
Store, Protect, Optimize Your Healthcare Data with AWS: Part 1
This blog post was co-authored by Ujjwal Ratan, a senior AI/ML solutions architect on the global life sciences team.
Healthcare data is generated at an ever-increasing rate and is predicted to reach 35 zettabytes by 2020. Being able to cost-effectively and securely manage this data whether for patient care, research or legal reasons is increasingly important for healthcare providers.
Healthcare providers must have the ability to ingest, store and protect large volumes of data including clinical, genomic, device, financial, supply chain, and claims. AWS is well-suited to this data deluge with a wide variety of ingestion, storage and security services (e.g. AWS Direct Connect, Amazon Kinesis Streams, Amazon S3, Amazon Macie) for customers to handle their healthcare data. In a recent
I realize simply storing this data is challenging enough. Magnifying the problem is the fact that healthcare data is increasingly attractive to cyber attackers, making security a top priority. According to Mariya Yao in her
In this first of a 2-part post, I will address the value that AWS can bring to customers for ingesting, storing and protecting provider’s healthcare data. I will describe key components of any cloud-based healthcare workload and the services AWS provides to meet these requirements. In part 2 of this post we will dive deep into the AWS services used for advanced analytics, artificial intelligence and machine learning.
The data tsunami is upon us
So where is this data coming from? In addition to the ubiquitous electronic health record (EHR), the sources of this data include:
- genomic sequencers
- devices such as MRIs, x-rays and ultrasounds
- sensors and wearables for patients
- medical equipment telemetry
- mobile applications
Additional sources of data come from non-clinical, operational systems such as:
- human resources
- finance
- supply chain
- claims and billing
Data from these sources can be structured (e.g., claims data) as well as unstructured (e.g., clinician notes). Some data comes across in streams such as that taken from patient monitors, while some comes in batch form. Still other data comes in near-real time such as HL7 messages. All of this data has retention policies dictating how long it must be stored. Much of this data is stored in perpetuity as many systems in use today have no purge mechanism. AWS has services to manage all these data types as well as their retention, security and access policies.
Imaging is a significant contributor to this data tsunami. Increasing demand for early-stage diagnoses along with aging populations drive increasing demand for images from CT, PET, MRI, ultrasound, digital pathology, X-ray and fluoroscopy. For example, a thin-slice CT image can be hundreds of megabytes. Increasing demand and strict retention policies make storage costly.
Due to the plummeting cost of gene sequencing, molecular diagnostics (including liquid biopsy) is a large contributor to this data deluge. Many predict that as the value of molecular testing becomes more identifiable, the reimbursement models will change and it will increasingly become the standard of care. According to the Washington Post article “Sequencing the Genome Creates so Much Data We Don’t Know What to do with It,”
“Some researchers predict that up to one billion people will have their genome sequenced by 2025 generating up to 40 exabytes of data per year.”
Although genomics is primarily used for oncology diagnostics today, it’s also used for other purposes, pharmacogenomics — used to understand how an individual will metabolize a medication.
Reference Architecture
It is increasingly challenging for the typical hospital, clinic or physician practice to securely store, process and manage this data without cloud adoption.
Amazon has a variety of ingestion techniques depending on the nature of the data including size, frequency and structure. AWS Snowball and AWS Snowmobile are appropriate for extremely-large, secure data transfers whether one time or episodic. AWS Glue is a fully-managed ETL service for securely moving data from on-premise to AWS and Amazon Kinesis can be used for ingesting streaming data.
Amazon S3, Amazon S3 IA, and Amazon Glacier are economical, data-storage services with a pay-as-you-go pricing model that expand (or shrink) with the customer’s requirements.
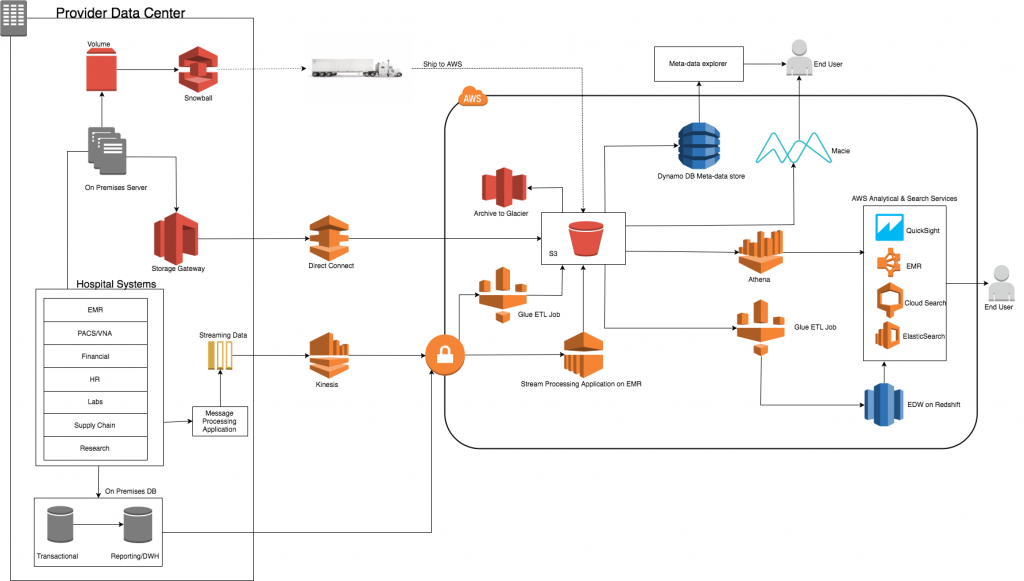
The above architecture has four distinct components – ingestion, storage, security, and analytics. In this post I will dive deeper into the first three components, namely ingestion, storage and security. In part 2, I will look at how to use AWS’ analytics services to draw value on, and optimize, your healthcare data.
Ingestion

A typical provider data center will consist of many systems with varied datasets. AWS provides multiple tools and services to effectively and securely connect to these data sources and ingest data in various formats. The customers can choose from a range of services and use them in accordance with the use case.
For use cases involving one-time (or periodic), very large data migrations into AWS, customers can take advantage of AWS Snowball devices. These devices come in two sizes, 50 TB and 80 TB and can be combined together to create a petabyte scale data transfer solution.
The devices are easy to connect and load and they are shipped to AWS avoiding the network bottlenecks associated with such large-scale data migrations. The devices are extremely secure supporting 256-bit encryption and come in a tamper-resistant enclosure. AWS Snowball imports data in Amazon S3 which can then interface with other AWS compute services to process that data in a scalable manner.
For use cases involving a need to store a portion of datasets on premises for active use and offload the rest on AWS, the Amazon storage gateway service can be used. The service allows you to seamlessly integrate on premises applications via standard storage protocols like iSCSI or NFS mounted on a gateway appliance. It supports a file interface, a volume interface and a tape interface which can be utilized for a range of use cases like disaster recovery, backup and archiving, cloud bursting, storage tiering and migration.
The AWS Storage Gateway appliance can use the AWS Direct Connect service to establish a dedicated network connection from the on premises data center to AWS.
Specific Industry Use Cases
By using the AWS proposed reference architecture for disaster recovery, healthcare providers can ensure their data assets are securely stored on the cloud and are easily accessible in the event of a disaster. The “AWS Disaster Recovery” whitepaper includes details on options available to customers based on their desired recovery time objective (RTO) and recovery point objective (RPO).
AWS is an ideal destination for offloading large volumes of less-frequently-accessed data. These datasets are rarely used in active compute operations but are exceedingly important to retain for reasons like compliance. By storing these datasets on AWS, customers can take advantage of the highly-durable platform to securely store their data and also retrieve them easily when they need to. For more details on how AWS enables customers to run back and archival use cases on AWS, please refer to the following set of whitepapers.
A healthcare provider may have a variety of databases spread throughout the hospital system supporting critical applications such as EHR, PACS, finance and many more. These datasets often need to be aggregated to derive information and calculate metrics to optimize business processes. AWS Glue is a fully-managed Extract, Transform and Load (ETL) service that can read data from a JDBC-enabled, on-premise database and transfer the datasets into AWS services like Amazon S3, Amazon Redshift and Amazon RDS. This allows customers to create transformation workflows that integrate smaller datasets from multiple sources and aggregates them on AWS.
Healthcare providers deal with a variety of streaming datasets which often have to be analyzed in near real time. These datasets come from a variety of sources such as sensors, messaging buses and social media, and often do not adhere to an industry standard. The Amazon Kinesis suite of services, that includes Amazon Kinesis Streams, Amazon Kinesis Firehose, and Amazon Kinesis Analytics, are the ideal set of services to accomplish the task of deriving value from streaming data.
Example: Using AWS Glue to de-identify and ingest healthcare data into S3
Let’s consider a scenario in which a provider maintains patient records in a database they want to ingest into S3. The provider also wants to de-identify the data by stripping personally- identifiable attributes and store the non-identifiable information in an S3 bucket. This bucket is different from the one that contains identifiable information. Doing this allows the healthcare provider to separate sensitive information with more restrictions set up via S3 bucket policies.
To ingest records into S3, we create a Glue job that reads from the source database using a Glue connection. The connection is also used by a Glue crawler to populate the Glue data catalog with the schema of the source database. We will use the Glue development endpoint and a zeppelin notebook server on EC2 to develop and execute the job.
Step 1: Import the necessary libraries and also set a glue context which is a wrapper on the spark context:

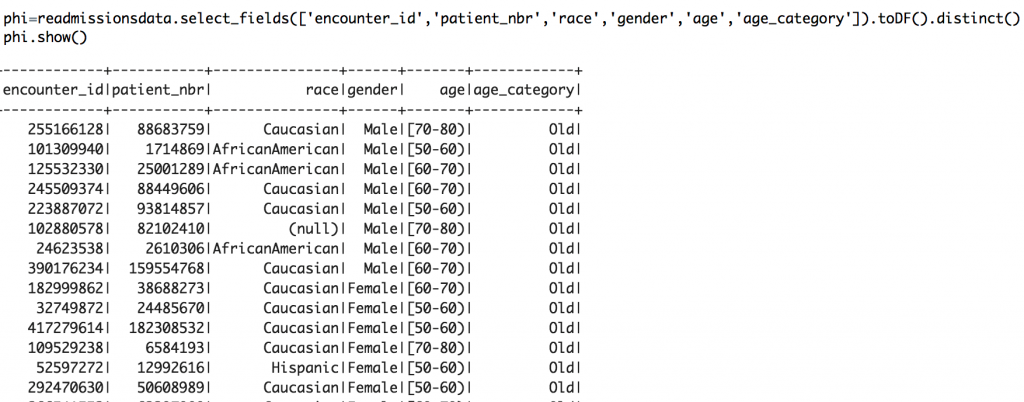
Step 2: Create a dataframe from the source data. I call the dataframe “readmissionsdata”. Here is what the schema would look like:

Step 3: Now select the columns that contains indentifiable information and store it in a new dataframe. Call the new dataframe “phi”.
Step 4: Non-PHI columns are stored in a separate dataframe. Call this dataframe “nonphi”.

Step 5: Write the two dataframes into two separate S3 buckets

Once successfully executed, the PHI and non-PHI attributes are stored in two separate files in two separate buckets that can be individually maintained.
Storage
In 2016, 327 healthcare providers reported a protected health information (PHI) breach, affecting 16.4m patient records[1]. There have been 342 data breaches reported in 2017 — involving 3.2 million patient records.[2]
To date, AWS has released 51 HIPAA-eligible services* to help customers address security challenges and is in the process of making many more services HIPAA-eligible. These HIPAA-eligible services (along with all other AWS services) help customers build solutions that comply with HIPAA security and auditing requirements. A catalogue of HIPAA-enabled services can be found at AWS HIPAA-eligible services. It is important to note that AWS manages physical and logical access controls for the AWS boundary. However, the overall security of your workloads is a shared responsibility, where you are responsible for controlling user access to content on your AWS accounts.
AWS storage services allow you to store data efficiently while maintaining high durability and scalability. By using Amazon S3 as the central storage layer, you can take advantage of the Amazon S3 storage management features to get operational metrics on your data sets and transition them between various storage classes to save costs. By tagging objects on Amazon S3, you can build a governance layer on Amazon S3 to grant role based access to objects using Amazon IAM and Amazon S3 bucket policies.

To learn more about the Amazon S3 storage management features, see the following link.
Security
In the example above, we are storing the PHI information in a bucket named “phi.” Now, we want to protect this information to make sure its encrypted, does not have unauthorized access, and all access requests to the data are logged.
Encryption: S3 provides settings to enable default encryption on a bucket. This ensures any object in the bucket is encrypted by default.
Logging: S3 provides object level logging that can be used to capture all API calls to the object. The API calls are logged in cloudtrail for easy access and consolidation. Moreover, it also supports events to proactively alert customers of read and write operations.
Access control: Customers can use S3 bucket policies and IAM policies to restrict access to the phi bucket. It can also put a restriction to enforce multi-factor authentication on the bucket. For example, the following policy enforces multi-factor authentication on the phi bucket:
"Version": "2012-10-17",
"Id": "123",
"Statement": [
{
"Sid": "",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": "arn:aws:s3:::phi/*",
"Condition": { "Null": { "aws:MultiFactorAuthAge": true } }
},
{
"Sid": "",
"Effect": "Allow",
"Principal": "*",
"Action": ["s3:GetObject"],
"Resource": "arn:aws:s3:::phi/*"
}
]
}
Conclusion
In Part 1 of this blog, we detailed the ingestion, storage, security and management of healthcare data on AWS. Stay tuned for part two where we are going to dive deep into optimizing the data for analytics and machine learning.
[1] “Largest Healthcare Data Breaches of 2016.” HIPAA Journal, 29 Aug. 2017
[2] “Largest Healthcare Data Breaches of 2017.” HIPAA Journal, 8 Mar. 2018
About the Author
Stephen Jepsen is a Globa l HCLS Practice Manager in AWS Professional Services.
l HCLS Practice Manager in AWS Professional Services.
相關推薦
Store, Protect, Optimize Your Healthcare Data with AWS: Part 1
This blog post was co-authored by Ujjwal Ratan, a senior AI/ML solutions architect on the global life sciences team. Healthcare data is ge
Transform your manufacturing operations with AWS Cloud
Amazon Web Services (AWS) secure, agile, and scalable platform and comprehensive set of, data lake, analytics, and machine learning tools allow y
Containerize your IOT application with AWS IOT Analytics
Overview In an earlier blog post about IoT Analytics, we discussed how AWS IoT Analytics enables you to collect, visualize, process, query
Collect, Structure, and Search Industrial IoT data with AWS IoT SiteWise
AWS IoT SiteWise is a managed service that makes it easy to collect and organize data from industrial equipment at scale. You can easily monitor
Modern Data Lake with Minio : Part 1
轉自:https://blog.minio.io/modern-data-lake-with-minio-part-1-716a49499533 Modern data lakes are now built on cloud storage, helping organizations lever
Understanding Data and Machine Learning Models with Visualizations (Part 1)
Examining Feature-PC CorrelationOn the non-interactive side, the tool also generates heatmaps with additional information about the principal components. T
Creating visualizations to better understand your data and models (Part 1)
The Cancer Genome Atlas Breast Cancer DatasetThe Cancer Genome Atlas (TCGA) breast cancer RNA-Seq dataset (I’m using an old freeze from 2015) has 20,532 fe
My story of learning iOS Development with Swift (Part 1)
First of all, I had to choose where to learn it from. I looked at several popular courses, and my final choice was “Developing iOS 11 Apps with Swift” by S
How to Handle Context with Dialogflow (Part 1: Knock Knock Jokes)
Step 1: Build a trigger for the bot to say “Knock Knock”To get the bot to start the “knock knock” joke, you have to trigger it. In this example, we’ll use
Doing Well by Doing Bad: Writing Bad Code with Go Part 1
Doing Well by Doing Bad: Writing Bad Code with Go Part 1A Satirical Take on Programming in GoAfter decades of programming in Java, for the past several yea
Scala for Data Science Engineering — Part 1
Data Science is an interesting field to work in, a combination of statistics and real world programming. There are number of programming languages used by
How to create role based accounts for your Saas App using FEAN? (Part 1)
Setup firebase in your angular app and express js// Front-endng new exampleAppcd exampleApp && cd exampleApp// For adding firebase to angular appng
Selecting Subsets of Data in Pandas: Part 1
Selecting Subsets of Data in Pandas: Part 1This article is available as a Jupyter Notebook complete with exercises at the bottom to practice and detailed s
Authentication Made Easy with Auth0: Part 1
Authentication Made Easy with Auth0: Part 1Through example, we will demonstrate how to use Auth0 to secure a Node.js (Express) API that is accessed by a si
Quickly build, test, and deploy your data lake with AWS and partner solutions
Performing data science workloads on data from disparate sources – data lake, data warehouse, streaming, and more – creates challenges f
轉載 -- How To Optimize Your Site With GZIP Compression
// 下面這篇文章講的非常不錯,看完了 https://betterexplained.com/articles/how-to-optimize-your-site-with-gzip-compression/ // Content-Encoding, 定義 fr
轉載 -- How To Optimize Your Site With HTTP Caching
https://betterexplained.com/articles/how-to-optimize-your-site-with-http-caching/ // Caching Tutorial for Web Authors and Webmasters // 下面
What's new in Python 3 via code snippets, Collect Your Own Fitbit Data with Python and more
Worthy Read
Amazon Kinesis Firehose Data Transformation with AWS Lambda
Shiva Narayanaswamy, Solution Architect Amazon Kinesis Firehose is a fully managed service for delivering real-time streaming data to des
Amazon EBS (Elastic Block Store) – Bring Us Your Data
A few months ago I talked about our plans to offer a persistent storage feature for Amazon EC2. At that time I indicated that the service was in a