
Airflow 101: Start automating your batch workflows with ease
In this blog, I cover the main concepts behind pipeline automation with Airflow and go through the code (and a few gotchas) to create your first workflow with ease.
Why Airflow?
Data pipelines are built by defining a set of “tasks” to extract, analyze, transform, load and store the data. For example, a pipeline could consist of tasks like reading archived logs from S3, creating a Spark job to extract relevant features, indexing the features using Solr and updating the existing index to allow search. To automate this pipeline and run it weekly, you could use a time-based scheduler like
Airflow is a workflow scheduler to help with scheduling complex workflows and provide an easy way to maintain them. There are numerous resources for understanding what Airflow does, but it’s much easier to understand by directly working through an example.
Here are a few reasons to use Airflow:
- Open source:After starting as an internal project at Airbnb, Airflow had a natural need in the community. This was a major reason why it eventually became an open source project. It is currently maintained and managed as an incubating project at Apache.
- Web Interface: Airflow ships with a Flask app that tracks all the defined workflows, and let’s you easily change, start, or stop them. You can also work with the command line, but the web interface is more intuitive.
- Python Based: Every part of the configuration is written in Python, including configuration of schedules and the scripts to run them. This removes the need to use restrictive JSON or XML configuration files.
When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative.
Concepts
Let’s look at few concepts that you’ll need to write our first workflow.
Directed Acyclic Graphs

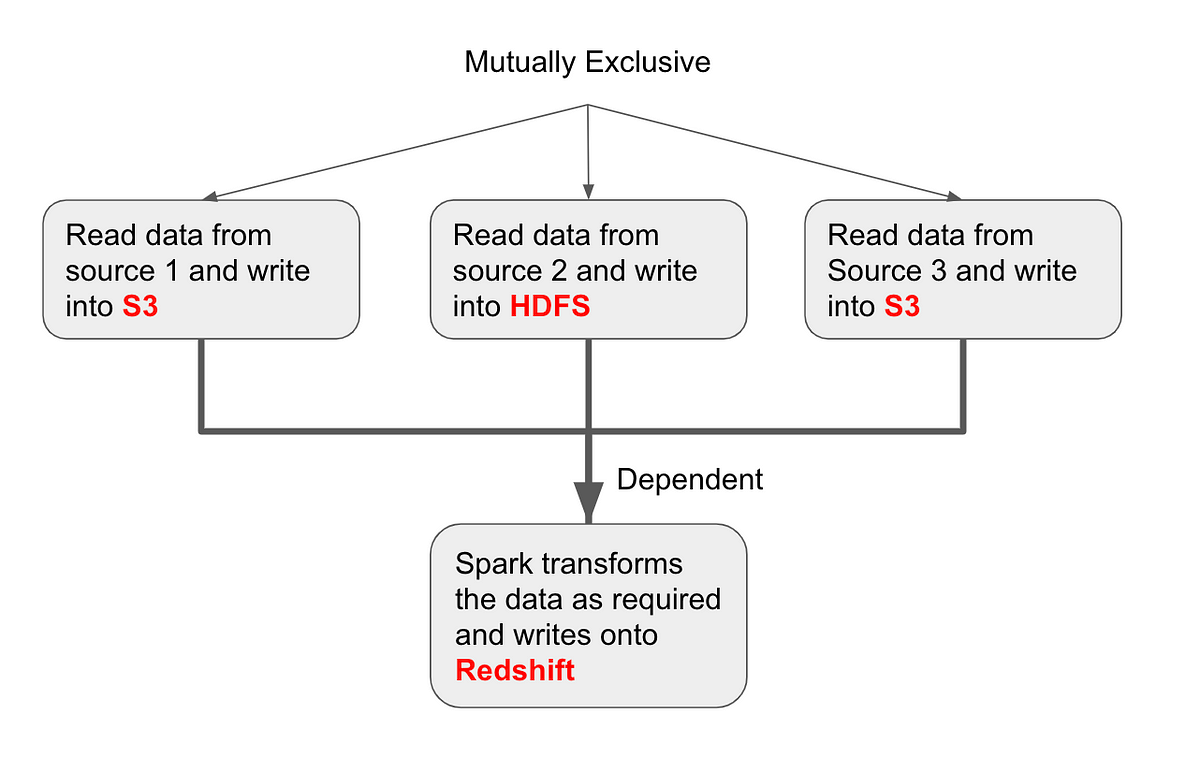
In Airflow, Directed Acyclic Graphs (DAGs) are used to create the workflows. DAGs are a high-level outline that define the dependent and exclusive tasks that can be ordered and scheduled.
We will work on this example DAG that reads data from 3 sources independently. Once that is completed, we initiate a Spark job to join the data on a key and write the output of the transformation to Redshift.
Defining a DAG enables the scheduler to know which tasks can be run immediately, and which have to wait for other tasks to complete. The Spark job has to wait for the three “read” tasks and populate the data into S3 and HDFS.
Scheduler
The Scheduler is the brains behind setting up the workflows in Airflow. As a user, interactions with the scheduler will be limited to providing it with information about the different tasks, and when it has to run. To ensure that Airflow knows all the DAGs and tasks that need to be run, there can only be one scheduler.
Operators
Operators are the “workers” that run our tasks. Workflows are defined by creating a DAG of operators. Each operator runs a particular task written as Python functions or shell command. You can create custom operators by extending the BaseOperator class and implementing the execute() method.
Tasks
Tasks are user-defined activities ran by the operators. They can be functions in Python or external scripts that you can call. Tasks are expected to be idempotent — no matter how many times you run a task, it needs to result in the same outcome for the same input parameters.
Note: Don’t confuse operators with tasks. Tasks are defined as “what to run?” and operators are “how to run”. For example, a Python function to read from S3 and push to a database is a task. The method that calls this Python function in Airflow is the operator. Airflow has built-in operators that you can use for common tasks.
Getting Started
To put these concepts into action, we’ll install Airflow and define our first DAG.
Installation and Folder structure
Airflow is easy (yet restrictive) to install as a single package. Here is a typical folder structure for our environment to add DAGs, configure them and run them.
We create a new Python file my_dag.py and save it inside the dags folder.
Importing various packages
# airflow relatedfrom airflow import DAGfrom airflow.operators.python_operator import PythonOperatorfrom airflow.operators.bash_operator import BashOperator
# other packagesfrom datetime import datetimefrom datetime import timedelta
We import three classes, DAG, BashOperator and PythonOperator that will define our basic setup.
Setting up default_args
default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date': datetime(2018, 9, 1), 'email_on_failure': False, 'email_on_retry': False, 'schedule_interval': '@daily', 'retries': 1, 'retry_delay': timedelta(seconds=5),}This helps setting up default configuration that applies to the DAG. This link provides more details on how to configure the default_args and the additional parameters available.
Defining our DAG, Tasks, and Operators
Let’s define all the tasks for our existing workflow. We have three tasks that read data from their respective sources and store them in S3 and HDFS. They are defined as Python functions that will be called by our operators. We can pass parameters to the function using and from our operator. For instance, the function source2_to_hdfs takes a named parameter config and two context parameters ds and **kwargs.
def source1_to_s3(): # code that writes our data from source 1 to s3
def source2_to_hdfs(config, ds, **kwargs): # code that writes our data from source 2 to hdfs # ds: the date of run of the given task. # kwargs: keyword arguments containing context parameters for the run.
def source3_to_s3(): # code that writes our data from source 3 to s3
We instantiate a DAG object below. The schedule_interval is set for daily and the start_date is set for September 1st 2018 as given in the default_args.
dag = DAG( dag_id='my_dag', description='Simple tutorial DAG', default_args=default_args)
We then have to create four tasks in our DAG. We use PythonOperator for the three tasks defined as Python functions and BashOperator for running the Spark job.
config = get_hdfs_config()
src1_s3 = PythonOperator( task_id='source1_to_s3', python_callable=source1_to_s3, dag=dag)
src2_hdfs = PythonOperator( task_id='source2_to_hdfs', python_callable=source2_to_hdfs, op_kwargs = {'config' : config}, provide_context=True, dag=dag)src3_s3 = PythonOperator( task_id='source3_to_s3', python_callable=source3_to_s3, dag=dag)
spark_job = BashOperator( task_id='spark_task_etl', bash_command='spark-submit --master spark://localhost:7077 spark_job.py', dag = dag)
The tasks of pushing data to S3 (src1_s3 and src3_s3) are created using PythonOperator and setting the python_callable as the name of the function that we defined earlier. The task src2_hdfs has additional parameters including context and a custom config parameter to the function. the dag parameter will attach the task to the DAG (though that workflow hasn’t been shown yet).
The BashOperator includes the bash_command parameter that submits a Spark job to process data and store it in Redshift. We set up the dependencies between the operators by using the >> and <<.
# setting dependenciessrc1_s3 >> spark_jobsrc2_hdfs >> spark_jobsrc3_s3 >> spark_job
You can also use set_upstream() or set_downstream() to create the dependencies for Airflow version 1.7 and below.
# for Airflow <v1.7spark_job.set_upstream(src1_s3)spark_job.set_upstream(src2_hdfs)
# alternatively using set_downstreamsrc3_s3.set_downstream(spark_job)
Adding our DAG to the Airflow scheduler
The easiest way to work with Airflow once you define our DAG is to use the web server. Airflow internally uses a SQLite database to track active DAGs and their status. Use the following commands to start the web server and scheduler (which will launch in two separate windows).
> airflow webserver
> airflow scheduler
Alternatively, you can start them as services by setting up systemd using the scripts from the Apache project. Here are screenshots from the web interface for the workflow that we just created.

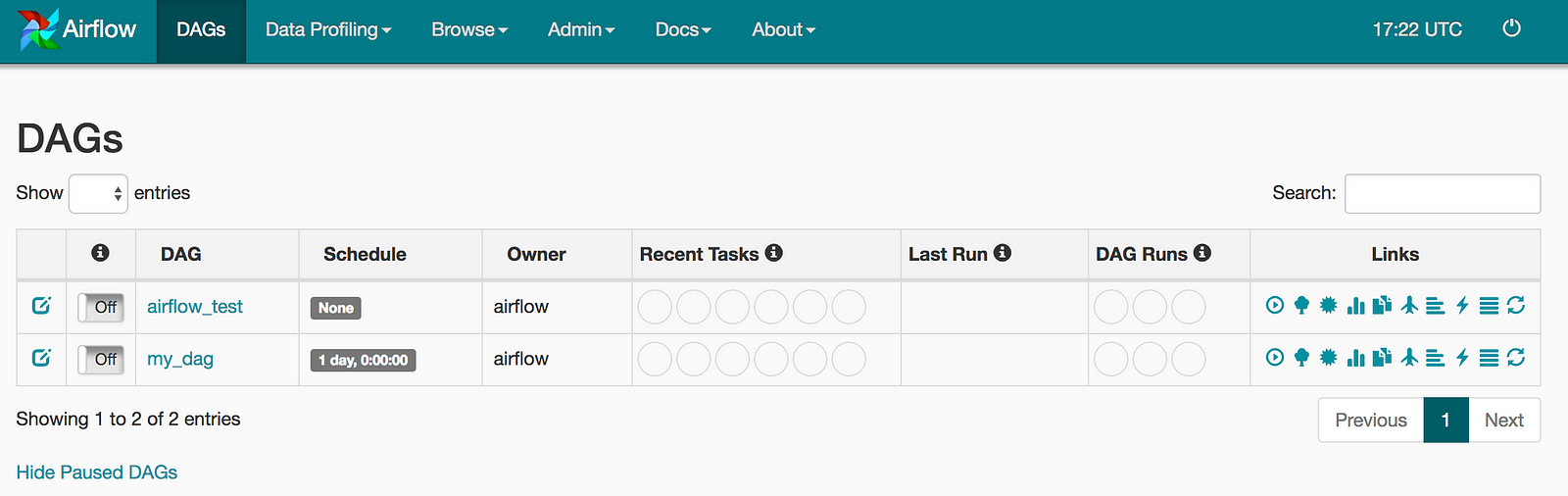



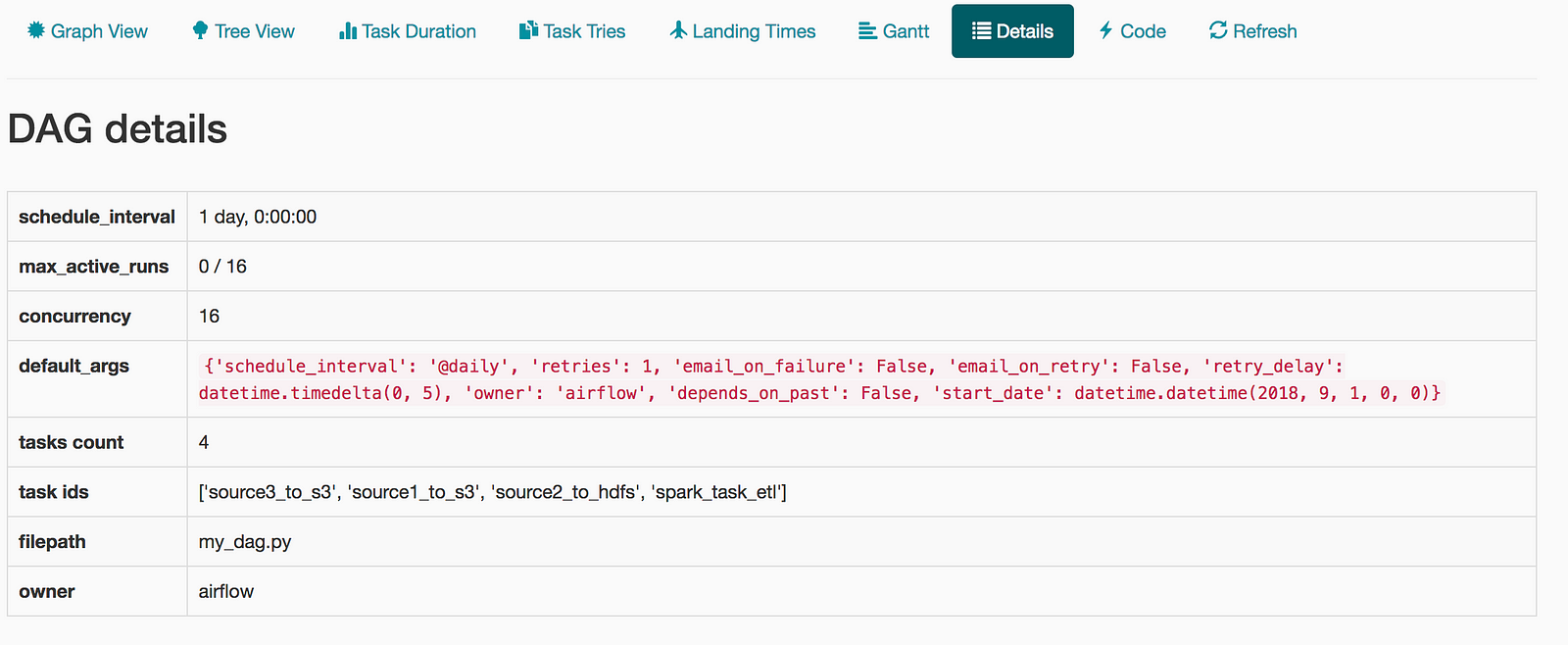
Here is the entire code for this workflow:
We have written our first DAG using Airflow. Every day, this DAG will read data from three sources and store them in S3 and HDFS. Once the data is in the required place, we have a Spark job that runs an ETL task. We have also provided instructions to handle retries and the time to wait before retrying.
Gotchas
Use Refresh on the web interface: Any changes that you make to the DAGs or tasks don’t get automatically updated in Airflow. You’ll need to use the Refresh button on the web server to load the latest configurations.
Be careful when changing start_date and schedule_interval: As already mentioned, Airflow maintains a database of information about the various runs. Once you run a DAG, it creates entries in the database with those details. Any changes to the start_date and schedule_interval can cause the workflow to be in a weird state that may not recover properly.
Start scheduler separately: It seems obvious to start the scheduler when the web server is started. Airflow doesn’t work that way for an important reason — to provide separation of concerns when deployed in a cluster environment where the Scheduler and web server aren’t necessarily onthe same machine.
Understand Cron definitions when using it in schedule_interval: You can set the value for schedule_interval in a similar way you set a Cron job. Be sure you understand how they are configured. Here is a good start to know more about those configurations.
You can also check out more FAQs that the Airflow project has compiled to help beginners get started with writing workflows easily.