
既生 Redis 何生 LevelDB?
瞭解 Redis 的同學都知道它是一個純記憶體的資料庫,憑藉優秀的併發和易用性打下了網際網路項的半壁江山。Redis 之所以高效能是因為它的純記憶體訪問特性,而這也成了它致命的弱點 —— 記憶體的成本太高。所以在絕大多數場合,它比較適合用來做快取,長期不被訪問的冷資料被淘汰掉,只有熱的資料快取在記憶體中,這樣就不會浪費太多昂貴的記憶體空間。
但是 Redis 的誘惑太大了,用它來做持久儲存使用起來太方便了。要是記憶體的價格低廉,真恨不得把所有的資料都堆到 Redis 中,但是技術的選擇總是要考慮到現實世界的成本問題。那如何才能享受到 Redis 作為持久層易用性的同時還可以節省記憶體成本呢?
LevelDB 來了!

它是 Google 開源的 NOSQL 儲存引擎庫,是現代分散式儲存領域的一枚原子彈。在它的基礎之上,Facebook 開發出了另一個 NOSQL 儲存引擎庫 RocksDB,沿用了 LevelDB 的先進技術架構的同時還解決了 LevelDB 的一些短板。你可以將 RocksDB 比喻成氫彈,它比 LevelDB 的威力更大一些。現代開源市場上有很多資料庫都在使用 RocksDB 作為底層儲存引擎,比如大名鼎鼎的 TiDB。

但是為什麼我要講 LevelDB 而不是 RocksDB 呢?其原因在於 LevelDB 技術架構更加簡單清晰易於理解。如果我們先把 LevelDB 吃透了再去啃一啃 RocksDB 就會非常好懂了,RocksDB 也只是在 LevelDB 的基礎上添磚加瓦進行了一系列優化而已。等到我們攻破了 RocksDB 這顆氫彈,TiDB 核動力宇宙飛船已經在前方不遠處等著我們了。
Redis 快取有什麼問題?
當我們將 Redis 拿來做快取用時,背後肯定還有一個持久層資料庫記錄了全量的冷熱資料。Redis 和持久層資料庫之間的資料一致性是由應用程式自己來控制的。應用程式會優先去快取中獲取資料,當快取中沒有資料時,應用程式需要從持久層載入資料,然後再放進快取中。當資料更新發生時,需要將快取置為失效。
function getUser(String userId) User {
User user = redis.get(userId);
if user == null {
user = db.get(userId);
if user != null {
redis.set(userId, user);
}
}
return user;
}
function updateUser(String userId, User user) {
db.update(userId, user);
redis.expire(userId);
}
有過這方面開發經驗的朋友們就知道寫這樣的程式碼還是挺繁瑣的,所有的涉及到快取的業務程式碼都需要加上這一部分邏輯。
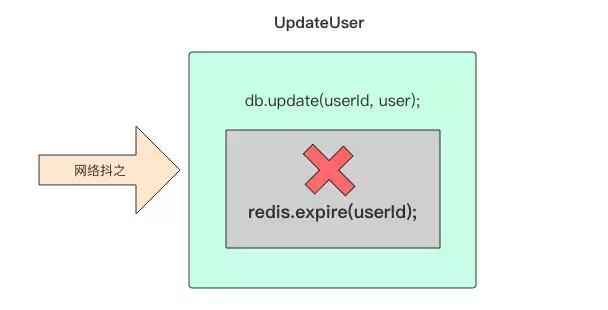
嚴格來說我們還需要仔細考慮快取一致性問題,比如在 updateUser 方法中,資料庫正確執行了更新,但是快取 redis 因為網路抖動等原因置為失效沒有成功,那麼快取中的資料就成了過期資料。如果你將設定快取和更新持久存的先後順序反過來,也還是會有其它問題,這個讀者可以自行思考一下。
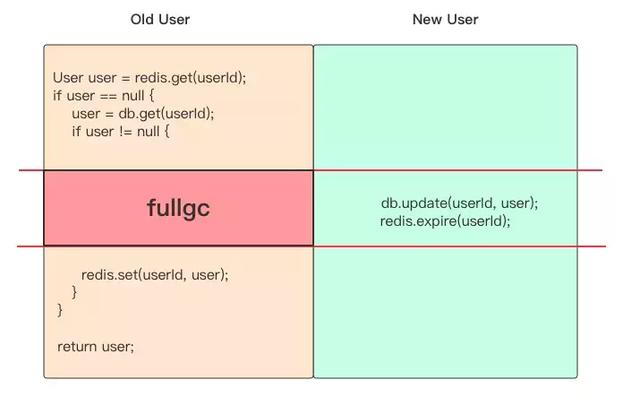
在多程序高併發場合也會導致快取不一致,比如一個程序對某個 userId 呼叫 getUser() 方法,因為快取裡沒有,它需要從資料庫里加載。結果剛剛加載出來,正準備要設定快取,這時候發生了記憶體 fullgc 程式碼暫停了一會,而正在此時另一個程序呼叫了 updateUser 方法更新了資料庫,將快取置為失效(其實快取裡本來就沒有資料)。然後前面那個程序終於 fullgc 結束要開始設定快取了,這時候進快取的就是過期的資料。
LevelDB 是如何解決的?
LevelDB 將 Redis 快取和持久層合二為一,一次性幫你搞定快取和持久層。有了 LevelDB,你的程式碼可以簡化成下面這樣
function getUser(String userId) User {
return leveldb.get(userId);
}
function updateUser(String userId, User user) {
leveldb.set(userId, user);
}
而且你再也不用當心快取一致性問題了,LevelDB 的資料更新要麼成功要麼不成功,不存在中間薛定諤狀態。LevelDB 的內部已經內建了記憶體快取和持久層的磁碟檔案,使用者完全不用操心內部是資料如何保持一致的。
LevelDB 具體是什麼?
前面我們說道它是一個 NOSQL 儲存引擎,它和 Redis 不是一個概念。Redis 是一個完備的資料庫,而 LevelDB 它只是一個引擎。如果將資料庫比喻成一輛高階跑車,那麼儲存引擎就是它的發動機,是核心是心臟。有了這個發動機,我們再給它包裝上一系列的配件和裝飾,就可以成為資料庫。不過也不要小瞧了配件和裝飾,做到極致那也是非常困難,將 LevelDB 包裝成一個簡單易用的資料庫需要加上太多太多精緻的配件。LevelDB 和 RocksDB 出來這麼多年,能夠在它的基礎上做出非常一個完備的生產級資料庫寥寥無幾。
歡迎Java工程師朋友們加入Java進階架構學習交流:952124565,本群提供免費的學習指導 架構資料 以及解答,不懂得問題都可以在本群提出來 。
在使用 LevelDB 時,我們還可以將它看成一個 Key/Value 記憶體資料庫。它提供了基礎的 Get/Set API,我們在程式碼裡可以通過這個 API 來讀寫資料。你還可以將它看成一個無限大小的高階 HashMap,我們可以往裡面塞入無限條 Key/Value 資料,只要磁碟可以裝下。
正是因為它只能算作一個記憶體資料庫,它裡面裝的資料無法跨程序跨機器共享。在分散式領域,LevelDB 要如何大顯身手呢?
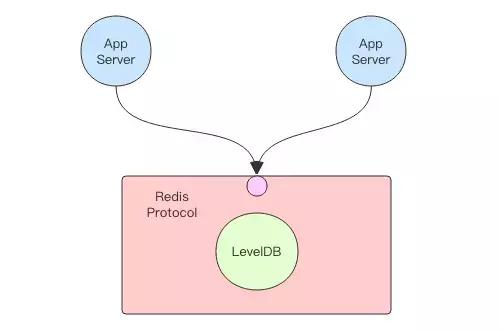
這就需要靠包裝技術了,在 LevelDB 記憶體資料庫的基礎上包裝一層網路 API。當不同機器上不同的程序要來訪問它時,都統一走網路 API 介面。這樣就形成了一個簡易的資料庫。如果在網路層我們使用 Redis 協議來包裝,那麼使用 Redis 的客戶端就可以讀寫這個資料庫了。
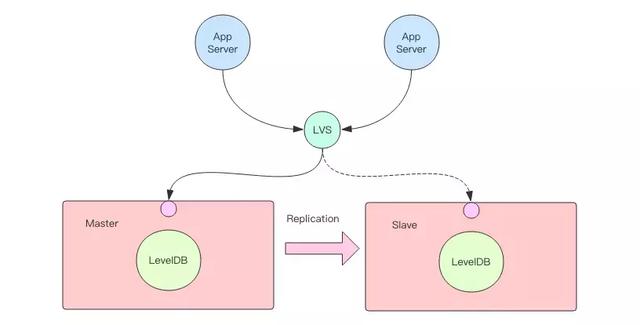
如果要考慮資料庫的高可用性,我們在上面這個單機資料庫的基礎上再加上主從複製功能就可以變身成為一個主從結構的分散式 NOSQL 資料庫。在主從資料庫前面加一層轉發代理(負載均衡器如 LVS、F5 等),就可以實現主從的實時切換。
如果你需要的資料容量特別大以至於單個機器的硬碟都容不下,這時候就需要資料分片機制將整個資料庫的資料分散到多臺機器上,每臺機器只負責一部分資料的讀寫工作。資料分片的方案非常多,可以像 Codis 那樣通過轉發代理來分片,也可以像 Redis-Cluster 那樣使用客戶端轉發機制來分片,還可以使用 TiDB 的 Raft 分散式一致性演算法來分組管理分片。最簡單最易於理解的還是要數 Codis 的轉發代理分片。
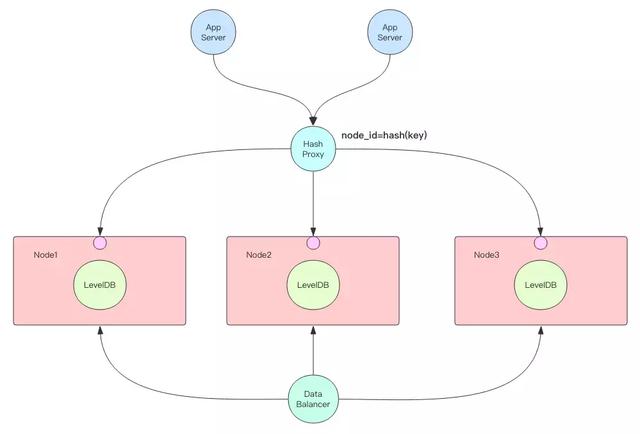
當資料量繼續增長需要新增節點時,就必須將老節點上的資料部分遷移到新節點上,管理資料的均衡和遷移的又是一個新的高階配件 —— 資料均衡器。
看到這裡我相信讀者從整體上理解了分散式資料庫中 LevelDB 所處的地位。下一次我們開始全面瞭解一下 LevelDB 的記憶體資料庫特性。
歡迎工作一到八年的Java工程師朋友們加入Java進階架構學習交流:952124565
群內提供免費的Java架構學習資料(裡面有高可用、高併發、高效能及分散式、Jvm效能調優、Spring原始碼,
MyBatis,Netty,Redis,Kafka,Mysql,Zookeeper,Tomcat,Docker,Dubbo,Nginx等多個知識點的架構資料)
合理利用自己每一分每一秒的時間來學習提升自己,不要再用"沒有時間“來掩飾自己思想上的懶惰!趁年輕,使勁拼,給未來的自己一個交代!