
知識圖譜概念篇
隨著網際網路的發展,網路資料內容呈現爆炸式增長的態勢。由於網際網路內容的大規模、異質多元、組織結構鬆散的特點,給人們有效獲取資訊和知識提出了挑戰。知識圖譜(Knowledge Graph) 以其強大的語義處理能力和開放組織能力,為網際網路時代的知識化組織和智慧應用奠定了基礎。
最近,大規模知識圖譜庫的研究和應用在學術界和工業界引起了足夠的注意力。知識圖譜旨在描述現實世界中存在的實體以及實體之間的關係。知識圖譜於2012年5月17日由[Google]正式提出,其初衷是為了提高搜尋引擎的能力,改善使用者的搜尋質量以及搜尋體驗。隨著人工智慧的技術發展和應用,知識圖譜逐漸成為關鍵技術之一,現已被廣泛應用於智慧搜尋、智慧問答、個性化推薦、內容分發等領域。
知識圖譜的定義
在維基百科的官方詞條中:知識圖譜是Google用於增強其搜尋引擎功能的知識庫。本質上, 知識圖譜旨在描述真實世界中存在的各種實體或概念及其關係,其構成一張巨大的語義網路圖,節點表示實體或概念,邊則由屬性或關係構成。
現在的知識圖譜已被用來泛指各種大規模的知識庫。 我們先來看下知識型別的定義:
知識圖譜中包含的節點:
實體: 指的是具有可區別性且獨立存在的某種事物。如某一個人、某一個城市、某一種植物等、某一種商品等等。世界萬物由具體事物組成,此指實體。如圖1的“中國”、“美國”、“日本”等。實體是知識圖譜中的最基本元素,不同的實體間存在不同的關係。
語義類(概念):具有同種特性的實體構成的集合,如國家、民族、書籍、電腦等。 概念主要指集合、類別、物件型別、事物的種類,例如人物、地理等。
屬性(值): 從一個實體指向它的屬性值。不同的屬性型別對應於不同型別屬性的邊。屬性值主要指物件指定屬性的值。如圖1所示的“面積”、“人口”、“首都”是幾種不同的屬性。屬性值主要指物件指定屬性的值,例如960萬平方公里等。
關係: 形式化為一個函式,它把 k k個點對映到一個布林值。在知識圖譜上,關係則是一個把k k個圖節點(實體、語義類、屬性值)對映到布林值的函式。
代表知識庫中的三元組集合。三元組的基本形式主要包括(實體1-關係-實體2)和(實體-屬性-屬性值)等。每個實體(概念的外延)可用一個全域性唯一確定的ID來標識,每個屬性-屬性值對(attribute-value pair,AVP)可用來刻畫實體的內在特性,而關係可用來連線兩個實體,刻畫它們之間的關聯。如下圖1的知識圖譜例子所示,中國是一個實體,北京是一個實體,中國-首都-北京 是一個(實體-關係-實體)的三元組樣例北京是一個實體 ,人口是一種屬性2069.3萬是屬性值。北京-人口-2069.3萬構成一個(實體-屬性-屬性值)的三元組樣例。
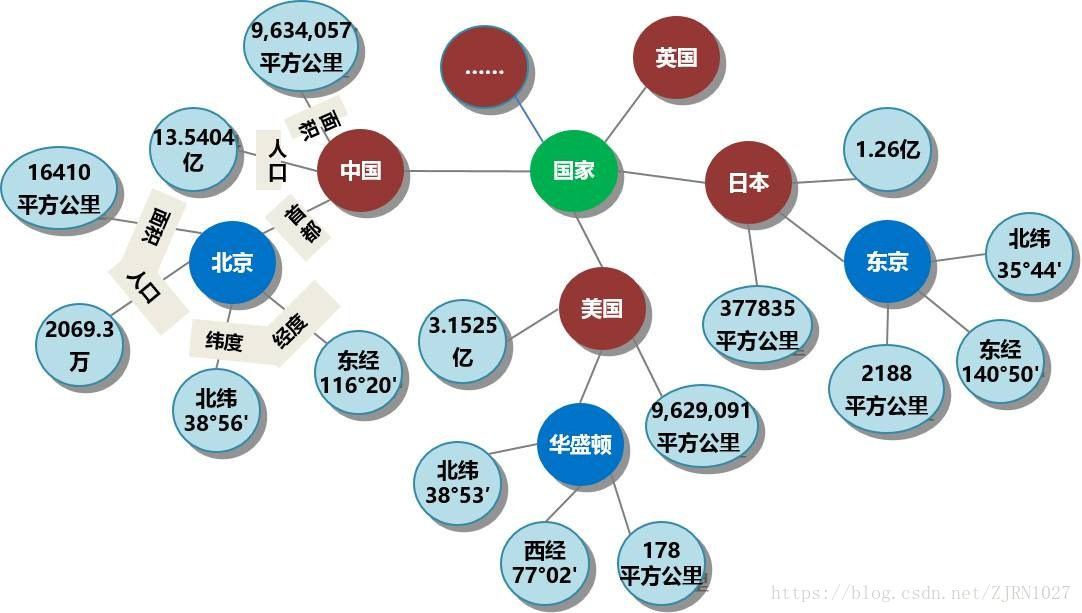
圖1 知識圖譜示例
知識圖譜的架構:
知識圖譜的架構包括自身的邏輯結構以及構建知識圖譜所採用的技術(體系)架構。
1) 知識圖譜的邏輯結構
知識圖譜在邏輯上可分為模式層與資料層兩個層次,資料層主要是由一系列的事實組成,而知識將以事實為單位進行儲存。如果用(實體1,關係,實體2)、(實體、屬性,屬性值)這樣的三元組來表達事實,可選擇圖資料庫作為儲存介質,例如開源的Neo4j、Twitter的FlockDB、sones的GraphDB等。模式層構建在資料層之上,是知識圖譜的核心,通常採用本體庫來管理知識圖譜的模式層。本體是結構化知識庫的概念模板,通過本體庫而形成的知識庫不僅層次結構較強,並且冗餘程度較小。
2) 知識圖譜的體系架構
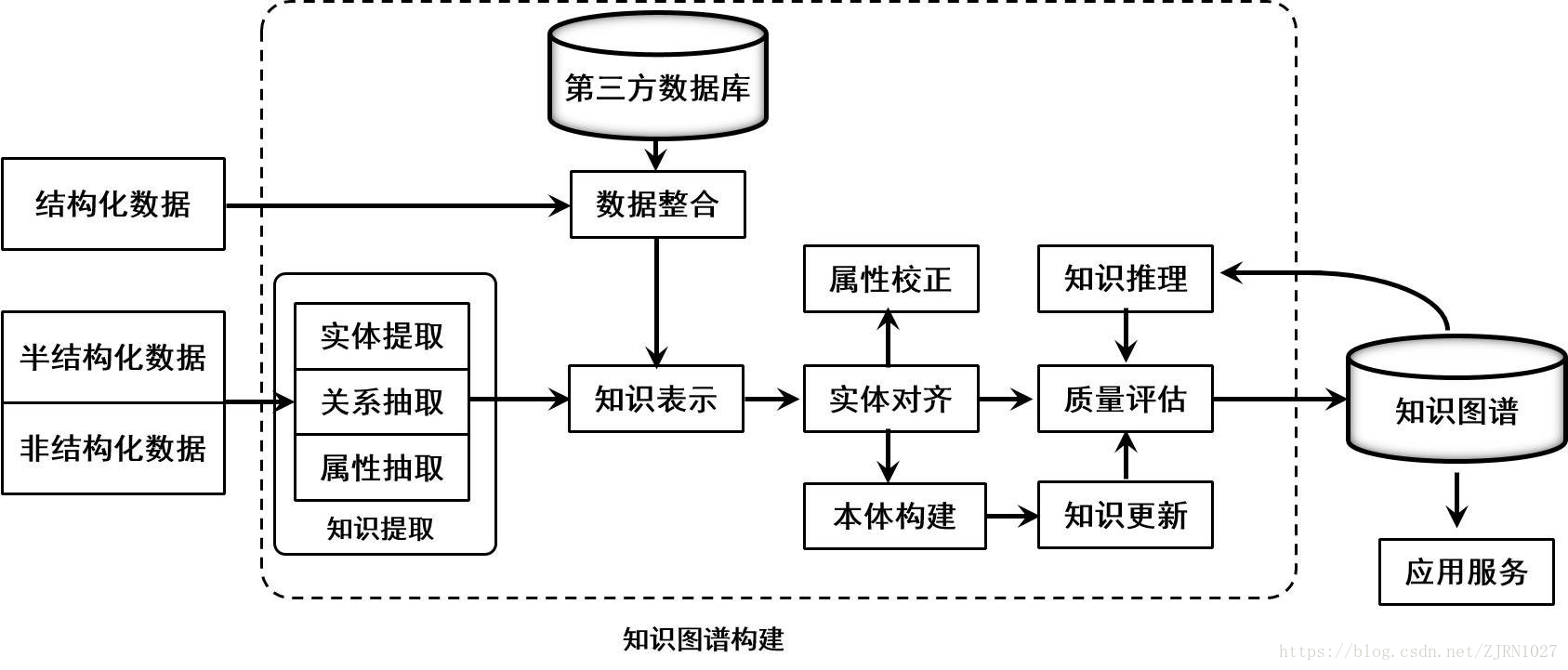
知識圖譜的體系架構是其指構建模式結構,如圖2所示。其中虛線框內的部分為知識圖譜的構建過程,也包含知識圖譜的更新過程。
知識圖譜構建從最原始的資料(包括結構化、半結構化、非結構化資料)出發,採用一系列自動或者半自動的技術手段,從原始資料庫和第三方資料庫中提取知識事實,並將其存入知識庫的資料層和模式層,這一過程包含:資訊抽取、知識表示、知識融合、知識推理四個過程,每一次更新迭代均包含這四個階段。
知識圖譜主要有自頂向下(top-down)與自底向上(bottom-up)兩種構建方式。
自頂向下指的是先為知識圖譜定義好本體與資料模式,再將實體加入到知識庫。該構建方式需要利用一些現有的結構化知識庫作為其基礎知識庫。
自底向上指的是從一些開放連結資料中提取出實體,選擇其中置信度較高的加入到知識庫,再構建頂層的本體模式。目前,大多數知識圖譜都採用自底向上的方式進行構建,其中最典型就是Google的Knowledge Vault和微軟的Satori知識庫。現在也符合網際網路資料內容知識產生的特點。