
š„ Training Neural Nets on Larger Batches: Practical Tips for 1
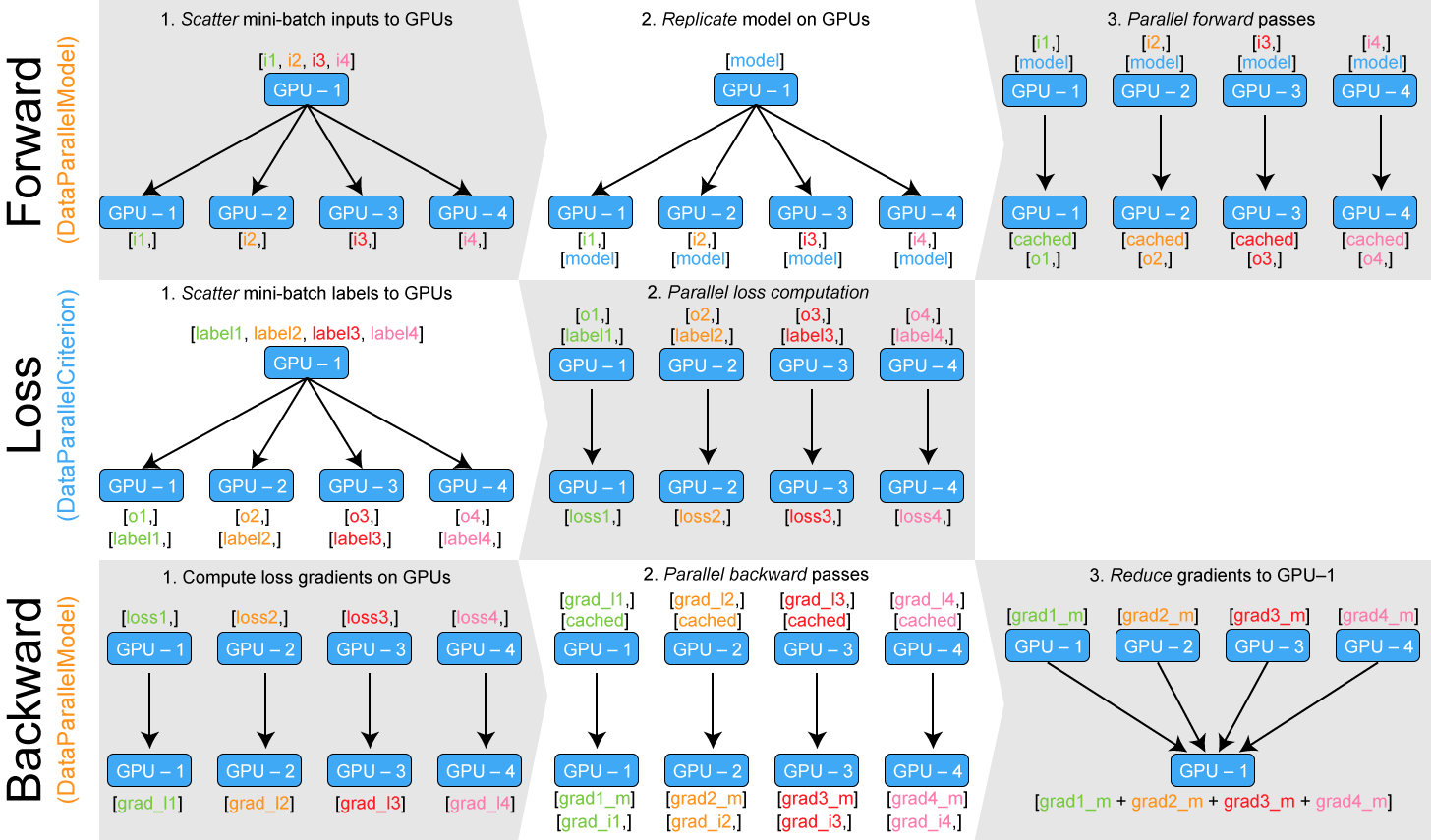
During step 4 of the Forward pass (top-right), the results of all the parallel computations are gathered on GPU-1. This is fine for a lot of classification problems but it can become problematic when you train a language model on large batch for example.
Letās quickly compute the size of the output for a language model:
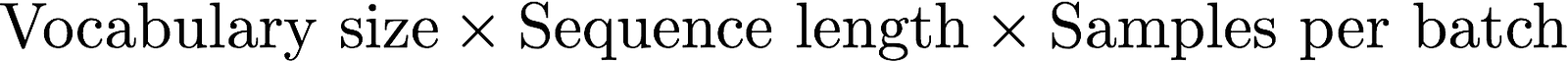
If we assume a 40k vocabulary, 250 tokens in our sequences, 32 samples per batch and 4 bytes to store each element in the memory, the output of our model takesabout1,2 GB. We need to double that to store the associated gradient tensors, our model output thus requires 2,4 GB of memory!
Thatās a significant portion of a typical 10 GB GPU memory and means that GPU-1 will be over-used with regards to the other GPUs, limiting the effect of the parallelization.
We cannot easily reduce the number of elements in this output without tweaking the model and/or optimization scheme. But we can make sure the memory load is more evenly distributed among the GPUs.
āļø Balanced load on a multi-GPU machine
The solution is to keep each partial output on its GPU instead of gathering all of them to GPU-1. We well need to distribute our loss criterion computation as well to be able to compute and back propagate our loss.
Thankfully for us, Hang Zhang (å¼ čŖ) has open-sourced a nice PyTorch package called PyTorch-Encoding which comprises these custom parallelization functions.
Iāve extracted and slightly adapted this module and you can download here a gist (parallel.py) to include and call from your code. It mainly comprises two modules: DataParallelModel and DataParallelCriterion which are made to be used as follows:
The difference between DataParallelModel andtorch.nn.DataParallel is just that the output of the forward pass (predictions) is not gathered on GPU-1 and is thus a tuple of n_gpu tensors, each tensor being located on a respective GPU.
The DataParallelCriterion container encapsulate the loss function and takes as input the tuple of n_gpu tensorsand the target labels tensor. It computes the loss function in parallel on each GPU, splitting the target label tensor the same way the model input was chunked by DataParallel.
I made an illustration of DataParallelModel/DataParallelCriterion internals:

Here is how to handle two particular cases you may encounter:
- Your model outputs several tensors: you likely want to disentangle them:
output_1, output_2 = zip(*predictions) - Sometimes you donāt want to use a parallel loss function: gather all the tensors on the cpu:
gathered_predictions = parallel.gather(predictions)
ā° Distributed training: training on severalĀ machines
Now how can we harness the power of several servers to train on even larger batches?
The simplest option is to use PyTorch DistributedDataParallel which is meant to be almost a drop-in replacement for DataParallel discussed above.
But be careful: while the code looks similar, training your model in a distributed setting will change your workflow because you will actually have to start an independent python training script on each node (these scripts are all identical).As we will see, once started, these training scripts will be synchronized together by PyTorch distributed backend.
In practice, thismeans that each training script will have:
- its own optimizer and performs a complete optimization step with each iteration, no parameter broadcast (step 2 in DataParallel) is needed,
- an independent Python interpreter: this will also avoid the GIL-freeze that can come from driving several parallel execution threads in a single Python interpreter.
Models that make heavy use of Python loops/call in their forward passes can be slowed down by the python interpreterās GIL when several parallel forward calls are driven by a single interpreter. In these settings, DistributedDataParallel can advantageously replace DataParallel even on a single-machine setup.
Now letās just dive straight in the code and usage.
DistributedDataParallel is build on top of torch.distributed package which provide low-level primitives for synchronizing distributed operations and can make use of several backends (tcp, gloo, mpi, nccl) with different capabilities.
In this post I will select one simple way to use it out-of-the-box but you should read the doc and this nice tutorial by SĆ©b Arnold to dive deeper in this module.
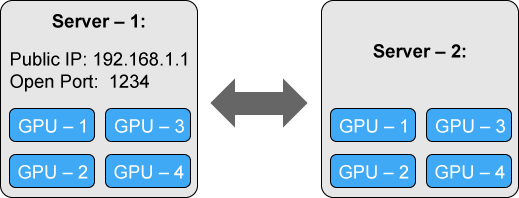
We will consider a simple but general setup with two 4-GPU servers (nodes):

š Adapting our Python training script for distributed training
First we need to adapt our script so that it can be run separately on each machine (node). We are actually going to go fully distributed and run a separate process for each GPU of each node, so 8 process in total.
Our training script is a bit longer as we need to initialize the distributed backend for synchronization, encapsulate the model and prepare the data to train each process on a separate subset of the data (each process is independent so we have to care of having each of them handle a different slice of the dataset ourselves). Here is the updated code:
āØ Launching multiple instances of our Python trainingĀ script
We are almost done now. We just have to start an instance of our training script on each server.
To run our script, weāll use the torch.distributed.launch utility of PyTorch. It will take care of setting the environment variables and call each script with the right local_rank argument.The first machine will be our master, it need to be accessible from all the other machine and thus have an accessible IP address (192.168.1.1 in our example) and an open port (1234 in our case). On this first machine, we run our training script using torch.distributed.launch:
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=2 --node_rank=0 --master_addr="192.168.1.1" --master_port=1234 OUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other arguments of our training script)
On the second machine we similarly start our script:
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=2 --node_rank=1 --master_addr="192.168.1.1" --master_port=1234 OUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other arguments of our training script)
These two commands are identical excepted for the --node_rank argument which is set to 0 on the first machine and 1 on the second (and would be 2 on an additional server etcā¦)
The process of running a bunch of almost identical commands on a cluster of machine might looks a bit tedious. So now is probably a good time to learn about the magic ofā¦ GNU parallel:

One exciting improvement of the coming PyTorch v1.0 is the release of a new c10d backend for the distributed module. I will update this short introduction when v1.0 is released with more details on the new backend š„