
Spark SQL 效能優化再進一步 CBO 基於代價的優化
原創文章,轉載請務必將下面這段話置於文章開頭處。
本文轉發自技術世界,原文連結 http://www.jasongj.com/spark/cbo/
本文所述內容均基於 2018年9月17日 Spark 最新 Release 2.3.1 版本。後續將持續更新
Spark CBO 背景
上文Spark SQL 內部原理中介紹的 Optimizer 屬於 RBO,實現簡單有效。它屬於 LogicalPlan 的優化,所有優化均基於 LogicalPlan 本身的特點,未考慮資料本身的特點,也未考慮運算元本身的代價。
本文將介紹 CBO,它充分考慮了資料本身的特點(如大小、分佈)以及操作運算元的特點(中間結果集的分佈及大小)及代價,從而更好的選擇執行代價最小的物理執行計劃,即 SparkPlan。
Spark CBO 原理
CBO 原理是計算所有可能的物理計劃的代價,並挑選出代價最小的物理執行計劃。其核心在於評估一個給定的物理執行計劃的代價。
物理執行計劃是一個樹狀結構,其代價等於每個執行節點的代價總合,如下圖所示。
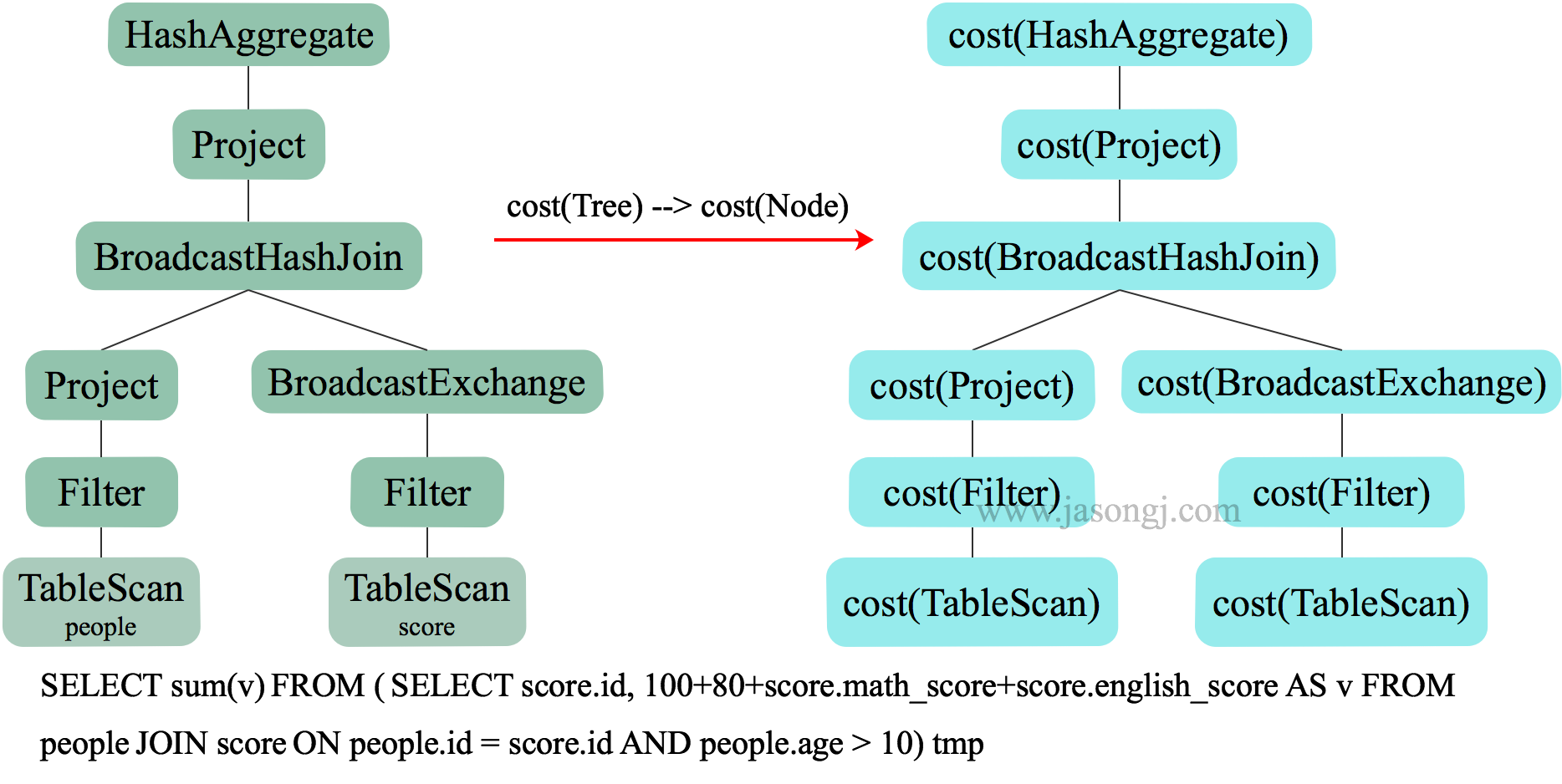
而每個執行節點的代價,分為兩個部分
- 該執行節點對資料集的影響,或者說該節點輸出資料集的大小與分佈
- 該執行節點操作運算元的代價
每個操作運算元的代價相對固定,可用規則來描述。而執行節點輸出資料集的大小與分佈,分為兩個部分:1) 初始資料集,也即原始表,其資料集的大小與分佈可直接通過統計得到;2)中間節點輸出資料集的大小與分佈可由其輸入資料集的資訊與操作本身的特點推算。
所以,最終主要需要解決兩個問題
- 如何獲取原始資料集的統計資訊
- 如何根據輸入資料集估算特定運算元的輸出資料集
Statistics 收集
通過如下 SQL 語句,可計算出整個表的記錄總數以及總大小
ANALYZE TABLE table_name COMPUTE STATISTICS;
從如下示例中,Statistics 一行可見, customer 表資料總大小為 37026233 位元組,即 35.3MB,總記錄數為 28萬,與事實相符。
spark-sql> ANALYZE TABLE customer COMPUTE STATISTICS;
Time taken: 12.888 通過如下 SQL 語句,可計算出指定列的統計資訊
ANALYZE TABLE table_name COMPUTE STATISTICS FOR COLUMNS [column1] [,column2] [,column3] [,column4] ... [,columnn];
從如下示例可見,customer 表的 c_customer_sk 列最小值為 1, 最大值為 280000,null 值個數為 0,不同值個數為 274368,平均列長度為 8,最大列長度為 8。
spark-sql> ANALYZE TABLE customer COMPUTE STATISTICS FOR COLUMNS c_customer_sk, c_customer_id, c_current_cdemo_sk;
Time taken: 9.139 seconds
spark-sql> desc extended customer c_customer_sk;
col_name c_customer_sk
data_type bigint
comment NULL
min 1
max 280000
num_nulls 0
distinct_count 274368
avg_col_len 8
max_col_len 8
histogram NULL
除上述示例中的統計資訊外,Spark CBO 還直接等高直方圖。在上例中,histogram 為 NULL。其原因是,spark.sql.statistics.histogram.enabled 預設值為 false,也即 ANALYZE 時預設不計算及儲存 histogram。
下例中,通過 SET spark.sql.statistics.histogram.enabled=true; 啟用 histogram 後,完整的統計資訊如下。
spark-sql> ANALYZE TABLE customer COMPUTE STATISTICS FOR COLUMNS c_customer_sk,c_customer_id,c_current_cdemo_sk,c_current_hdemo_sk,c_current_addr_sk,c_first_shipto_date_sk,c_first_sales_date_sk,c_salutation,c_first_name,c_last_name,c_preferred_cust_flag,c_birth_day,c_birth_month,c_birth_year,c_birth_country,c_login,c_email_address,c_last_review_date;
Time taken: 125.624 seconds
spark-sql> desc extended customer c_customer_sk;
col_name c_customer_sk
data_type bigint
comment NULL
min 1
max 280000
num_nulls 0
distinct_count 274368
avg_col_len 8
max_col_len 8
histogram height: 1102.3622047244094, num_of_bins: 254
bin_0 lower_bound: 1.0, upper_bound: 1090.0, distinct_count: 1089
bin_1 lower_bound: 1090.0, upper_bound: 2206.0, distinct_count: 1161
bin_2 lower_bound: 2206.0, upper_bound: 3286.0, distinct_count: 1124
...
bin_251 lower_bound: 276665.0, upper_bound: 277768.0, distinct_count: 1041
bin_252 lower_bound: 277768.0, upper_bound: 278870.0, distinct_count: 1098
bin_253 lower_bound: 278870.0, upper_bound: 280000.0, distinct_count: 1106
從上圖可見,生成的 histogram 為 equal-height histogram,且高度為 1102.36,bin 數為 254。其中 bin 個數可由 spark.sql.statistics.histogram.numBins 配置。對於每個 bin,勻記錄其最小值,最大值,以及 distinct count。
值得注意的是,這裡的 distinct count 並不是精確值,而是通過 HyperLogLog 計算出來的近似值。使用 HyperLogLog 的原因有二
- 使用 HyperLogLog 計算 distinct count 速度快速
- HyperLogLog 計算出的 distinct count 可以合併。例如可以直接將兩個 bin 的 HyperLogLog 值合併算出這兩個 bin 總共的 distinct count,而無須從重新計算,且合併結果的誤差可控
運算元對資料集影響估計
對於中間運算元,可以根據輸入資料集的統計資訊以及運算元的特性,可以估算出輸出資料集的統計結果。
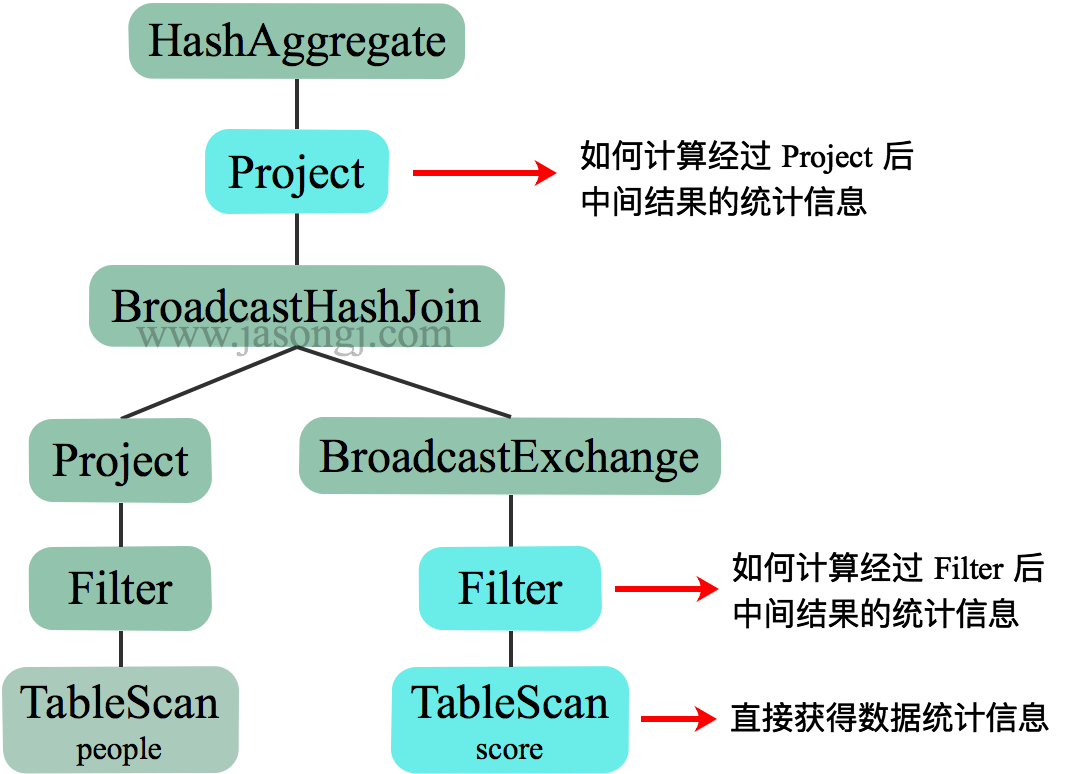
本節以 Filter 為例說明運算元對資料集的影響。
對於常見的 Column A < value B Filter,可通過如下方式估算輸出中間結果的統計資訊
- 若 B < A.min,則無資料被選中,輸出結果為空
- 若 B > A.max,則全部資料被選中,輸出結果與 A 相同,且統計資訊不變
- 若 A.min < B < A.max,則被選中的資料佔比為 (B.value - A.min) / (A.max - A.min),A.min 不變,A.max 更新為 B.value,A.ndv = A.ndv * (B.value - A.min) / (A.max - A.min)
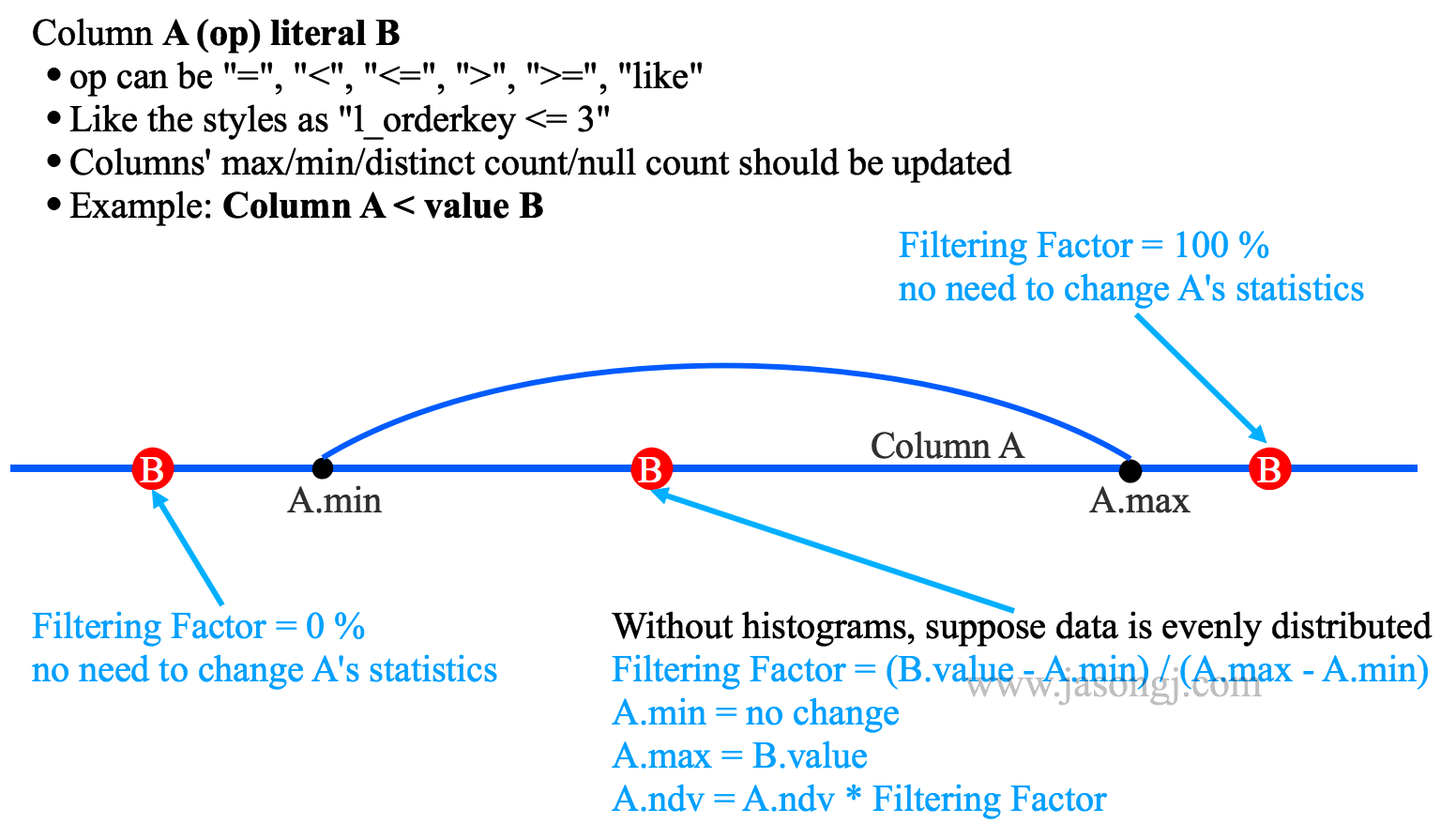
上述估算的前提是,欄位 A 資料均勻分佈。但很多時候,資料分佈並不均勻,且當資料傾斜嚴重是,上述估算誤差較大。此時,可充分利用 histogram 進行更精確的估算
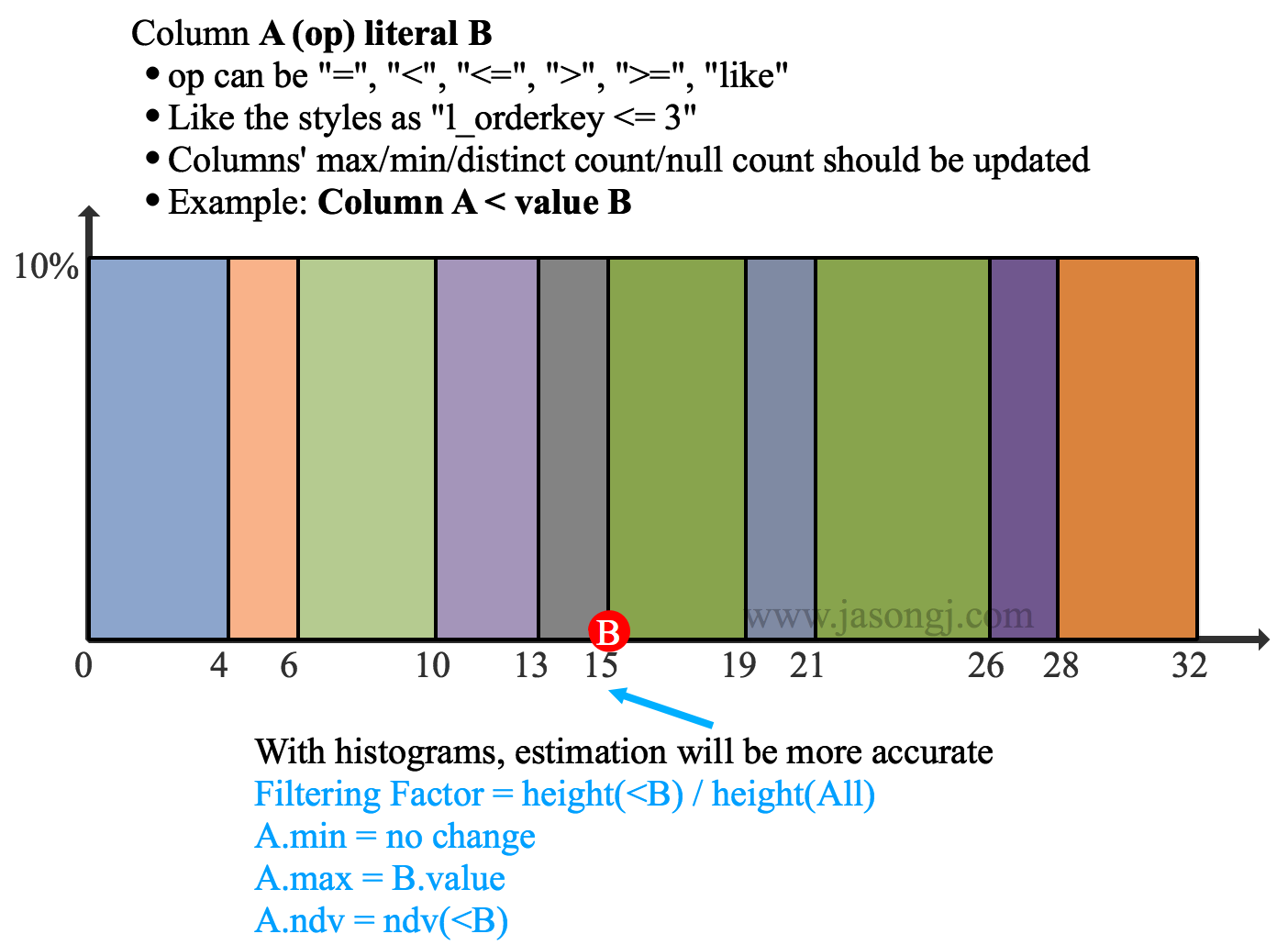
啟用 Historgram 後,Filter Column A < value B的估算方法為
- 若 B < A.min,則無資料被選中,輸出結果為空
- 若 B > A.max,則全部資料被選中,輸出結果與 A 相同,且統計資訊不變
- 若 A.min < B < A.max,則被選中的資料佔比為 height(<B) / height(All),A.min 不變,A.max = B.value,A.ndv = ndv(<B)
在上圖中,B.value = 15,A.min = 0,A.max = 32,bin 個數為 10。Filter 後 A.ndv = ndv(<B.value) = ndv(<15)。該值可根據 A < 15 的 5 個 bin 的 ndv 通過 HyperLogLog 合併而得,無須重新計算所有 A < 15 的資料。
運算元代價估計
SQL 中常見的操作有 Selection(由 select 語句表示),Filter(由 where 語句表示)以及笛卡爾乘積(由 join 語句表示)。其中代價最高的是 join。
Spark SQL 的 CBO 通過如下方法估算 join 的代價
Cost = rows * weight + size * (1 - weight)
Cost = CostCPU * weight + CostIO * (1 - weight)
其中 rows 即記錄行數代表了 CPU 代價,size 代表了 IO 代價。weight 由 spark.sql.cbo.joinReorder.card.weight 決定,其預設值為 0.7。
Build側選擇
對於兩表Hash Join,一般選擇小表作為build size,構建雜湊表,另一邊作為 probe side。未開啟 CBO 時,根據表原始資料大小選擇 t2 作為build side
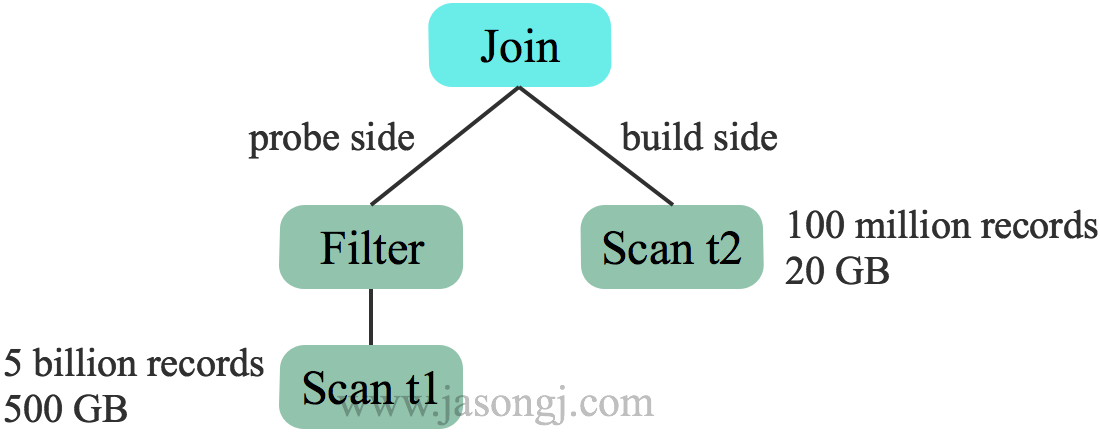
而開啟 CBO 後,基於估計的代價選擇 t1 作為 build side。更適合本例
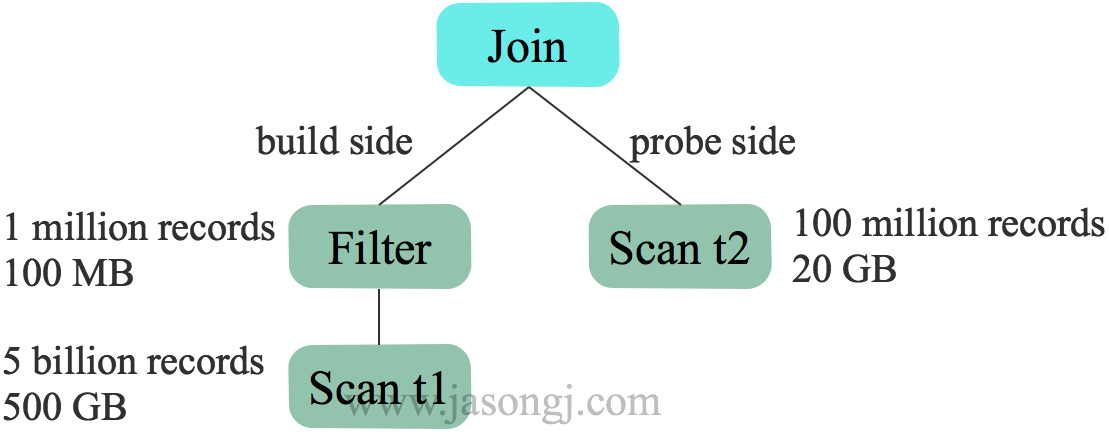
優化 Join 型別
在 Spark SQL 中,Join 可分為 Shuffle based Join 和 BroadcastJoin。Shuffle based Join 需要引入 Shuffle,代價相對較高。BroadcastJoin 無須 Join,但要求至少有一張表足夠小,能通過 Spark 的 Broadcast 機制廣播到每個 Executor 中。
在不開啟 CBO 中,Spark SQL 通過 spark.sql.autoBroadcastJoinThreshold 判斷是否啟用 BroadcastJoin。其預設值為 10485760 即 10 MB。
並且該判斷基於參與 Join 的表的原始大小。
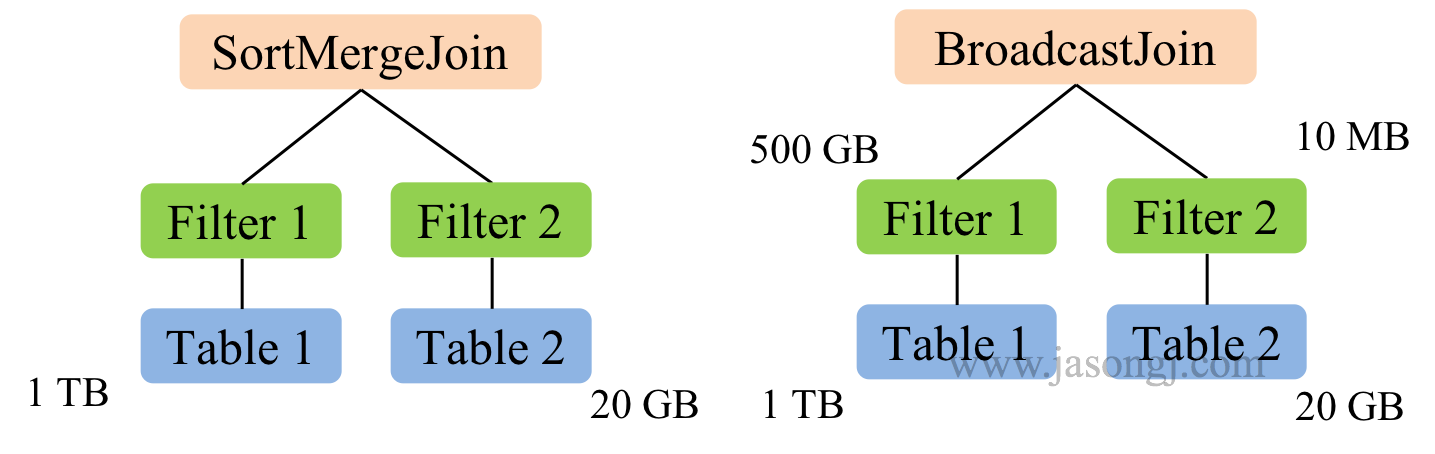
在下圖示例中,Table 1 大小為 1 TB,Table 2 大小為 20 GB,因此在對二者進行 join 時,由於二者都遠大於自動 BroatcastJoin 的閾值,因此 Spark SQL 在未開啟 CBO 時選用 SortMergeJoin 對二者進行 Join。
而開啟 CBO 後,由於 Table 1 經過 Filter 1 後結果集大小為 500 GB,Table 2 經過 Filter 2 後結果集大小為 10 MB 低於自動 BroatcastJoin 閾值,因此 Spark SQL 選用 BroadcastJoin。
優化多表 Join 順序
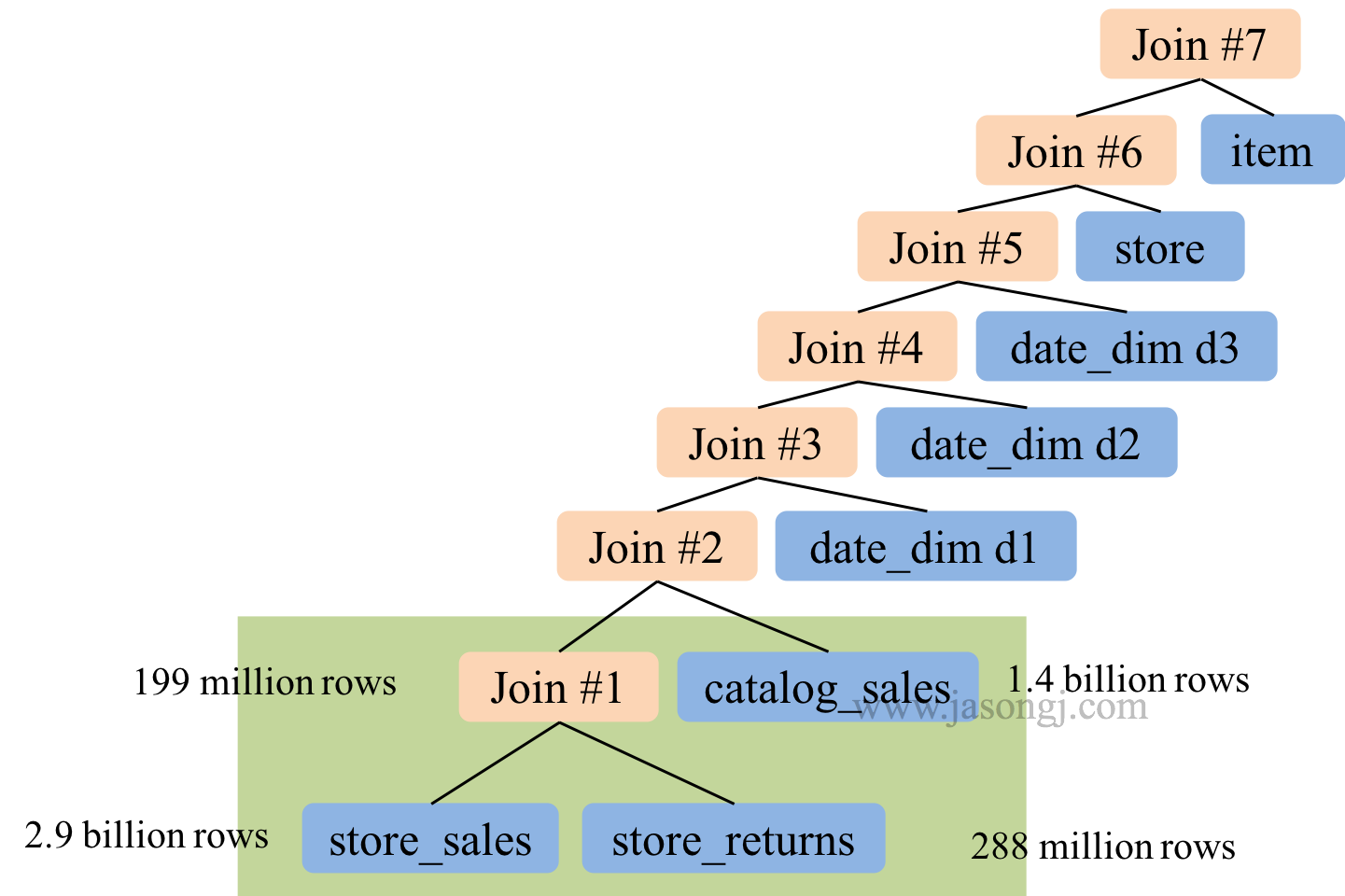
未開啟 CBO 時,Spark SQL 按 SQL 中 join 順序進行 Join。極端情況下,整個 Join 可能是 left-deep tree。在下圖所示 TPC-DS Q25 中,多路 Join 存在如下問題,因此耗時 241 秒。
- left-deep tree,因此所有後續 Join 都依賴於前面的 Join 結果,各 Join 間無法並行進行
- 前面的兩次 Join 輸入輸出資料量均非常大,屬於大 Join,執行時間較長
開啟 CBO 後, Spark SQL 將執行計劃優化如下
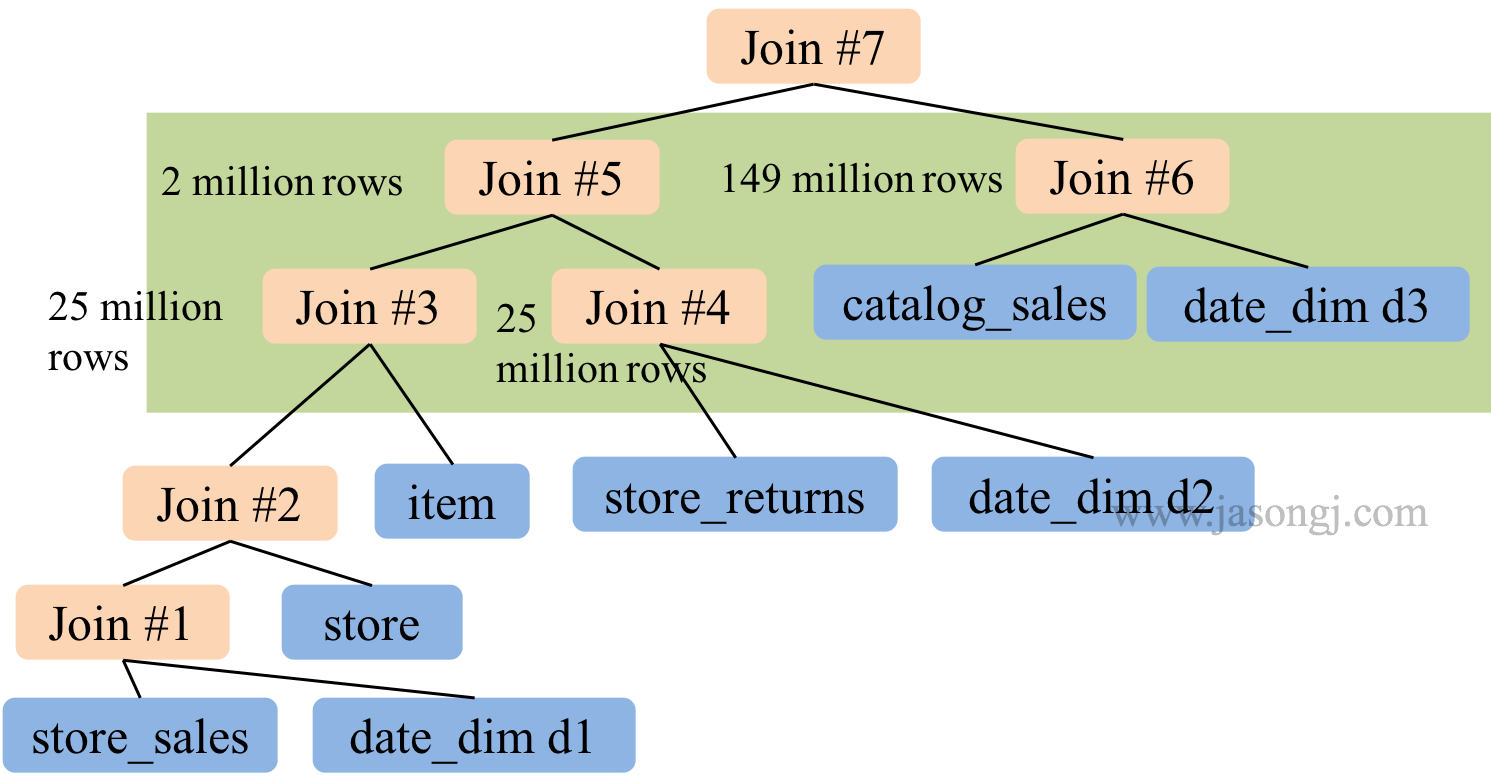
優化後的 Join 有如下優勢,因此執行時間降至 71 秒
- Join 樹不再是 left-deep tree,因此 Join 3 與 Join 4 可並行進行,Join 5 與 Join 6 可並行進行
- 最大的 Join 5 輸出資料只有兩百萬條結果,Join 6 有 1.49 億條結果,Join 7相當於小 Join