
[看圖說話] 基於Spark UI效能優化與除錯——初級篇
Spark有幾種部署的模式,單機版、叢集版等等,平時單機版在資料量不大的時候可以跟傳統的java程式一樣進行斷電除錯、但是在叢集上除錯就比較麻煩了...遠端斷點不太方便,只能通過Log的形式進行資料分析,利用spark ui做效能調整和優化。

那麼本篇就介紹下如何利用Ui做效能分析,因為本人的經驗也不是很豐富,所以只能作為一個入門的介紹。
大體上會按照下面的思路進行講解:
- 怎麼訪問Spark UI
- SparkUI能看到什麼東西?job,stage,storage,environment,excutors
- 調優的一些經驗總結
在這裡相信有許多想要學習大資料的同學,大家可以+下大資料學習裙:716加上【五8一】最後014,即可免費領取大資料學習教程
Spark UI入口
如果是單機版本,在單機除錯的時候輸出資訊中已經提示了UI的入口:
17/02/26 13:55:48 INFO SparkEnv: Registering OutputCommitCoordinator 17/02/26 13:55:49 INFO Utils: Successfully started service 'SparkUI' on port 4040. 17/02/26 13:55:49 INFO SparkUI: Started SparkUI at http://192.168.1.104:4040 17/02/26 13:55:49 INFO Executor: Starting executor ID driver on host localhost
如果是叢集模式,可以通過Spark日誌伺服器xxxxx:18088者yarn的UI進入到應用xxxx:8088,進入相應的Spark UI介面。
主頁介紹
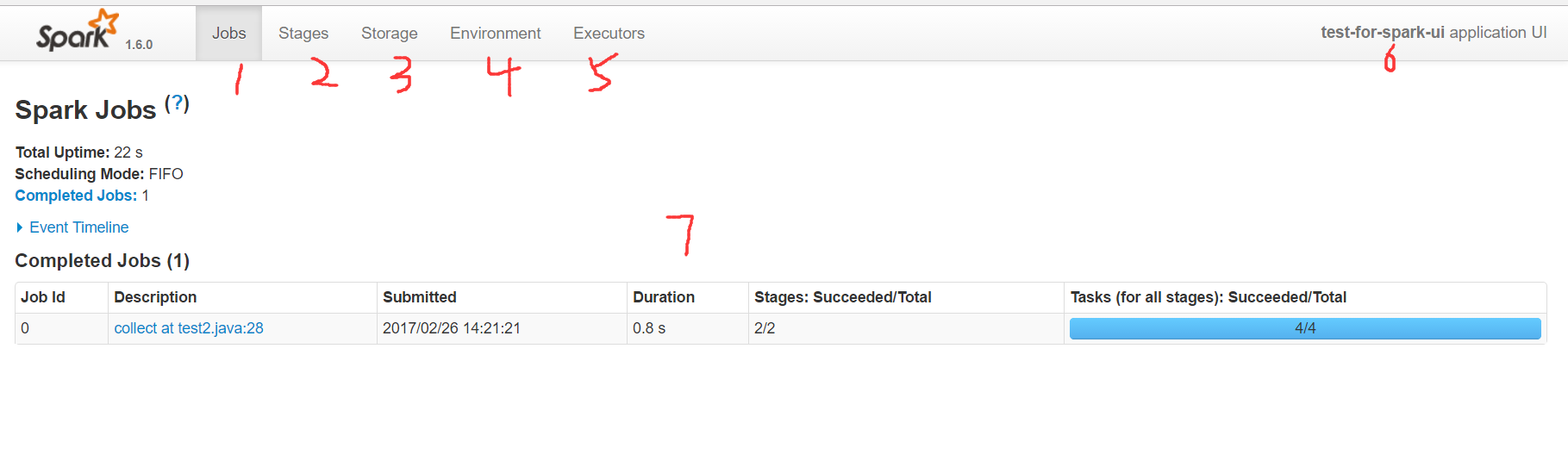
上面就是Spark的UI主頁,首先進來能看到的是Spark當前應用的job頁面,在上面的導航欄:
- 1 代表job頁面,在裡面可以看到當前應用分析出來的所有任務,以及所有的excutors中action的執行時間。
- 2 代表stage頁面,在裡面可以看到應用的所有stage,stage是按照寬依賴來區分的,因此粒度上要比job更細一些
- 3 代表storage頁面,我們所做的cache persist等操作,都會在這裡看到,可以看出來應用目前使用了多少快取
- 4 代表environment頁面,裡面展示了當前spark所依賴的環境,比如jdk,lib等等
- 5 代表executors頁面,這裡可以看到執行者申請使用的記憶體以及shuffle中input和output等資料
- 6 這是應用的名字,程式碼中如果使用setAppName,就會顯示在這裡
- 7 是job的主頁面。
模組講解
下面挨個介紹一下各個頁面的使用方法和實踐,為了方便分析,我這裡直接使用了分散式計算裡面最經典的helloworld程式——WordCount,這個程式用於統計某一段文字中一個單詞出現的次數。原始的文字如下:
for the shadow of lost knowledge at least protects you from many illusions
上面這句話是有一次逛知乎,一個標題為 讀那麼多書,最後也沒記住多少,還為什麼讀書?其中有一個回覆,引用了上面的話,也是我最喜歡的一句。意思是:“知識,哪怕是知識的幻影,也會成為你的鎧甲,保護你不被愚昧反噬”(來自知乎——《為什麼讀書?》)
程式程式碼如下:
public static void main(String[] args) throws InterruptedException {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local[2]");
sparkConf.setAppName("test-for-spark-ui");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
//知識,哪怕是知識的幻影,也會成為你的鎧甲,保護你不被愚昧反噬。
JavaPairRDD<String,Integer> counts = sc.textFile( "C:\\Users\\xinghailong\\Desktop\\你為什麼要讀書.txt" )
.flatMap(line -> Arrays.asList(line.split(" ")).iterator())
.mapToPair(s -> new Tuple2<String,Integer>(s,1))
.reduceByKey((x,y) -> x+y);
counts.cache();
List<Tuple2<String,Integer>> result = counts.collect();
for(Tuple2<String,Integer> t2 : result){
System.out.println(t2._1+" : "+t2._2);
}
sc.stop();
}這個程式首先建立了SparkContext,然後讀取檔案,先使用` `進行切分,再把每個單詞轉換成二元組,再根據key進行累加,最後輸出列印。為了測試storage的使用,我這對計算的結果添加了快取。
job頁面
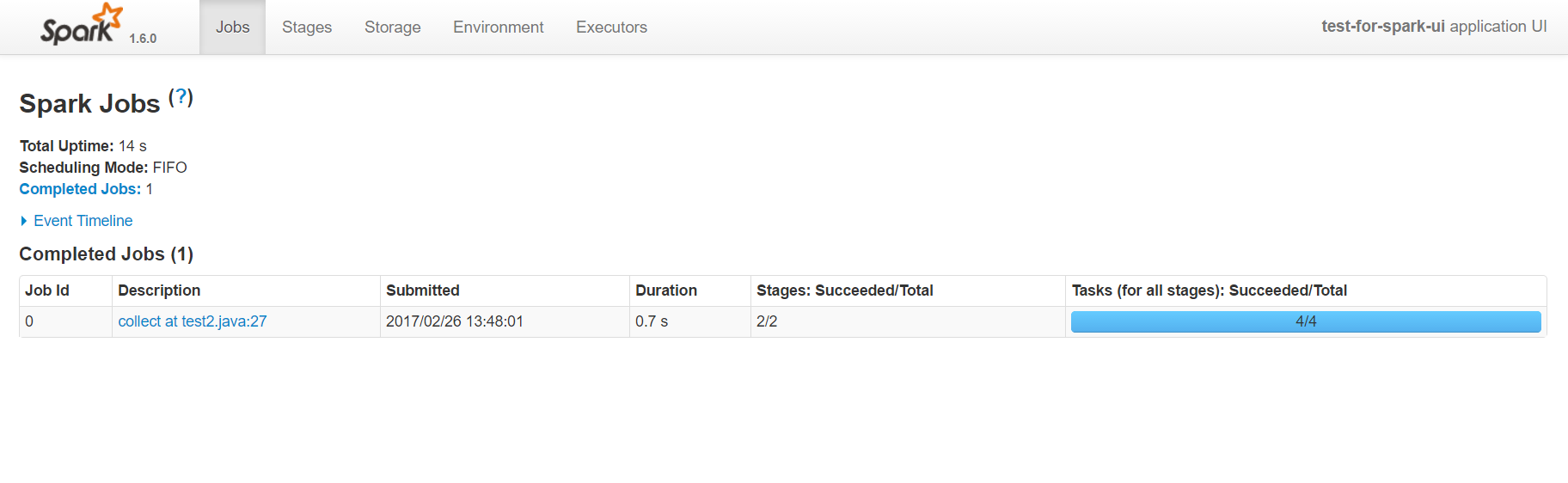
主頁可以分為兩部分,一部分是event timeline,另一部分是進行中和完成的job任務。
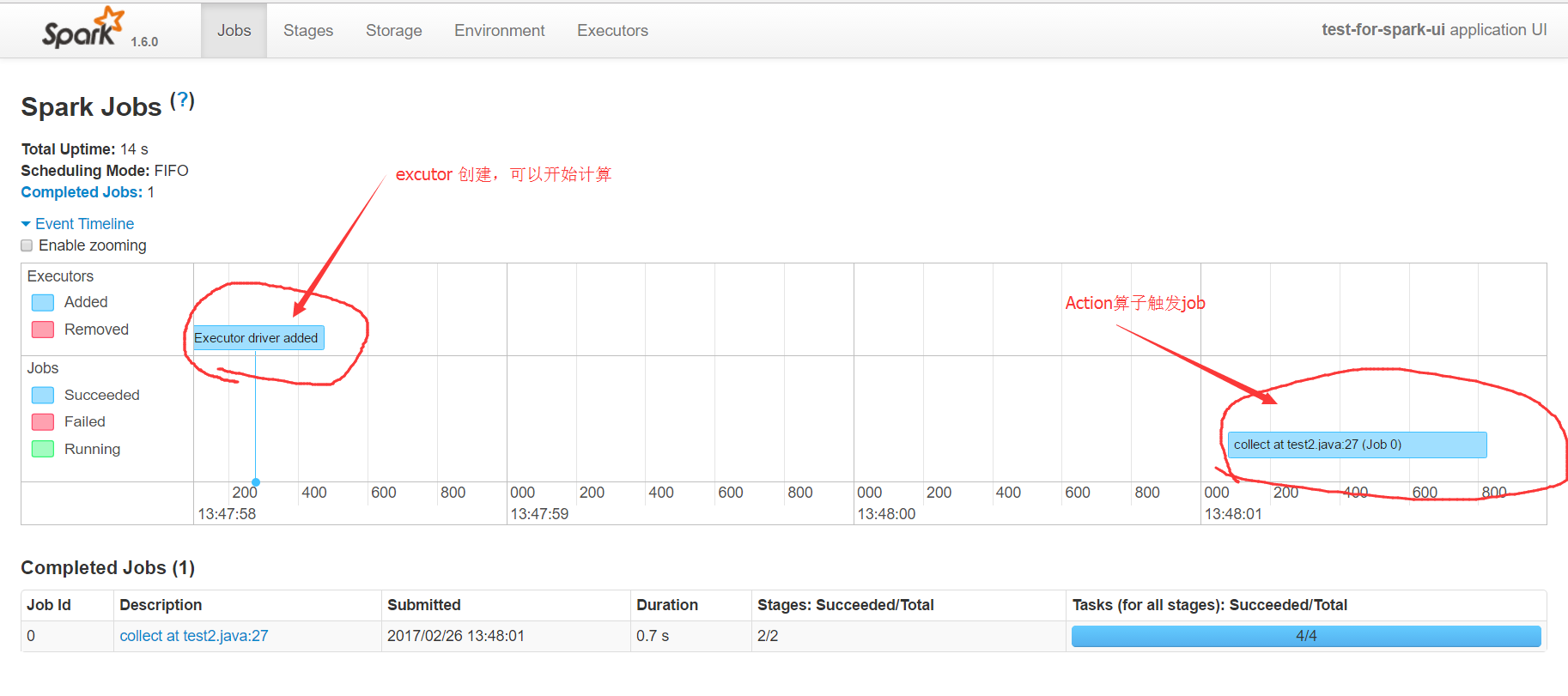
第一部分event timeline展開後,可以看到executor建立的時間點,以及某個action觸發的運算元任務,執行的時間。通過這個時間圖,可以快速的發現應用的執行瓶頸,觸發了多少個action。
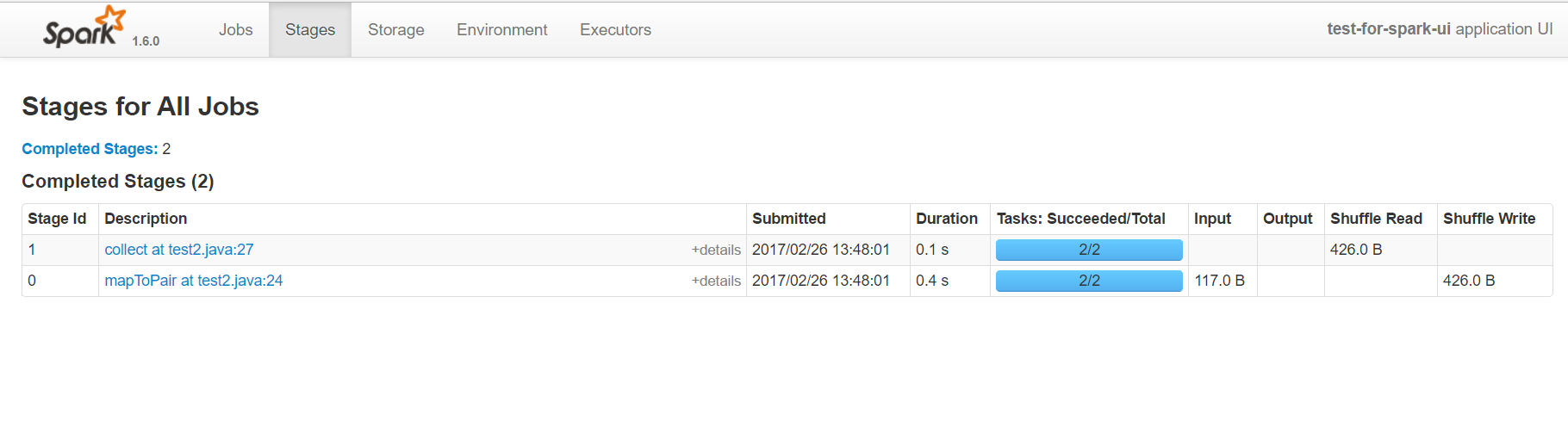
第二部分的圖表,顯示了觸發action的job名字,它通常是某個count,collect等操作。有spark基礎的人都應該知道,在spark中rdd的計算分為兩類,一類是transform轉換操作,一類是action操作,只有action操作才會觸發真正的rdd計算。具體的有哪些action可以觸發計算,可以參考api。collect at test2.java:27描述了action的名字和所在的行號,這裡的行號是精準匹配到程式碼的,所以通過它可以直接定位到任務所屬的程式碼,這在除錯分析的時候是非常有幫助的。Duration顯示了該action的耗時,通過它也可以對程式碼進行專門的優化。最後的進度條,顯示了該任務失敗和成功的次數,如果有失敗的就需要引起注意,因為這種情況在生產環境可能會更普遍更嚴重。點選能進入該action具體的分析頁面,可以看到DAG圖等詳細資訊。
stage頁面
在Spark中job是根據action操作來區分的,另外任務還有一個級別是stage,它是根據寬窄依賴來區分的。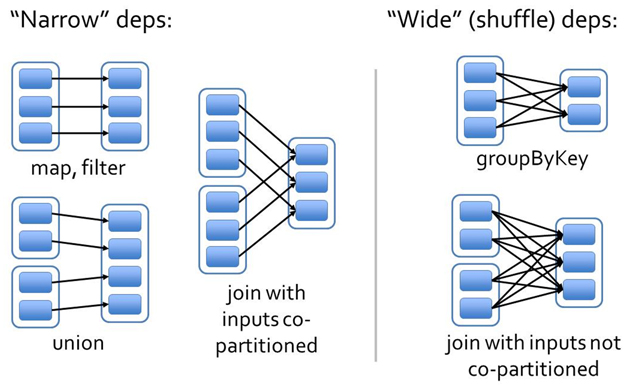
窄依賴是指前一個rdd計算能出一個唯一的rdd,比如map或者filter等;寬依賴則是指多個rdd生成一個或者多個rdd的操作,比如groupbykey reducebykey等,這種寬依賴通常會進行shuffle。
因此Spark會根據寬窄依賴區分stage,某個stage作為專門的計算,計算完成後,會等待其他的executor,然後再統一進行計算。
stage頁面的使用基本上跟job類似,不過多了一個DAG圖。這個DAG圖也叫作血統圖,標記了每個rdd從建立到應用的一個流程圖,也是我們進行分析和調優很重要的內容。比如上面的wordcount程式,就會觸發acton,然後生成一段DAG圖:
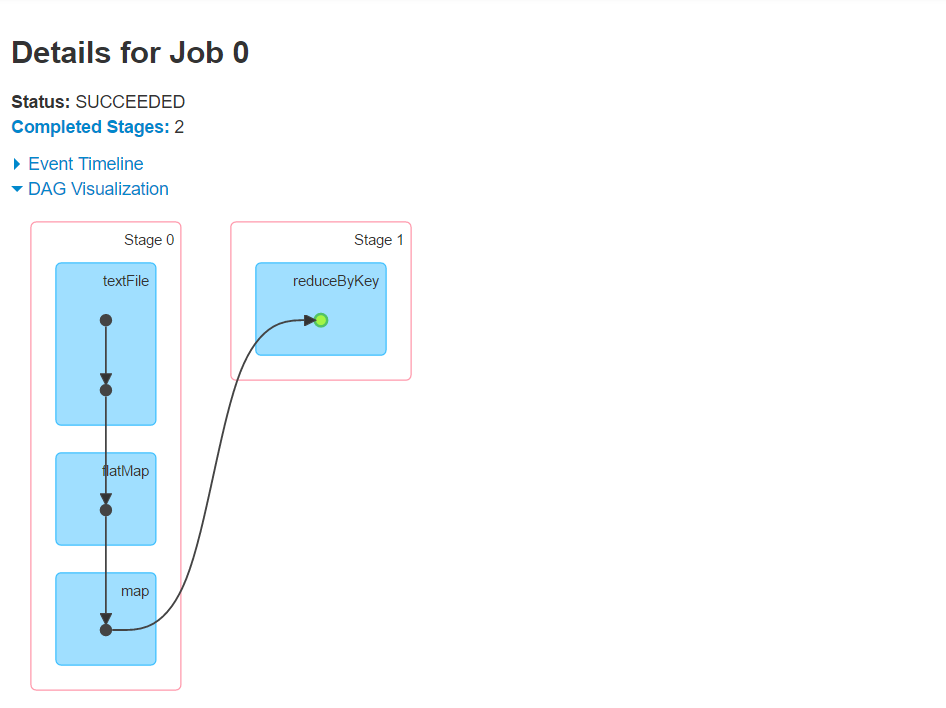
從這個圖可以看出,wordcount會生成兩個dag,一個是從讀資料到切分到生成二元組,第二個進行了reducebykey,產生shuffle。
點選進去還可以看到詳細的DAG圖,滑鼠移到上面,可以看到一些簡要的資訊。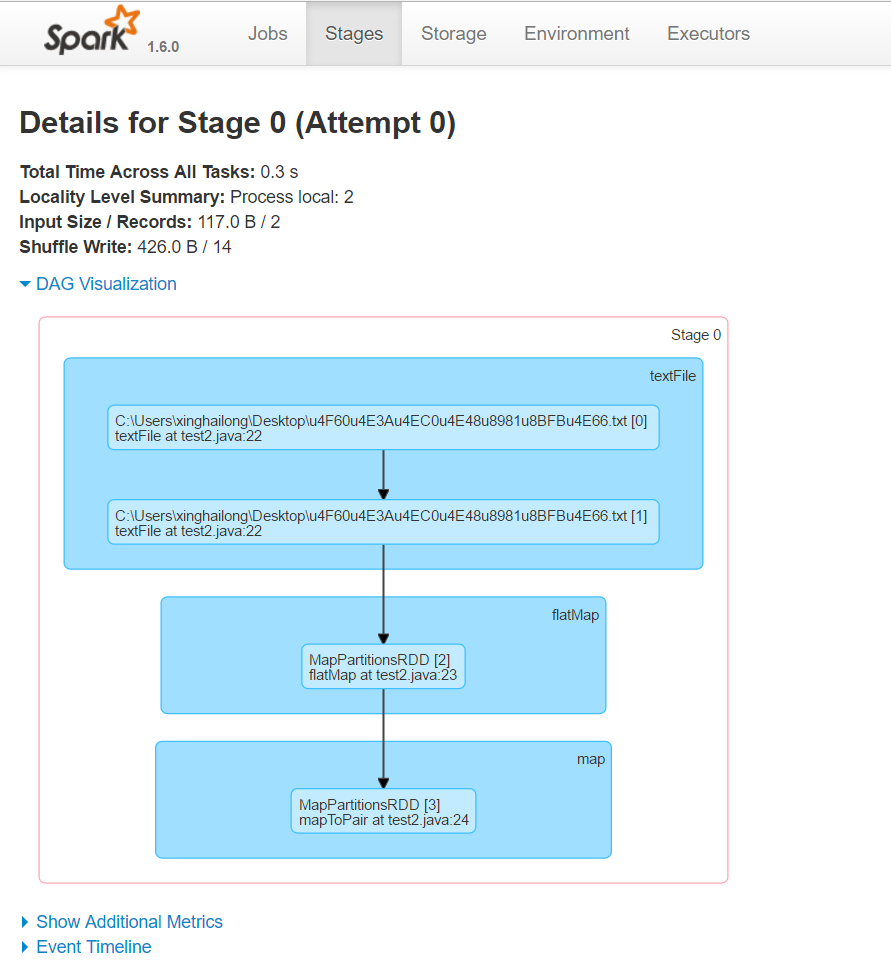
storage頁面
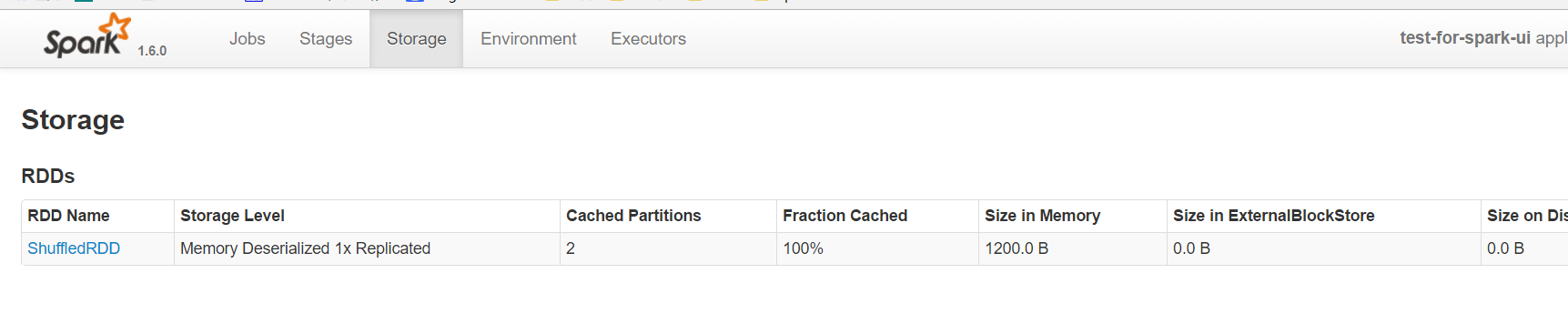
storage頁面能看出目前使用的快取,點選進去可以看到具體在每個機器上,使用的block的情況。
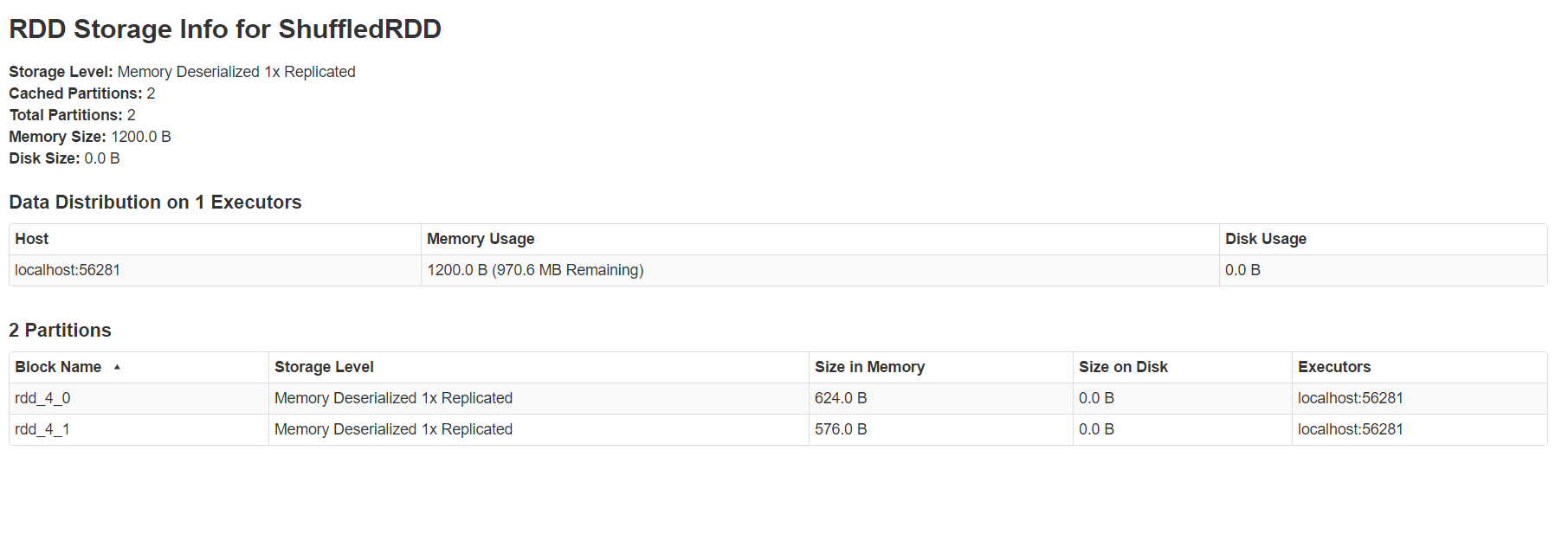
environment頁面
這個頁面一般不太用,因為環境基本上不會有太多差異的,不用時刻關注它。
excutors頁面
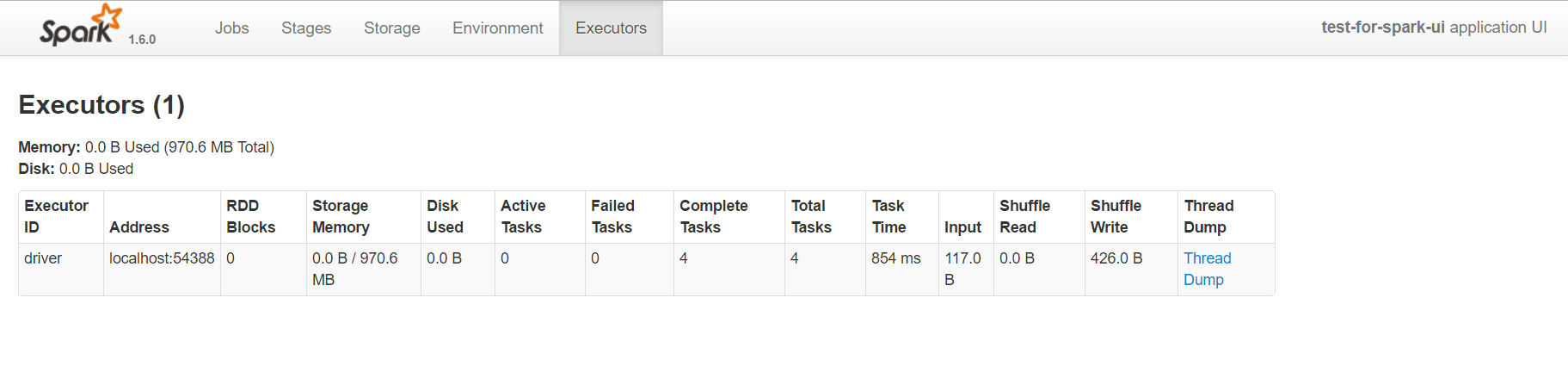
這個頁面比較常用了,一方面通過它可以看出來每個excutor是否發生了資料傾斜,另一方面可以具體分析目前的應用是否產生了大量的shuffle,是否可以通過資料的本地性或者減小資料的傳輸來減少shuffle的資料量。
調優的經驗總結
1 輸出資訊
在Spark應用裡面可以直接使用System.out.println把資訊輸出出來,系統會直接攔截out輸出到spark的日誌。像我們使用的yarn作為資源管理系統,在yarn的日誌中就可以直接看到這些輸出資訊了。這在資料量很大的時候,做一些show()(預設顯示20),count() 或者 take(10)的時候會很方便。
2 記憶體不夠
當任務失敗,收到sparkContext shutdown的資訊時,基本都是執行者的記憶體不夠。這個時候,一方面可以調大--excutor-memory引數,另一方面還是得回去看看程式。如果受限於系統的硬體條件,無法加大記憶體,可以採用區域性除錯法,檢查是在哪裡出現的記憶體問題。比如,你的程式分成幾個步驟,一步一步的打包執行,最後檢查出現問題的點就可以了。
3 ThreadPool
執行緒池不夠,這個是因為--excutor-core給的太少了,出現執行緒池不夠用的情況。這個時候就需要調整引數的配置了。
4 physical memory不夠

這種問題一般是driver memory不夠導致的,driver memory通常儲存了以一些排程方面的資訊,這種情況很有可能是你的排程過於複雜,或者是內部死迴圈導致。
5 合理利用快取
在Spark的計算中,不太建議直接使用cache,萬一cache的量很大,可能導致記憶體溢位。可以採用persist的方式,指定快取的級別為MEMORY_AND_DISK,這樣在記憶體不夠的時候,可以把資料快取到磁碟上。另外,要合理的設計程式碼,恰當地使用廣播和快取,廣播的資料量太大會對傳輸帶來壓力,快取過多未及時釋放,也會導致記憶體佔用。一般來說,你的程式碼在需要重複使用某一個rdd的時候,才需要考慮進行快取,並且在不使用的時候,要及時unpersist釋放。
6 儘量避免shuffle
這個點,在優化的過程中是很重要的。比如你需要把兩個rdd按照某個key進行groupby,然後在進行leftouterjoin,這個時候一定要考慮大小表的問題。如果把大表關聯到小表,那麼效能很可能會很慘。而只需要簡單的調換一下位置,效能就可能提升好幾倍。
寫在最後
大資料計算總是充滿了各種神奇的色彩,節點之間的分散式,單節點內多執行緒的並行化,只有多去了解一些原理性的東西,才能用好這些工具。
最後還是獻上最喜歡的那句話——知識,哪怕是知識的幻影,也會成為你的鎧甲,保護你不被愚昧反噬。