
知識圖譜基礎概念
0. AI為什麼需要知識圖譜?
人工智慧分為三個階段,從機器智慧到感知智慧,再到認知智慧。
機器智慧更多強調這些機器的運算的能力,大規模的叢集的處理能力,GPU的處理的能力。
在這個基礎之上會有感知智慧,感知智慧就是語音識別、影象識別,從圖片裡面識別出一個貓,識別人臉,是感知智慧。感知智慧並非人類所特有,動物也會有這樣的一些感知智慧。
再往上一層的認知智慧,是人類所特有的,是建立在思考的基礎之上的,認知的建立是需要思考的能力,而思考是建立在知識的基礎之上,必須有知識的基礎、有一些常識,才能建立一些思考,形成一個推理機制。
AI需要從感知智慧邁向認知智慧,本質上知識是一個基礎,然後基於知識的推理,剛好知識圖譜其實是具備這樣的一個屬性。
1. 知識圖譜發展歷史與基本概念
知識圖譜本質上是一種大型的語義網路,它旨在描述客觀世界的概念實體事件以及及其之間的關係。以實體概念為節點,以關係為邊,提供一種從關係的視角來看世界。
深度學習是這個階段大資料、人工智慧火爆的原因,雖然深度學習的表示學習能力能夠獲得事物的底層空間特徵,但這些特徵是通過一個黑夾子獲得,並且是一個連續的向量,人類根本無法理解,人類只能理解語義的場景。而知識圖譜正是為深度學習和語義空間提供了連線,彌補了其中的溝鴻。

1.1 語義網路(Semantic Network)
語義網路可以理解為,現存的詞彙都是可以串聯起來的。用相互連線的節點和邊來表示知識。節點表示物件、概念,邊表示節點之間的關係。
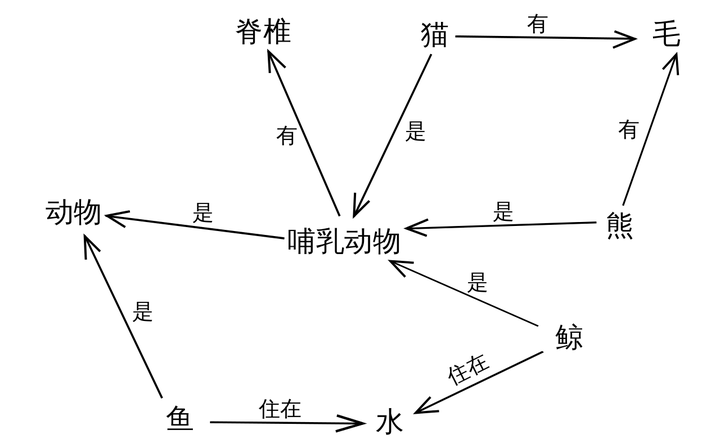
語義網路的優點:
容易理解和展示。
相關概念容易聚類。
語義網路的缺點:
節點和邊的值沒有標準,完全是由使用者自己定義。
多源資料融合比較困難,因為沒有標準。
無法區分概念節點和物件節點。
無法對節點和邊的標籤(label,我理解是schema層,後面會介紹)進行定義。
簡而言之,語義網路可以比較容易地讓我們理解語義和語義關係。其表達形式簡單直白,符合自然。然而,由於缺少標準,其比較難應用於實踐。看過上一篇文章的讀者可能已經發現,RDF的提出解決了語義網路的缺點1和缺點2,在節點和邊的取值上做了約束,制定了統一標準,為多源資料的融合提供了便利。
1.2 Ontology本體
Ontology:通常翻譯為“本體”。本體本身是個哲學名詞。在上個世紀80年代,人工智慧研究人員將這一概念引入了計算機領域。Tom Gruber把本體定義為“概念和關係的形式化描述”【4】。通俗點講,==本體相似於資料庫中的Schema==,比如足球領域,主要用來定義類和關係,以及類層次和關係層次等。OWL是最常用的本體描述語言。本體通常被用來為知識圖譜定義Schema。
1.3 The Semantic Web 語義網
語義網際網路的核心內涵是:Web不僅僅要通過超連結把文字頁面連結起來,還應該==把事物連結起來,使得搜尋引擎可以直接對事物進行搜尋==,而不僅僅是對網頁進行搜尋。谷歌知識圖譜是語義網際網路這一理念的商業化實現。也可以把語義網際網路看做是一個基於網際網路共同構建的全球知識庫。
在全球資訊網誕生之初,網路上的內容只是人類可讀,而計算機無法理解和處理。比如,我們瀏覽一個網頁,我們能夠輕鬆理解網頁上面的內容,而計算機只知道這是一個網頁。網頁裡面有圖片,有連結,但是計算機並不知道圖片是關於什麼的,也不清楚連結指向的頁面和當前頁面有何關係。==語義網正是為了使得網路上的資料變得機器可讀而提出的一個通用框架。==“Semantic”就是用更豐富的方式來表達資料背後的含義,讓機器能夠理解資料。“Web”則是希望這些資料相互連結,組成一個龐大的資訊網路,正如網際網路中相互連結的網頁,只不過基本單位變為粒度更小的資料,如下圖。
1.4 連結資料Linked Data
Tim Berners Lee於2006年提出,是為了強調語義網際網路的目的是要==建立資料之間的連結==,而非僅僅是把結構化的資料釋出到網上。他為建立資料之間的連結制定了四個原則【2】。從理念上講,連結資料最接近於知識圖譜的概念。但很多商業知識圖譜的具體實現並不一定完全遵循Tim所提出的那四個原則。
連結資料起初是用於定義如何利用語義網技術在網上釋出資料,其強調在不同的資料集間建立連結。Tim Berners Lee提出了釋出資料的四個原則,並根據資料集的開放程度將其劃分為1到5星5個層次。連結資料也被當做是語義網技術一個更簡潔,簡單的描述。當它指語義網技術時,它更強調“Web”,弱化了“Semantic”的部分。對應到語義網技術棧,它傾向於==使用RDF和SPARQL(RDF查詢語言)技術==,對於Schema層的技術,RDFS或者OWL,則很少使用。連結資料應該是最接近知識圖譜的一個概念,從某種角度說,知識圖譜是對連結資料這個概念的進一步包裝。
語義網和連結資料是全球資訊網之父Tim Berners Lee分別在1998年和2006提出的。相對於語義網路,語義網和連結資料傾向於描述全球資訊網中資源、資料之間的關係。
1.5 RDF,RDFS與OWL
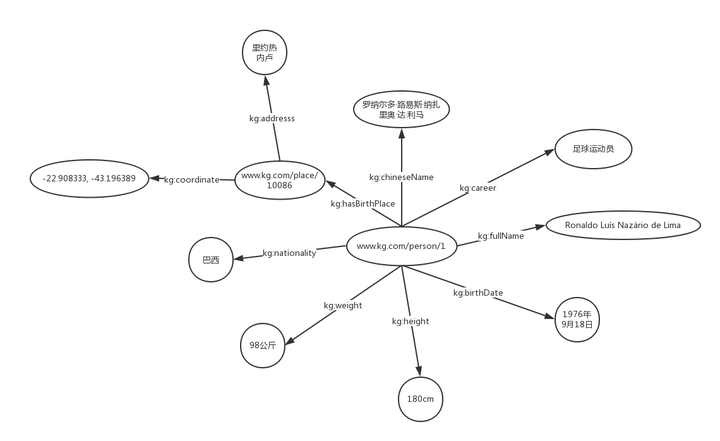
RDF(Resource Description Framework),即資源描述框架,其本質是一個數據模型(Data Model)。它提供了一個統一的標準,用於描述實體/資源。簡單來說,就是表示事物的一種方法和手段。
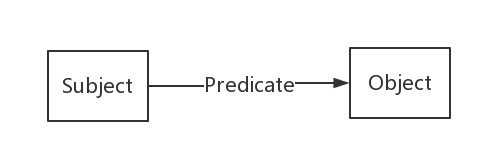
RDF由節點和邊組成,節點表示實體/資源、屬性,邊則表示了實體和實體之間的關係以及實體和屬性的關係。
1.6 圖資料庫
https://zhuanlan.zhihu.com/p/42351039
2. 分類
2.1 Common Sense Knowledge Graph(常識知識圖譜)
對於 Common Sense Knowledge Graph,一般而言我們比較在乎的 Relation 包括 isA Relation、isPropertyOf Relation。
2.2 百科全書式知識圖譜(Encyclopedia Knowledge Graph
對於 Encyclopedia Knowledge Graph,通常我們會預定義一些謂詞,比如說 DayOfbirth、LocatedIn、SpouseOf 等等。
對於 Common Sense Knowledge Graph 通常帶有一定的概率,但是 Encyclopedia Knowledge Graph 通常就是“非黑即白”,那麼構建這種知識圖譜時,我們在乎的就是 Precision(準確率)。
Common Sense Knowledge Graph 比較有代表性的工作包括 WordNet、KnowItAll、NELL 以及 Microsoft Concept Graph。而 Encyclopedia Knowledge Graph 則有 Freepase、Yago、Google Knowledge Graph 以及正在構建中的“美團大腦”。
3. 開源知識圖譜
當前世界範圍內知名的高質量大規模開放知識圖譜,包括
- DBpedia[85][86]、
- Yago[87][88]、
- Wikidata[89]、
- BabelNet[90][91]、
- ConceptNet[92][93]
- Microsoft Concept Graph[94][95]
另外還有中文開放知識圖譜平臺 OpenKG。
3.1 OpenKG
中文開放知識圖譜聯盟 OpenKG旨在推動中文知識圖譜的開放與互聯,推動知識圖譜技術在中國的普及與應用,為中國人工智慧的發展以及創新創業做出貢獻。聯盟已經搭建有OpenKG.CN技術平臺(圖5),目前已有35家機構入駐。吸引了國內最著名知識圖譜資源的加入,如 Zhishi.me, CN-DBPedia,PKUBase。並已經包含了來自於常識、醫療、金融、城市、出行等 15 個類目的開放知識圖譜。
4. 應用場景
知識圖譜主要包含兩層重要的資訊:圖資料結構+語義規則。


5.開發流程
其中實現層大概分成六個步驟,分別是知識獲取、知識抽取、知識融合、知識儲存、知識推理、知識建模和知識發現,
- 知識獲取 是獲取外部資料的方式,包括爬蟲和實時入庫的技術方法;
- 知識抽取 是對三元組進行知識的抽取,包括實體抽取、關係抽取和屬性的抽取;
- 知識融合 就是在抽取出來之後,存在很多的資料冗餘和噪聲,要去做實體的消歧,資料的整合;
- 知識儲存 實際是要構建一個三元組RDF的資料結構,如果把所有的頂點和邊構造出來之後,要對他進行圖資料庫的儲存;
- 知識推理 如果要做一些深層次的知識問答,就要做很多的訓練,無論有監督的還是半監督的;
- 知識建模 更多的是去理解語義,涉及到屬性的對映,實體的連線;
- 知識發現 兩大主要的應用是知識的檢索和知識的問答。這些構建了知識圖譜的實現層。
6.產品設計思路

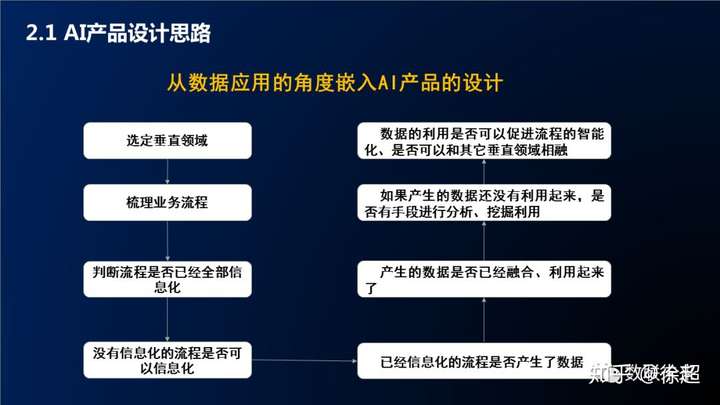

7.小結
知識圖譜的構建思路都差不多,首先需要從應用場景出發,結合資料情況以及技術團隊的積累,探索適合產品的落地方案,在迭代過程中打磨產品和技術。