
深度學習一:深度前饋網路
阿新 • • 發佈:2020-09-22
# 簡述
- **深度前饋網路(deep feedforward network)**, 又叫**前饋神經網路(feedforward neural network)**和**多層感知機(multilayer perceptron, MLP)** .
- 深度前饋網路之所以被稱為**網路**(network),因為它們通常由許多不同的符合函式組合在一起來表示。
- 由**輸入層**(input layer)、**隱藏層**(hidden layer)、**輸出層**(output layer)構成。
- 隱藏層的維數決定了模型的**寬度**(width)。
如圖,這是一個經典的**二層神經網路模型(Two-Layer Neural Network)**。通常輸入層和輸出層神經元的個數是固定的,我們需要選擇和調整隱藏層的層數和每一層神經元的個數等。
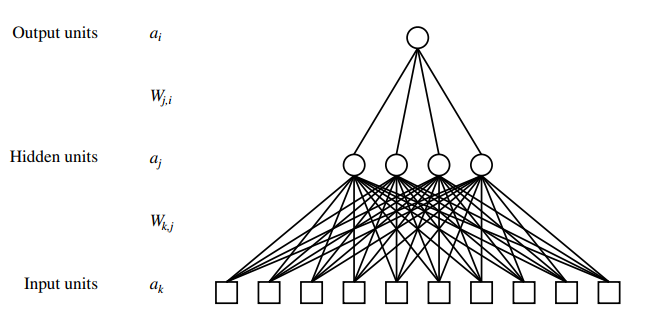
注:我們可以利用矩陣乘法來迅速計算神經網路的輸出,後面不會提及。可以參考Python神經網路程式設計(拉希德著)這本書,寫的非常簡潔。
# 線性分類問題
所有資料樣本是線性可分的,即滿足一個形如 $w_0+w_1x_1+w_2x_2$的線性方程的劃分
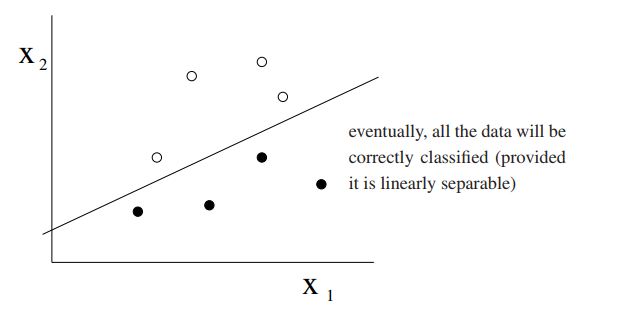
## 線性分類問題的侷限
我們引入經典的邏輯運算來推理線性分類問題的侷限。
如圖所示,分別為線性模型來表示 AND,OR 邏輯,那麼XOR要怎麼表示呢?
由圖可知:我們可以利用線性模型擬合出一個直線來表示 AND、OR、NOR 的邏輯運算,但是沒有辦法用一條直線表示 xor 異或邏輯,這就是一個經典的**非線性問題**!

注:黑色點是positive(1)的點,白色點是negative(0)的點
從邏輯運算的視角來看:
| 邏輯 | 1 1 | 0 1 | 1 0 | 0 0 |
| ---- | ----------- | ----------- | ----------- | ----------- |
| AND | 1 AND 1 = 1 | 0 AND 1 = 0 | 1 AND 0 = 0 | 0 AND 0 = 0 |
| OR | 1 OR 1 = 1 | 0 OR 1 = 1 | 1 OR 0 = 1 | 0 OR 0 = 0 |
| NOR | 1 NOR 1 = 0 | 0 NOR 1 = 0 | 1 NOR 0 = 0 | 0 XOR 0 = 1 |
| XOR | 1 XOR 1 = 0 | 0 XOR 1 = 1 | 1 XOR 0 = 1 | 0 XOR 0 = 0 |
我們可以利用如下圖所示的一個神經元的感知機來表示一個邏輯 and/or/nor,即每一個神經元可以擬合出一條直線:

## 解決線性問題的侷限
這裡涉及感知機(perceptron)的基本思想:多個神經元擬合多條直線,將這些直線組合在一起來劃分一個非線性的邊界。
我們來看上面的XOR邏輯,作為一個簡單的例子,發現
$$
I_1 XOR I_2
$$
可以表示為
$$
(I_1 AND I_2) NOR (I_1 NOR I_2)。
$$
根據上述公式和圖,我們可以畫出如下的多層感知機,來實現非線性劃分資料表示XOR邏輯關係。
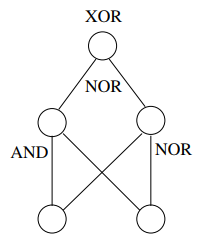
# 非線性問題常規處理手段
## 特徵非線性
引入非線性的特徵來處理非線性問題。
例如:輸入節點有表示平方的節點等。
## 模型非線性
引入非線性的啟用函式來處理非線性問題。
# 啟用函式
啟用函式(activation function)又叫轉移函式(transfer function),用來增加神經網路模型的非線性。
$$
activation_i = g(s_i) = g(\sum_{j}w_{ij}x_j)
$$
下圖是隻有一個神經元的示意圖:g函式是非線性的啟用函式。由圖中可以看出,當神經元計算出線性方程的結果s之後,傳入啟用函式g中進行處理,最終得到神經元的輸出g(s),從而實現非線性。
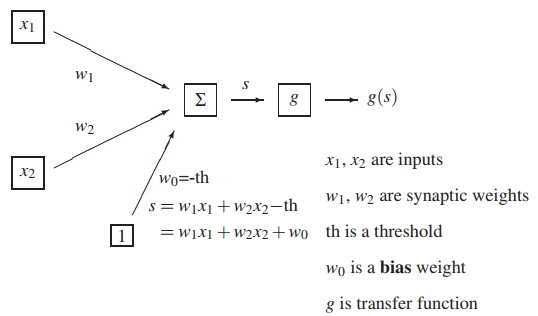
## 常用的啟用函式
### Sigmoid
S型啟用函式又叫擠壓函式,可以把任意的大小的x擠壓到(0,1)之間的y, 在x增大或者減小的過程中會逐漸出現飽和(無限趨近於0或者1)。
在二分類問題中,可以以0.5為閾值,小於0.5為一個類別,大於0.5為另一個類別。
$$
f(x) = \frac{1}{1 + e^{-x}}
$$
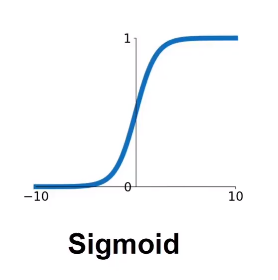
**缺點**:
1. 存在飽和現象,會導致梯度消失。
2. 優化路徑存在zig zag問題。
3. 函式使用指數運算,運算量比較大。
### Tanh
雙曲正切函式,與sigmoid函式相似,也會出現梯度飽和,但是tanh的值域為(-1,1)。
$$
tanh(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}}
$$
### Relu
線性整流函式(Rectified Linear Unit,ReLU),又稱修正線性單元。當x<0時,y為0;當x>0時,y=x。沒有飽和現象,y可以取到無窮大。
$$
f(x) = max(0,x)
$$

**優點**:
1. 運算速度比較快。
2. 不會出現飽和現象。
3. 收斂迅速。
**缺點**:
1. 當x<0,y也為0,梯度為0。即當x<0,是沒有辦法進行學習的。
### ELU
指數線性單元(Exponential Linear Unit)也是ReLU啟用函式的變體。
$$
f(x) = \begin{cases}
x & x\geq0 \\
α*(e^x-1) & x<0
\end{cases}
$$
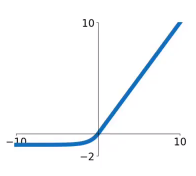
**優點**:
1. 當x<0時,曲線也有變化,不會停止學習。
**缺點**:
1. 指數運算的計算量比較大。
### Leaky ReLU
帶洩露修正線性單元(Leaky ReLU)函式是ReLU啟用函式的變體。當x<0時,y=0.1x;當x>0時,y=x。
$$
f(x) = max(αx,x)
$$
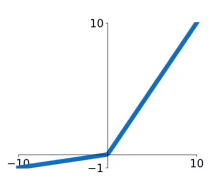
**優點**:
1. 當x<0時,曲線也有變化,不會停止學習。
2. 計算量比ELU小很多
3. x<0的斜率α可以自己設定
# 反向傳播
## 鏈式求導
鏈式求導是反向傳播利用的主要數學技巧,因此先來看鏈式求導。
我們假設
$$
y = y(u)\\
u = u(x)
$$
即
$$
\frac{∂y}{∂x} =\frac{∂y}{∂u}\frac{∂u}{∂x}
$$
利用鏈式求導法則可以有效的求出偏導數。注:應用在神經網路中損失函式必須是可微的(differentiable),例如 Sigmod 或者 Tanh 等
- Sigmod:
- if $$z(s) = \frac{1}{1+e^-s}$$ , then $$z'(s) = z(1-z)$$
- Tanh:
- if $$z(s) = tanh(s)$$ , then $$z'(s) = 1-z^2$$
## 反向傳播 Backpropagation
**反向傳播(back propagation, 簡稱backprop)**。是梯度下降法在深度網路上的具體實現方式。在傳統的前饋神經網路中,資訊通過網路向前流動,輸入x提供初始值,然後傳播到每一層的隱藏單元,最終產生輸出y。這個流程被稱為前向傳播(forward propagation)。而反向傳播允許來自代價函式的資訊通過網路向後流動,以便計算梯度、調整引數。
如圖,這是一個前向傳播網路的示意圖:
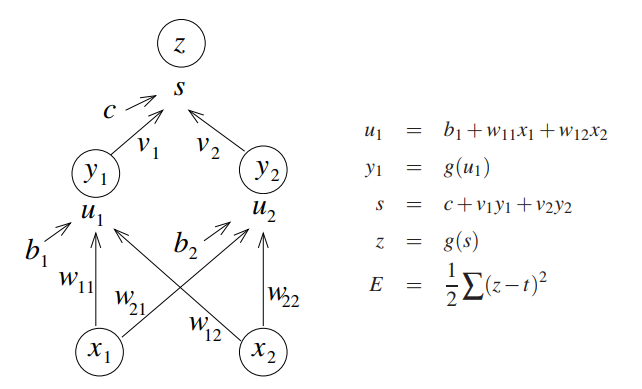
其中 E 表示計算出的誤差,這個例子中利用的是最小均方誤差。
我們為了減小誤差,使模型的輸出接近我們想要的值,就要利用反向傳播的辦法來調整模型中的引數。將誤差訊號沿著原來的路線返回,即要從輸出到輸入做偏導,修改神經元的權值和偏置值,使誤差 E 最小。
### 反向傳播中的核心方程

根據上述的方程,我們可以來更新權重,$w = w - η \frac{∂E}{∂w}$, 其中 $η$ 是學習率
注:這個地方可能用計算圖理解比較清晰。大家可以去查一些相關資料。
# 損失函式
**損失函式(Loss Function)又稱誤差函式(Error Function)和代價函式(Cost Function)**
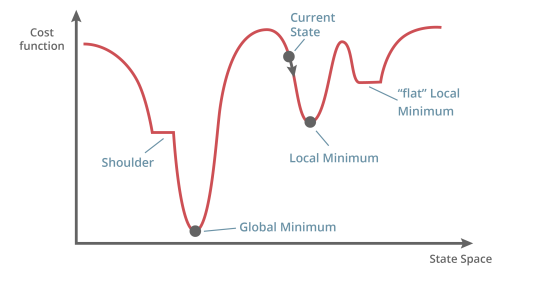
在神經網路中,我們的目標是找到一組權重,使誤差最小化,即到達圖中的 Global Minimum 點
## 均方誤差 MSE
處理迴歸問題常用的損失函式
**均方誤差(Mean Square Error, MSE)**是真實值與預測值的差值的平方然後求和平均。
$$
E = \frac{1}{2}(z_i-t_i)^2
$$
其中,$z_i$ 是實際輸出值,$t_i$ 是目標輸出值。前面加 $\frac{1}{2}$ 的原因是為了求導時候消去導數上移下來的數字2.
存在的問題:對於均方誤差函式,在處理分類問題的時候不太合適。當 MSE 配合 Sigmoid 函式使用時,MSE 在求導過程中要用到 Sigmoid 函式的導數$z'(s)$,會因為梯度消失而導致模型權重學習的很慢。如圖
$$
\frac{\delta E}{\delta w} = \frac{\delta E}{\delta z} \frac{\delta z}{\delta s} \frac{\delta s}{\delta w} = (z_i-t_i)·z_i'(s)·x_i
$$
而交叉熵損失函式可以很好的避免這個問題。
## 交叉熵損失函式 CEE
處理分類問題常用的損失函式
**交叉熵損失函式(Cross Entropy, CE)或稱交叉熵誤差(Cross Entropy Error, CEE)**
$$
E = -\sum_kt_klog(z_k)
$$
在01二分類問題中,公式形式為
$$
E = -tlog(z)-(1-t)log(1-z)
$$
# 常見面試題
## 用Python手寫反向傳播神經網路
[原始碼已上傳Github, 點選跳轉](https://github.com/JYRoy/MachineLearning/tree/master/NN)
## 啟用函式的作用
## 神經網路中的啟用函式有哪些
## 神經網路為什麼用交叉熵
## 交叉熵公式
## Loss Function有哪些,怎麼用?
## 線性迴歸的表示式,損