
分散式實時處理系統Hurricane的架構
Hurricane總體架構圖
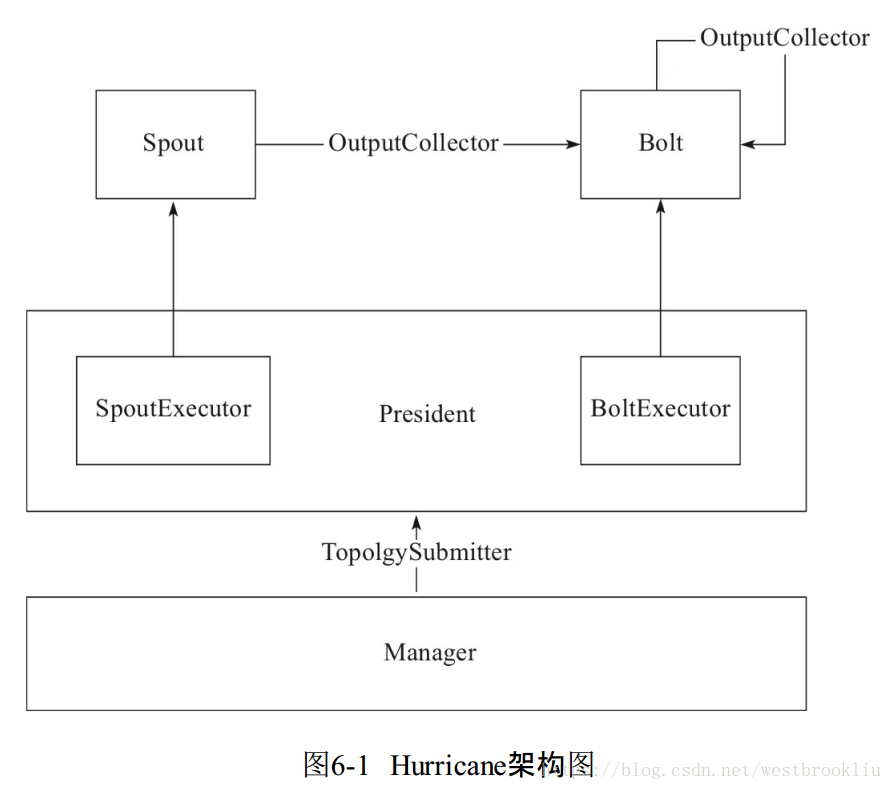
各部件介紹
- Spout是訊息源,拓撲結構中所有的資料都來自訊息源,而訊息源也是拓撲結構中訊息流的源頭。
- Bolt是訊息處理單元,負責接收來自訊息源或資料處理單元的資料
流,並對資料進行邏輯處理,然後轉發到下一個訊息處理單元,基本封裝了所有的資料處理邏輯。 - SpoutExecutor是一個執行緒,是所有訊息源的執行者,每一個SpoutExecutor負責執行一個訊息源
- BoltExecutor也是一個執行緒,是所有訊息處理單元的執行者,每個BoltExecutor負責執行一個訊息處理單元。
- SpoutExecutor會永不停息地執行,而BoltExecutor則會等到資料到來才啟動。
- SpoutExecutor
- Manager是單個節點任務的管理者,負責建立執行器物件,與中心節點通訊,並接收來自其他節點的資料,將這些資料分發到對應的Bolt中,讓Bolt進行處理。
- President是整個叢集的中心節點,負責收集使用者的請求,並將使用者定義的拓撲結果傳送給正在執行的其他各Manager,同時也會通過向各Manager收集資訊,瞭解各節點的執行情況,同時為每個Executor分配對應的任務。
相關推薦
分散式實時處理系統Hurricane的架構
Hurricane總體架構圖 各部件介紹 Spout是訊息源,拓撲結構中所有的資料都來自訊息源,而訊息源也是拓撲結構中訊息流的源頭。 Bolt是訊息處理單元,負責接收來自訊息源或資料處理單元的資料 流,並對資料進行邏輯處理,然後轉發到下一個訊息處理單元,基本封裝
【讀書精華分享】《分散式實時處理系統 原理、架構與實現》盧譽聲著/2016年
【分享說明】: 我會花很多時間或淺或深的研讀一本書,然後總結一些提煉出來的精華,用簡短的語言,讓其他人能夠用很少的時間大致知道這本書能帶給自己的價值,如果適用自己,鼓勵買一本正本實體書細讀
Apache Storm分散式實時處理資料流系統
Storm是一個分散式的,可靠的,容錯的資料流處理系統。Storm叢集的輸入流由一個被稱作spout的元件管理,spout把資料傳遞給bolt, bolt要麼把資料儲存到某種儲存器,要麼把資料傳遞給其它的bolt。一個Storm叢集就是在一連串的bolt之間轉換spout傳過
ubuntu16.04安裝Storm數據流實時處理系統 集群
大數據 storm[email protected]:~# wget http://mirror.bit.edu.cn/apache/storm/apache-storm-1.1.1/apache-storm-1.1.1.tar.gz[email protected]:/usr/local
Flume+Kafka+Storm+Redis構建大數據實時處理系統:實時統計網站PV、UV+展示
大數據 實時計算 Storm [TOC] 1 大數據處理的常用方法 前面在我的另一篇文章中《大數據采集、清洗、處理:使用MapReduce進行離線數據分析完整案例》中已經有提及到,這裏依然給出下面的圖示: 前面給出的那篇文章是基於MapReduce的離線數據分析案例,其通過對網站產生的用戶訪問
Flume+Kafka+Storm+Redis實時分析系統基本架構
今天作者要在這裡通過一個簡單的電商網站訂單實時分析系統和大家一起梳理一下大資料環境下的實時分析系統的架構模型。當然這個架構模型只是實時分析技術的一 個簡單的入門級架構,實際生產環境中的大資料實時分析技術還涉及到很多細節的處理, 比如使用Storm的ACK機制保證資料都能被正確處理, 叢集的高可用架構
Flume+Kafka+Storm+Redis構建大資料實時處理系統
資料處理方法分為離線處理和線上處理,今天寫到的就是基於Storm的線上處理。在下面給出的完整案例中,我們將會完成下面的幾項工作: 如何一步步構建我們的實時處理系統(Flume+Kafka+Storm+Redis) 實時處理網站的使用者訪問日誌,並統計出該網站的PV、UV 將實時
赫拉(hera)分散式任務排程系統之架構,基本功能(一)
文章目錄 為資料平臺打造的任務排程系統 前言 架構 設計目標 支援任務的定時排程、依賴排程、手動排程、手動恢復 支援豐富的任務型別:shell,hive,python,spark-sql,java
實時可靠的開源分散式實時計算系統——Storm
在Hadoop生態圈中,針對大資料進行批量計算時,通常需要一個或者多個MapReduce作業來完成,但這種批量計算方式是滿足不了對實時性要求高的場景。 Storm是一個開源分散式實時計算系統,它可以實時可靠地處理流資料。 Storm特點 在Storm出現之前,進行實時處理是非常痛苦的事情,我們主要的時
基於Storm構建分散式實時處理應用初探
Storm對比Hadoop,前者更擅長的是實時流式資料處理,後者更擅長的是基於HDFS,通過MapReduce方式的離線資料分析計算。對於Hadoop,本身不擅長實時的資料分析處理。兩者的共同點都是分散式架構,而且都類似有主/從關係的概念。 本文不會具體闡述Storm叢集和Zookeeper叢集如何部署的問
批處理系統、分時處理系統、實時處理系統簡介
一、批處理階段(作業系統開始出現) 為了解決人機矛盾及CPU和I/O裝置之間速度不匹配的矛盾,出現了批處理系統。它按發展歷程又分為單道批處理系統、多道批處理系統(多道程式設計技術出現以後)。 1) 單
ELK 大規模日誌實時處理系統應用簡介
ELK 是軟體集合 Elasticsearch、Logstash、Kibana 的簡稱,由這三個軟體及其相關的元件可以打造大規模日誌實時處理系統。 其中,Elasticsearch 是一個基於 Lucene 的、支援全文索引的分散式儲存和索引引擎,主要負責將日誌索引並存儲起
一臉懵逼學習Storm的搭建--(一個開源的分散式實時計算系統)
1:安裝一個zookeeper叢集,之前已經部署過,這裡省略,貼一下步驟; 安裝配置zooekeeper叢集: 1.1:解壓 tar -zxvf zooke
透過CAT,來看分散式實時監控系統的設計與實現
轉載自:http://mp.weixin.qq.com/s?__biz=MzA5Nzc4OTA1Mw==&mid=410426909&idx=1&sn=851bf383a5c82f6c9eb5fa0f3b0b9399&scene=0#wech
大資料理論篇 - 通俗易懂,揭祕分散式資料處理系統的核心思想(一)
> 作者:[justmine]( https://www.cnblogs.com/justmine/) > > 頭條號:[大資料達摩院]( https://www.cnblogs.com/justmine/) > > 創作不易,未經授權,禁止轉載,否則保留追究法律責任的權利。 [TOC]
支付寶資深架構師的分散式追蹤 & APM 系統 SkyWalking 原始碼分析— DataCarrier 非同步處理庫
1. 概述本文主要分享 SkyWalking DataCarrier 非同步處理庫。基於生產者消費者的模式,大體結構如下圖:實際專案中,沒有 Producer 這個類。所以本文提到的 Producer ,更多的是一種角色。下面我們來看看整體的專案結構,如下圖所示 :org.s
Druid:一個用於大資料實時處理的開源分散式系統
Druid是一個用於大資料實時查詢和分析的高容錯、高效能開源分散式系統,旨在快速處理大規模的資料,並能夠實現快速查詢和分析。尤其是當發生程式碼部署、機器故障以及其他產品系統遇到宕機等情況時,Druid仍能夠保持100%正常執行。建立Druid的最初意圖主要是為了解決查詢延遲問題,當時試圖使用Hadoop來實現
im大型分散式實時計費伺服器系統架構2.0
整個創業團隊後臺就我一個設計,架構,和開發.一路上很辛苦,因為遇到的問題很多很多,並不是想象的那麼簡單.本來2.0想用go語言開發的,簡單,又快,又支援熱更新.處理速度和c++差不多,但靈活度沒有c+
Hadoop簡介(分散式系統基礎架構)
Hadoop 求助編輯百科名片 Hadoop示意圖 一個分散式系統基礎架構,由Apache基金會開發。使用者可以在不瞭解分散式底層細節的情況下,開發分散式程式。充分利用叢集的威力高速運算和儲存。Hadoop實現了一個分散式檔案系統(Hadoop Distri
分散式系統的架構思路 深入理解java:5. Java分散式架構
原文來源:https://www.cnblogs.com/chulung/p/5653135.html 一、前言 在計算機領域,當單機效能達到瓶頸時,有兩種方式可以解決效能問題,一是堆硬體,進一步提升配置,二是分散式,水平擴充套件。當然,兩者都是一樣的燒錢。今天聊聊我所理解的分散式系統的架構思路。