
深度學習一:搭建簡單的全連線神經網路
深度學習一:搭建簡單的全連線神經網路
新手入門學習神經網路,嘗試搭建淺層的全連線神經網路,廢話不多說,上主題(文章左後會貼上全部程式碼):
實驗環境:Python3+Pycharm
一個神經網路分為輸入層、隱藏和輸出層,先實現一個單隱藏層的神經網路,輸入為隨機向量x,通過神經網路,擬合隨機向量y。將神經網路的訓練拆成兩部分,即向前傳播和反向傳播,分別用函式實現。
首先是引入:
import numpy as np
import matplotlib.pyplot as plt使用numpy來做多種運算,使用matplotlib來畫圖
向前傳播:
輸入input向量x、引數w1、w2和偏置b1、b2,z1是隱藏層的中間輸出,A1是經過sigmoid啟用後的輸出。
假定輸入x的維度為n*m,w1的維度為h*n(表示該層的神經元為h個),w2的維度為1*h,最終輸出的A2維度為1*m。使用numpy中的dot()函式來做矩陣運算。
def forward(X, w1, w2, b1, b2): z1 = np.dot(w1, X) + b1 # w1=h*n X=n*m z1=h*m A1 = sigmoid(z1) # A1=h*m z2 = np.dot(w2, A1) + b2 # w2=1*h z2=1*m A2 = sigmoid(z2) # A2=1*m return z1, z2, A1, A2
這裡需要先定義一下啟用函式:
def sigmoid(z):
return 1 / (1 + np.exp(-z))反向傳播:
計算引數的偏導數
def backward(y, X, A2, A1, z2, z1, w2, w1): n, m = np.shape(X) dz2 = A2 - y # A2=1*m y=1*m dw2 = 1 / m * np.dot(dz2, A1.T) # dz2=1*m A1.T=m*h dw2=1*h db2 = 1 / m * np.sum(dz2, axis=1, keepdims=True) dz1 = np.dot(w2.T, dz2) * A1 * (1 - A1) # w2.T=h*1 dz2=1*m z1=h*m A1=h*m dz1=h*m dw1 = 1 / m * np.dot(dz1, X.T) # z1=h*m X'=m*n dw1=h*n db1 = 1 / m * np.sum(dz1, axis=1, keepdims=True) return dw1, dw2, db1, db2
定義完了訓練的向前傳播和反向傳播,還需要定義一個損失函式:
def costfunction(A2, y):
m, n = np.shape(y)
J = np.sum(y * np.log(A2) + (1 - y) * np.log(1 - A2)) / m
# J = (np.dot(y, np.log(A2.T)) + np.dot((1 - y).T, np.log(1 - A2))) / m
return -Jok,到這裡一個神經網路的框架基本有了,在開始訓練之前,還需要定義一下各個引數並初始化。
首先是輸入x和擬合數據y:
X=np.random.rand(100,200)
n, m = np.shape(X)
y=np.random.rand(1,m)由於是初步搭建,這裡的x和y均採用隨機變數,大概體驗一下神經網路即可。隨機初試化一個維度為[100,200]的x和[1,200]的y。
接下來,定義各個引數:
n_x = n # size of the input layer
n_y = 1 # size of the output layer
n_h = 5 # size of the hidden layer
w1 = np.random.randn(n_h, n_x) * 0.01 # h*n
b1 = np.zeros((n_h, 1)) # h*1
w2 = np.random.randn(n_y, n_h) * 0.01 # 1*h
b2 = np.zeros((n_y, 1))
alpha = 0.1
number = 10000定義隱藏層的神經元個數為5,隨機初始化w1、w2、b1和b2,定義學習率alpha為0.1,迭代次數為10000
之後,便可以開始訓練了:
for i in range(0, number):
z1, z2, A1, A2 = forward(X, w1, w2, b1, b2)
dw1, dw2, db1, db2 = backward(y, X, A2, A1, z2, z1, w2, w1)
w1 = w1 - alpha * dw1
w2 = w2 - alpha * dw2
b1 = b1 - alpha * db1
b2 = b2 - alpha * db2
J = costfunction(A2, y)
if (i % 100 == 0):
print(i)
plt.plot(i, J, 'ro')
plt.show()使用梯度下降的方法來最小化損失函式,每次迭代後,描點損失函式J的值。
全部程式碼如下:
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def forward(X, w1, w2, b1, b2):
z1 = np.dot(w1, X) + b1 # w1=h*n X=n*m z1=h*m
A1 = sigmoid(z1) # A1=h*m
z2 = np.dot(w2, A1) + b2 # w2=1*h z2=1*m
A2 = sigmoid(z2) # A2=1*m
return z1, z2, A1, A2
def backward(y, X, A2, A1, z2, z1, w2, w1):
n, m = np.shape(X)
dz2 = A2 - y # A2=1*m y=1*m
dw2 = 1 / m * np.dot(dz2, A1.T) # dz2=1*m A1.T=m*h dw2=1*h
db2 = 1 / m * np.sum(dz2, axis=1, keepdims=True)
dz1 = np.dot(w2.T, dz2) * A1 * (1 - A1) # w2.T=h*1 dz2=1*m z1=h*m A1=h*m dz1=h*m
dw1 = 1 / m * np.dot(dz1, X.T) # z1=h*m X'=m*n dw1=h*n
db1 = 1 / m * np.sum(dz1, axis=1, keepdims=True)
return dw1, dw2, db1, db2
def costfunction(A2, y):
m, n = np.shape(y)
J = np.sum(y * np.log(A2) + (1 - y) * np.log(1 - A2)) / m
# J = (np.dot(y, np.log(A2.T)) + np.dot((1 - y).T, np.log(1 - A2))) / m
return -J
# Data = np.loadtxt("gua2.txt")
# X = Data[:, 0:-1]
# X = X.T
# y = Data[:, -1]
X=np.random.rand(100,200)
n, m = np.shape(X)
y=np.random.rand(1,m)
#y = y.reshape(1, m)
n_x = n # size of the input layer
n_y = 1 # size of the output layer
n_h = 5 # size of the hidden layer
w1 = np.random.randn(n_h, n_x) * 0.01 # h*n
b1 = np.zeros((n_h, 1)) # h*1
w2 = np.random.randn(n_y, n_h) * 0.01 # 1*h
b2 = np.zeros((n_y, 1))
alpha = 0.1
number = 10000
for i in range(0, number):
z1, z2, A1, A2 = forward(X, w1, w2, b1, b2)
dw1, dw2, db1, db2 = backward(y, X, A2, A1, z2, z1, w2, w1)
w1 = w1 - alpha * dw1
w2 = w2 - alpha * dw2
b1 = b1 - alpha * db1
b2 = b2 - alpha * db2
J = costfunction(A2, y)
if (i % 100 == 0):
print(i)
plt.plot(i, J, 'ro')
plt.show()執行後的實驗結果:
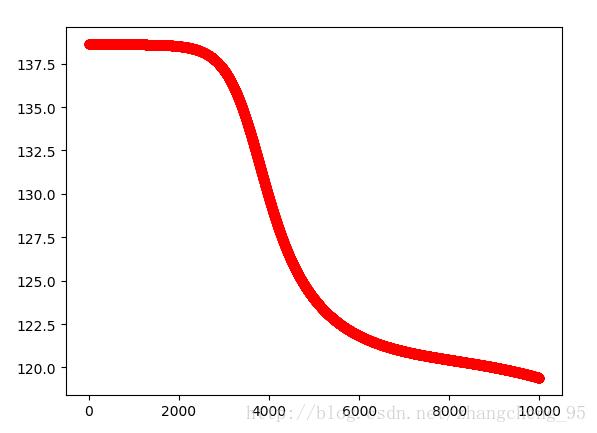
可以看到隨著迭代次數的增加,損失函式是逐漸減小的。
補充(稍加改進版):
在原有的基礎上,加入一層隱藏層:
補充定義:
n_x=n
n_y=1
n_h1=5
n_h2=4
W1=np.random.rand(n_x,n_h1)*0.01
W2=np.random.rand(n_h1,n_h2)*0.01
W3=np.random.rand(n_h2,n_y)*0.01
b1=np.zeros((n_h1,1))
b2=np.zeros((n_h2,1))
b3=np.zeros((n_y,1))將新的隱藏層的神經元個數定義n_h2=4
向前傳播:
# 向前傳遞
def forward(X, W1, W2, W3, b1, b2, b3):
# 隱藏層1
Z1 = np.dot(W1.T,X)+b1 # X=n*m ,W1.T=h1*n,b1=h1*1,Z1=h1*m
A1 = sigmoid(Z1) # A1=h1*m
# 隱藏層2
Z2 = np.dot(W2.T, A1) + b2 # W2.T=h2*h1,b2=h2*1,Z2=h2*m
A2 = sigmoid(Z2) # A2=h2*m
# 輸出層
Z3=np.dot(W3.T,A2)+b3 # W3.T=(h3=1)*h2,b3=(h3=1)*1,Z3=1*m
A3=sigmoid(Z3) # A3=1*m
return Z1,Z2,Z3,A1,A2,A3反向傳播:
# 反向傳播
def backward(Y,X,A3,A2,A1,Z3,Z2,Z1,W3,W2,W1):
n,m = np.shape(X)
dZ3 = A3-Y # dZ3=1*m
dW3 = 1/m *np.dot(A2,dZ3.T) # dW3=h2*1
db3 = 1/m *np.sum(dZ3,axis=1,keepdims=True) # db3=1*1
dZ2 = np.dot(W3,dZ3)*A2*(1-A2) # dZ2=h2*m
dW2 = 1/m*np.dot(A1,dZ2.T) #dw2=h1*h2
db2 = 1/m*np.sum(dZ2,axis=1,keepdims=True) #db2=h2*1
dZ1 = np.dot(W2, dZ2) * A1 * (1 - A1) # dZ1=h1*m
dW1 = 1 / m * np.dot(X, dZ1.T) # dW1=n*h
db1 = 1 / m * np.sum(dZ1,axis=1,keepdims=True) # db1=h*m
return dZ3,dZ2,dZ1,dW3,dW2,dW1,db3,db2,db1for i in range(0,number):
Z1,Z2,Z3,A1,A2,A3=forward(X,W1,W2,W3,b1,b2,b3)
dZ3, dZ2, dZ1, dW3, dW2, dW1, db3, db2, db1=backward(Y,X,A3,A2,A1,Z3,Z2,Z1,W3,W2,W1)
W1=W1-alpha*dW1
W2=W2-alpha*dW2
W3=W3-alpha*dW3
b1=b1-alpha*db1
b2=b2-alpha*db2
b3=b3-alpha*db3
J=costfunction(Y,A3)可以說改動不是很大,如果需要更深層次的神經網路,按這個方法新增就可以了,當然,如果層次太多,程式碼還是顯得太過繁瑣。
修改後的全部程式碼如下:
import numpy as np
import matplotlib.pyplot as plt
# 啟用函式
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 向前傳遞
def forward(X, W1, W2, W3, b1, b2, b3):
# 隱藏層1
Z1 = np.dot(W1.T,X)+b1 # X=n*m ,W1.T=h1*n,b1=h1*1,Z1=h1*m
A1 = sigmoid(Z1) # A1=h1*m
# 隱藏層2
Z2 = np.dot(W2.T, A1) + b2 # W2.T=h2*h1,b2=h2*1,Z2=h2*m
A2 = sigmoid(Z2) # A2=h2*m
# 輸出層
Z3=np.dot(W3.T,A2)+b3 # W3.T=(h3=1)*h2,b3=(h3=1)*1,Z3=1*m
A3=sigmoid(Z3) # A3=1*m
return Z1,Z2,Z3,A1,A2,A3
# 反向傳播
def backward(Y,X,A3,A2,A1,Z3,Z2,Z1,W3,W2,W1):
n,m = np.shape(X)
dZ3 = A3-Y # dZ3=1*m
dW3 = 1/m *np.dot(A2,dZ3.T) # dW3=h2*1
db3 = 1/m *np.sum(dZ3,axis=1,keepdims=True) # db3=1*1
dZ2 = np.dot(W3,dZ3)*A2*(1-A2) # dZ2=h2*m
dW2 = 1/m*np.dot(A1,dZ2.T) #dw2=h1*h2
db2 = 1/m*np.sum(dZ2,axis=1,keepdims=True) #db2=h2*1
dZ1 = np.dot(W2, dZ2) * A1 * (1 - A1) # dZ1=h1*m
dW1 = 1 / m * np.dot(X, dZ1.T) # dW1=n*h
db1 = 1 / m * np.sum(dZ1,axis=1,keepdims=True) # db1=h*m
return dZ3,dZ2,dZ1,dW3,dW2,dW1,db3,db2,db1
def costfunction(Y,A3):
m, n = np.shape(Y)
J=np.sum(Y*np.log(A3)+(1-Y)*np.log(1-A3))/m
# J = (np.dot(y, np.log(A2.T)) + np.dot((1 - y).T, np.log(1 - A2))) / m
return -J
# Data = np.loadtxt("gua2.txt")
# X = Data[:, 0:-1]
# X = X.T
# Y = Data[:, -1]
# Y=np.reshape(1,m)
X=np.random.rand(100,200)
n,m=np.shape(X)
Y=np.random.rand(1,m)
n_x=n
n_y=1
n_h1=5
n_h2=4
W1=np.random.rand(n_x,n_h1)*0.01
W2=np.random.rand(n_h1,n_h2)*0.01
W3=np.random.rand(n_h2,n_y)*0.01
b1=np.zeros((n_h1,1))
b2=np.zeros((n_h2,1))
b3=np.zeros((n_y,1))
alpha=0.1
number=10000
for i in range(0,number):
Z1,Z2,Z3,A1,A2,A3=forward(X,W1,W2,W3,b1,b2,b3)
dZ3, dZ2, dZ1, dW3, dW2, dW1, db3, db2, db1=backward(Y,X,A3,A2,A1,Z3,Z2,Z1,W3,W2,W1)
W1=W1-alpha*dW1
W2=W2-alpha*dW2
W3=W3-alpha*dW3
b1=b1-alpha*db1
b2=b2-alpha*db2
b3=b3-alpha*db3
J=costfunction(Y,A3)
if (i%100==0):
print(i)
plt.plot(i,J,'ro')
plt.show()執行結果:
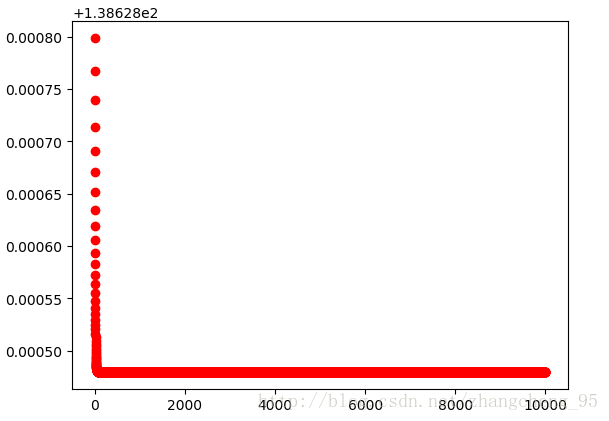
可以看到這個損失函式的下降就比較快了,因為只是簡單的隨機資料,兩層的神經網路相對來說也比較“深”了。