
第四章圖演算法總結
該部落格原地址http://blog.csdn.net/ntt5667781/article/details/52743342
其實就是對書上的內容做了個總結
在開始各類圖演算法之前,先將圖的結構進行分類。
圖的表示,在實際實現過程中,有以下幾種基本的方式可以來表示圖。
1) 鄰接矩陣:對於較小或者中等規模的圖的構造較為適用,因為需要V*V大小的空間。
2) 邊的陣列:使用一個簡單的自定義edge類,還有兩個變數,分別代表邊的兩個端點編號,實現簡單,但是在求每個點的鄰接點的時候實現較為困難。
3) 鄰接表陣列:較為常用,使用一個以頂點為索引的陣列,陣列每個元素都是和該頂點相鄰的頂點列表,這種陣列佔空間相對於鄰接矩陣少了很多,並且能很好的找到某個給定點的所有鄰接點。
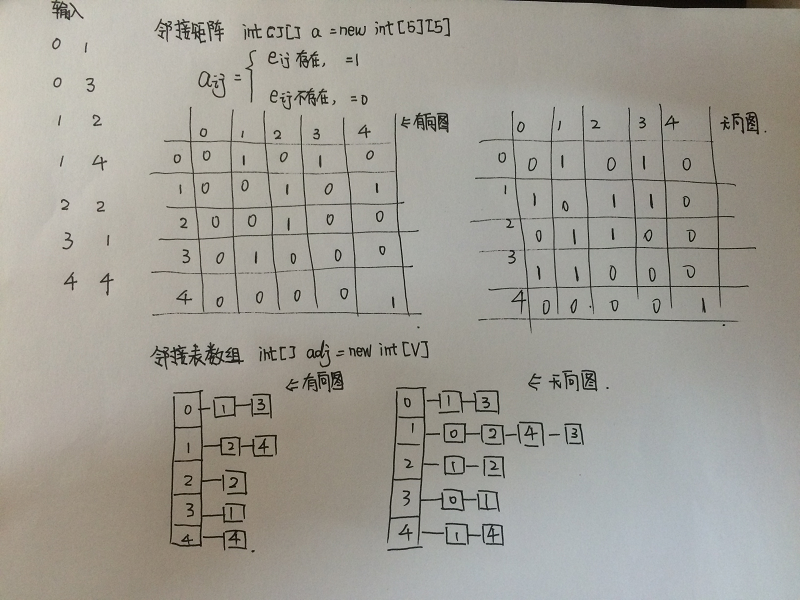
按照圖中邊的方向將圖分成有向圖和無向圖:
1)無向圖:圖中的邊沒有方向。
2)有向圖:圖中的邊有方向。
對於有向圖和無向圖的具體實現表示可以使用前面介紹的三種方法,兩種圖在表示的時候大部分的實現程式碼都是一致的。
普通無向圖的鄰接陣列表示方法的具體實現程式碼:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
無權有向圖的具體實現程式碼:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
一 圖的遍歷演算法:
介紹兩種比較基礎的圖遍歷演算法,廣度優先搜尋和深度優先搜尋。
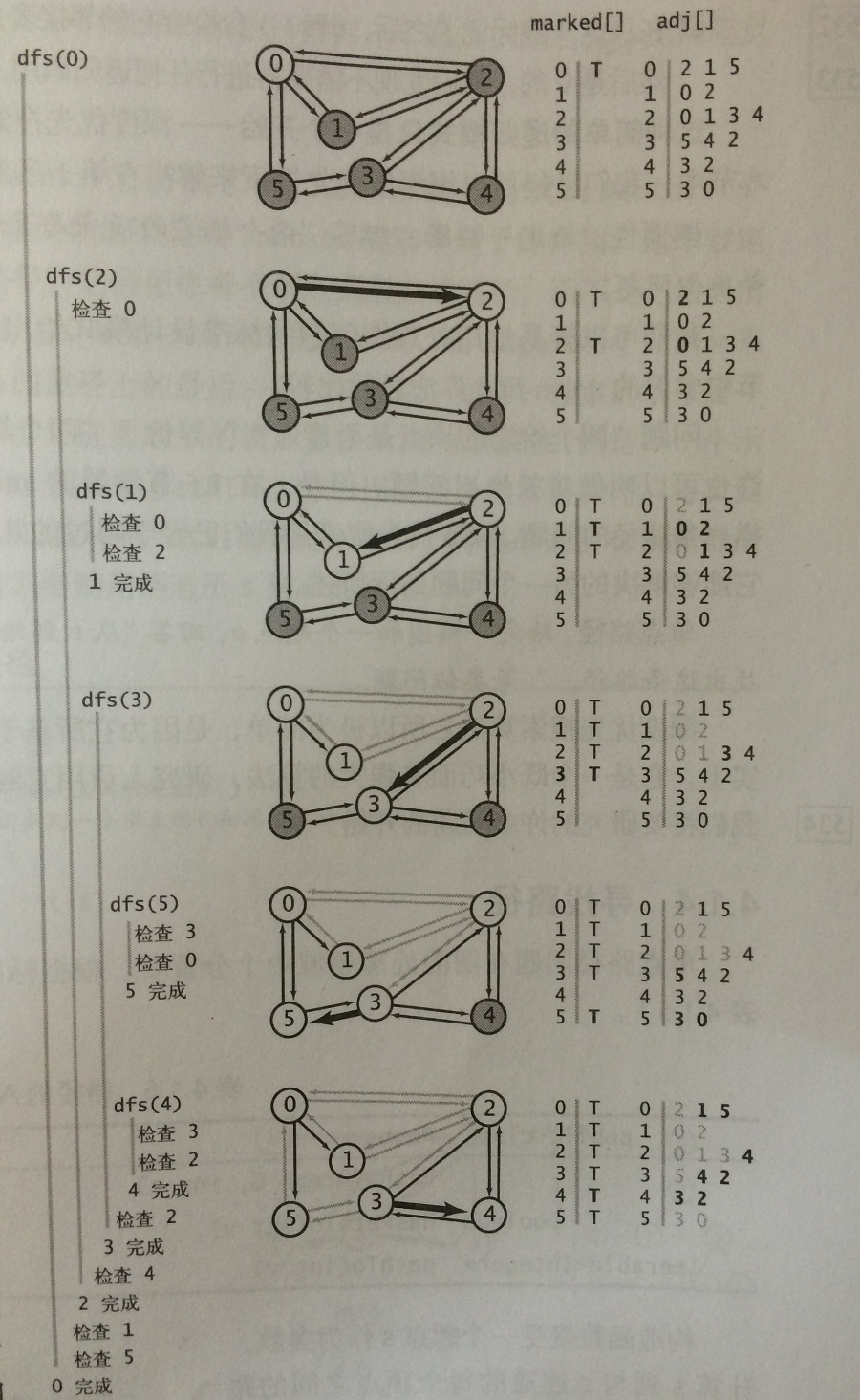
1)深度優先搜尋:這是一種典型的遞迴演算法用來搜尋圖(遍歷所有的頂點);
思想:從圖的某個頂點i開始,將頂點i標記為已訪問頂點,並將訪問頂點i的鄰接列表中沒有被標記的頂點j,將頂點j標記為已訪問,並在訪問頂點j的鄰接列表中未被標記的頂點k依次深度遍歷下去,直到某個點的所有鄰接列表中的點都被標記為已訪問後,返回上層。重複以上過程直到圖中的所有頂點都被標記為已訪問。
深度優先遍歷和樹的先序訪問非常類似,儘可能深的去訪問節點。深度優先遍歷的大致過程(遞迴版本):
a)在訪問一個節點的時候,將其設定為已訪問。
b)遞迴的訪問被標記頂點的鄰接列表中沒有被標記的所有頂點
(非遞迴版本):
圖的非遞迴遍歷我們藉助棧來實現。
a)如果棧為空,則退出程式,否則,訪問棧頂節點,但不彈出棧點節點。
b)如果棧頂節點的所有直接鄰接點都已訪問過,則彈出棧頂節點,否則,將該棧頂節點的未訪問的其中一個鄰接點壓入棧,同時,標記該鄰接點為已訪問,繼續步驟a。
該演算法訪問頂點的順序是和圖的表示有關的,而不只是和圖的結構或者是演算法有關。
深度優先探索是個簡單的遞迴演算法(當然藉助棧也可以實現非遞迴的版本),但是卻能有效的處理很多和圖有關的任務,比如:
a) 連通性:ex:給定的兩個頂點是否聯通 or 這個圖有幾個聯通子圖。
b) 單點路徑:給定一幅圖和一個固定的起點,尋找從s到達給定點的路徑是否存在,若存在,找出這條路徑。
尋找路徑:
為了實現這個功能,需要在上面實現的深度優先搜尋中中增加例項變數edgeTo[],它相當於繩索的功能,這個陣列可以找到從每個與起始點聯通的頂點回到起始點的路徑(具體實現的思路非常巧妙: 從邊v-w第一次訪問w的時候,將edgeTo[w]的值跟新為v來記住這條道路,換句話說,v-w是從s到w的路徑上最後一條已知的邊,這樣搜尋結果就是一條以起始點為根結點的樹,也就是edgeTo[]是個有父連結表示的樹。)
深度優先搜尋的遞迴實現版本和非遞迴版本(遞迴是接住了遞迴中的隱藏棧來實現的。非遞迴,藉助棧實現)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
已經使用DFS解決了一些問題,DFS其實還可以解決很多在無向圖中的基礎性問題,譬如:
1)計算圖中的連通分支的數量;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34