3, 4 },
{4, 5, 6, 7, 8, 9, 10, 1, 2, 3 },
{3, 4, 5, 6, 7, 8, 9, 10, 1, 2 },
{2, 3, 4, 5, 6, 7, 8, 9, 10, 1 },
}; 之中,依次在每一行用rand10_7plus選擇,由於每個數字出現的機率均等,並且在每行和每列上出現的機率均等,在多次呼叫之後就可以得到均勻分佈。 程式碼4 unsigned int gi =0;
int rand10_matrix()
{
//用rand10_7plus生成一個數,選擇列 int n = rand10_7plus() -1;
//輪流選擇seed10的行 return seed10[gi++%10][n];
}
如果利用模運算的迴圈性質,就不需要seed10這個矩陣,可以驗證下面的程式碼與rand10_matrix是等效的: 程式碼5 unsigned int gi =0;
int rand10_mod()
{
return ((rand10_7plus() -1) + gi++) %10+1;
} 這個演算法每次呼叫7次rand7,做一次模運算,不需要額外的記憶體以及迴圈,從統計意義上說,已經是個比較好的偽隨機數生成器。
4. 隨機數測試 最初我在些這個文章的時候,在測試方面出了問題,所以在這裡強調兩點:
1). 隨機度測試,需要每隔10次呼叫計數一次,以驗證每個數字在各個位置上出現的次數是均等的。 程式碼要與如下類似: for (k =0; k <100000; k++) {
n =0;
for (j =0; j <10; j++)
n = rand10_7plus10();
result[n -1]++;
} 注意result[n - 1]++是在j=0~10這個迴圈之外的。
2). 概率計算 在編寫程式碼之前,一定要先證明1-10的均勻分佈。例如前面10個rand連加的演算法,在人的感覺之中已經分辨不出來概率的差別了,因此需要仔細統計一下10個數字,寫一個簡單的10層迴圈計數就可以了。很多朋友忽視了這點,並且,我們上面在第2小節證明了這是不可能做到均勻的。如果想不清楚或者很難證明你的方法,於是這個最簡單的程式碼就非常有用: for (i1 =1; i1 <=7; i1++)
for (i2 =1; i2 <=7; i2++)

for (i10 =1; i10 <=7; i10++)
result[(i1 + i2 + + i10) %10]++;
5. 直接法——分佈變換與連續隨機變數的分佈——更實際的應用
除了這道題的一些技巧,題目本身在實戰中沒有任何應用,比較實際的問題是,假設一個班的學生成績符合正態分佈,如何模擬生成考試成績。
我們先看如果rand7是1-7的連續均勻分佈,如何獲得1-10的均勻分佈。答案很簡單,從幾何的角度上看,我們可以把[a,b]線段上的點按照一對一對映到另一個線段[c,d]上去,只需要做一個線性變換y=(x-a)/(b-a)*(d-c)+c. 那麼,若x=rand()~U(a,b),則y=~U(c,d),也就是如果rand()是a到b上的均勻分佈,則y=(d-c)(x-a)/(b-a)+c是c到d上的均勻分佈。對於本例rand10=(rand()-1)/6*9+1. 下面是證明,更一般的情況同理可證: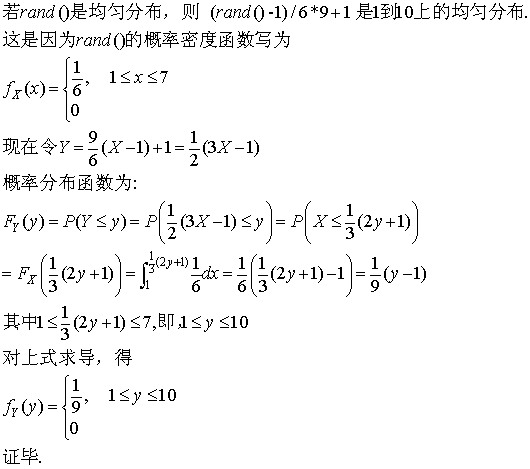
另外有一個重要的定理來表明變換之後的分佈。這可以處理如Y=X^2, Y=e^X等多種變換。定理如下:
這個定理還可以更強一些,f(x)是分段還是也可以,甚至只是一個覆蓋(包括)就可以了。從符合一種分佈的隨機數生成另外一種分佈的隨機數是統計模擬的課題,其中有非常有趣的變換方法,例如,如果X是(0,1)上的均勻分佈,則Y=-a*log(X)是指數分佈。
現在來回答如何按照正態分佈模擬生成一個班的學生成績。這個方法被稱為Box-Muller演算法,如果U1和U2服從 (0,1)區間的均勻分佈,做變換R=sqrt(-2*logU1), alpha=2*pi*U2,則X=Rcos(alpha)和Y=Rsin(alpha)是一對獨立的 標準正態分佈n(0,1)。證明從略。按照這個方法,C語言的rand(),可以模擬生成近似的(0,1)均勻分佈,只要rand()/MAX_RAND就可以了,做Box-Muller變換到n(0,1),就可以做出符合學生成績分佈了,概率統計課的基礎內容就有。
6. 其他方法
捨去法也是非常重要的一類隨機,用來生成各種分佈的隨機數,另外的方法:比如Metropolis演算法,比較著名的還有Markov Chain Monte Carlo (MCMC)演算法,這類方法可以看成是一個黑盒子,要求在演算法內部通過幾次運算很快收斂到一種概率分佈,然後返回一個隨機數。
7. 參考文獻 [2] Kunth第2卷Seminumerical Algorithms, Random Numbers.
由於捨去法每次呼叫rand7的次數未知,所以希望能夠找到一種直接的方法。當然最直接的方法就是用線性同餘這樣的隨機數生成法直接寫一個,但是這就用不上rand7了,與題意不符合。有人希望用rand7的各種組合計算來完成,比如(rand7+rand7+rand7+...)%10+1或者(rand7*rand7*rand7*...)%10+1,有些計算確實能夠達到很好的均勻度,但卻是近似均勻。
從統計學的角度看, 一個rand7就相當於符合均勻分佈的隨機變數X1,當n個rand7做運算的時候,相當於X1...Xn是符合均勻分佈的邊緣隨機變數,而F(X1, X2,...,Xn)是他們的聯合分佈
1) 對rand7的一元運算只能有7種結果,不可能產生10個隨機數 2) 現在有二元運算(X)可以是加減乘除或者任何函式任何對映關係,rand7(X)rand7的可能運算方式是7*7種,,n次二元(X)運算後的可能是運算方式是7^(n+1)種,現在要用7^(n+1)種運算過程得到均勻的10種結果,這是不可能的,(因為7^(n+1)不能被10整除),所以只能是近似均勻
下面來看怎樣獲得近似的均勻, ju136提醒我注意到,其中的一個比較好的方法是: (rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7())%10+1 他獲得的均勻度非常好,1出現的最多,5出現的最少,但是概率上僅僅相差0.00002,人類的感覺已經分辨不出來了。但是這個方法需要呼叫10次rand7,效率上差一些。
有人希望用這樣的方法:呼叫兩次rand7從而生成一個7進位制的數,然後轉換成0-49,剛好是50個數的均勻分佈,再取模10。這個方法貌似可行,可是很遺憾的是,這樣生成的7進位制0-66對應到10進位制是0-48,而不是49,少了一個數。
下面這個方法也比較好,(rand7+(rand7+7) +(rand7+14)+...+(rand7+42))%10,這個表示式生成7個隨機數,分別均勻分佈在1-7,8-14,...7個區間,相加之後再做模10運算,對映到0-9這10個數字。這7^7種運算,統計每個數字可以得到次數,其中5最高,0最低,但是他們機率的差僅為0.00041,人的感覺幾乎分辨不出來了。這個方法需要呼叫7次rand7,效率比上面的程式碼高一些,因此有: 程式碼3
{
return (rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+147)%10+1;
}
這種直接方法,無論怎樣在理論上都做不到均勻分佈,所以,我們要想一些辦法來提高。
3. 直接法——利用組合方法進一步提高
考慮陣列 {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} {6, 5, 4, 3, 2, 1, 10, 9, 8, 7 }
用rand7_plus在第一行中選擇的時候6的機會最大,1的機會最小,但是在第二行選擇的時候1的機會最大,6的機會最小,這兩行有一定的互補性,所以如果輪流選擇這兩行,會得到更均勻的分佈,根據上面的計數結果,可以得知,最小几率與最大機率的差僅為萬分之一。推廣一下,如果在陣列 int seed10[10][10] = {
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10},
{10, 1, 2, 3, 4, 5, 6, 7, 8, 9},
{9, 10, 1, 2, 3, 4, 5, 6, 7, 8 },
{8, 9, 10, 1, 2, 3, 4, 5, 6, 7 },
{7, 8, 9, 10, 1, 2, 3, 4, 5, 6 },
{6, 7, 8, 9, 10, 1, 2, 3, 4, 5 },
{5, 6, 7, 8, 9, 10, 1, 2, 3, 4 },
{4, 5, 6, 7, 8, 9, 10, 1, 2, 3 },
{3, 4, 5, 6, 7, 8, 9, 10, 1, 2 },
{2, 3, 4, 5, 6, 7, 8, 9, 10, 1 },
}; 之中,依次在每一行用rand10_7plus選擇,由於每個數字出現的機率均等,並且在每行和每列上出現的機率均等,在多次呼叫之後就可以得到均勻分佈。 程式碼4 unsigned int gi =0;
int rand10_matrix()
{
//用rand10_7plus生成一個數,選擇列 int n = rand10_7plus() -1;
//輪流選擇seed10的行 return seed10[gi++%10][n];
}
如果利用模運算的迴圈性質,就不需要seed10這個矩陣,可以驗證下面的程式碼與rand10_matrix是等效的: 程式碼5 unsigned int gi =0;
int rand10_mod()
{
return ((rand10_7plus() -1) + gi++) %10+1;
} 這個演算法每次呼叫7次rand7,做一次模運算,不需要額外的記憶體以及迴圈,從統計意義上說,已經是個比較好的偽隨機數生成器。
4. 隨機數測試 最初我在些這個文章的時候,在測試方面出了問題,所以在這裡強調兩點:
1). 隨機度測試,需要每隔10次呼叫計數一次,以驗證每個數字在各個位置上出現的次數是均等的。 程式碼要與如下類似: for (k =0; k <100000; k++) {
n =0;
for (j =0; j <10; j++)
n = rand10_7plus10();
result[n -1]++;
} 注意result[n - 1]++是在j=0~10這個迴圈之外的。
2). 概率計算 在編寫程式碼之前,一定要先證明1-10的均勻分佈。例如前面10個rand連加的演算法,在人的感覺之中已經分辨不出來概率的差別了,因此需要仔細統計一下10個數字,寫一個簡單的10層迴圈計數就可以了。很多朋友忽視了這點,並且,我們上面在第2小節證明了這是不可能做到均勻的。如果想不清楚或者很難證明你的方法,於是這個最簡單的程式碼就非常有用: for (i1 =1; i1 <=7; i1++)
for (i2 =1; i2 <=7; i2++)
for (i10 =1; i10 <=7; i10++)
result[(i1 + i2 +
+ i10) %10]++;
5. 直接法——分佈變換與連續隨機變數的分佈——更實際的應用
除了這道題的一些技巧,題目本身在實戰中沒有任何應用,比較實際的問題是,假設一個班的學生成績符合正態分佈,如何模擬生成考試成績。
我們先看如果rand7是1-7的連續均勻分佈,如何獲得1-10的均勻分佈。答案很簡單,從幾何的角度上看,我們可以把[a,b]線段上的點按照一對一對映到另一個線段[c,d]上去,只需要做一個線性變換y=(x-a)/(b-a)*(d-c)+c. 那麼,若x=rand()~U(a,b),則y=~U(c,d),也就是如果rand()是a到b上的均勻分佈,則y=(d-c)(x-a)/(b-a)+c是c到d上的均勻分佈。對於本例rand10=(rand()-1)/6*9+1. 下面是證明,更一般的情況同理可證:
另外有一個重要的定理來表明變換之後的分佈。這可以處理如Y=X^2, Y=e^X等多種變換。定理如下:
這個定理還可以更強一些,f(x)是分段還是也可以,甚至只是一個覆蓋(包括)就可以了。從符合一種分佈的隨機數生成另外一種分佈的隨機數是統計模擬的課題,其中有非常有趣的變換方法,例如,如果X是(0,1)上的均勻分佈,則Y=-a*log(X)是指數分佈。
現在來回答如何按照正態分佈模擬生成一個班的學生成績。這個方法被稱為Box-Muller演算法,如果U1和U2服從 (0,1)區間的均勻分佈,做變換R=sqrt(-2*logU1), alpha=2*pi*U2,則X=Rcos(alpha)和Y=Rsin(alpha)是一對獨立的 標準正態分佈n(0,1)。證明從略。按照這個方法,C語言的rand(),可以模擬生成近似的(0,1)均勻分佈,只要rand()/MAX_RAND就可以了,做Box-Muller變換到n(0,1),就可以做出符合學生成績分佈了,概率統計課的基礎內容就有。
6. 其他方法
捨去法也是非常重要的一類隨機,用來生成各種分佈的隨機數,另外的方法:比如Metropolis演算法,比較著名的還有Markov Chain Monte Carlo (MCMC)演算法,這類方法可以看成是一個黑盒子,要求在演算法內部通過幾次運算很快收斂到一種概率分佈,然後返回一個隨機數。
7. 參考文獻 [2] Kunth第2卷Seminumerical Algorithms, Random Numbers.