Python使用jieba分詞並用weka進行文字分類
阿新 • • 發佈:2018-12-29
一、安裝pycharm
二、安裝Python
三、在Python下安裝pip,如下圖所示,pip安裝成功
四、在python下安裝jieba:

如下圖所示,jieba安裝成功:
五、在pycharm中新建Python專案,對test.txt檔案中的中文進行分詞,並寫入testResult.txt檔案中,具體程式碼如下:
#!/usr/bin/env Python
# coding=utf-8
import jieba.analyse
import jieba
import jieba.posseg as pseg
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" 其中在結巴自定義的詞典中加入一些新詞,並使用自定義停詞表去掉無用的詞
六、將testResult.txt檔案轉成weka可匯入的.arff檔案格式(testResult檔案裡的前八個字元作為資料夾名,後幾個字元作為該資料夾下的檔案內容寫入),具體程式碼如下:
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
path = "e:\\data\\"
def mkdir(dict,content,i):
import os
mkpath = path + dict + "\\"
mkpath = mkpath.strip()
mkpath = mkpath.rstrip("\\")
isExists = os.path.exists(mkpath)
# print mkpath
if not isExists:
# print mkpath
os.makedirs(mkpath)
else:
pass
newfilepath = mkpath + "\\" + dict + str(i) + ".txt"
newfile = open(newfilepath.rstrip("\\"), "w+")
newfile.write(content)
newfile.close()
filedict = open('testResult.txt','r')
i = 0
for dictline in filedict.readlines():
dictline = dictline.strip().lstrip().lstrip(",")
dict = dictline[0:5]
content = dictline[8:len(dictline)]
i = i+1
mkdir(dict,content,i)
filedict.close()testResult.txt檔案內容格式如下:

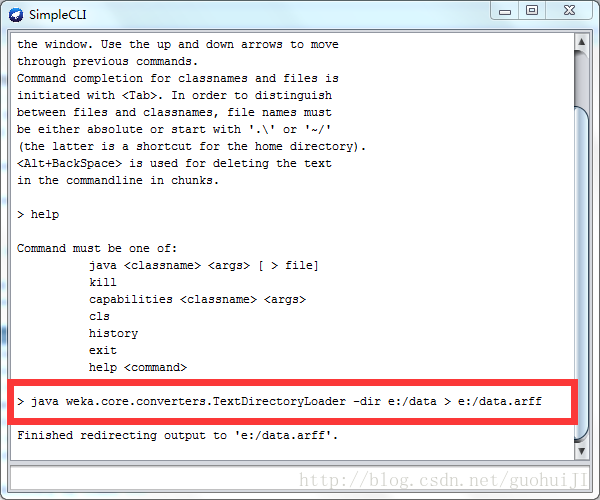
七、在weka的SimpleCLI中執行命令:
java weka.core.converters.TextDirectoryLoader -dir e:/data > e:/data.arff如下圖所示:
即可在相應的路徑下看到生成的.arff檔案:

八、在weka主介面中開啟Explorer,點選“Open file”開啟之前生成的data.arff檔案,在Filter中點選”Choose”選擇:
weka->filters->unsupervised->attribute->StringToWordVetor,然後點選應用
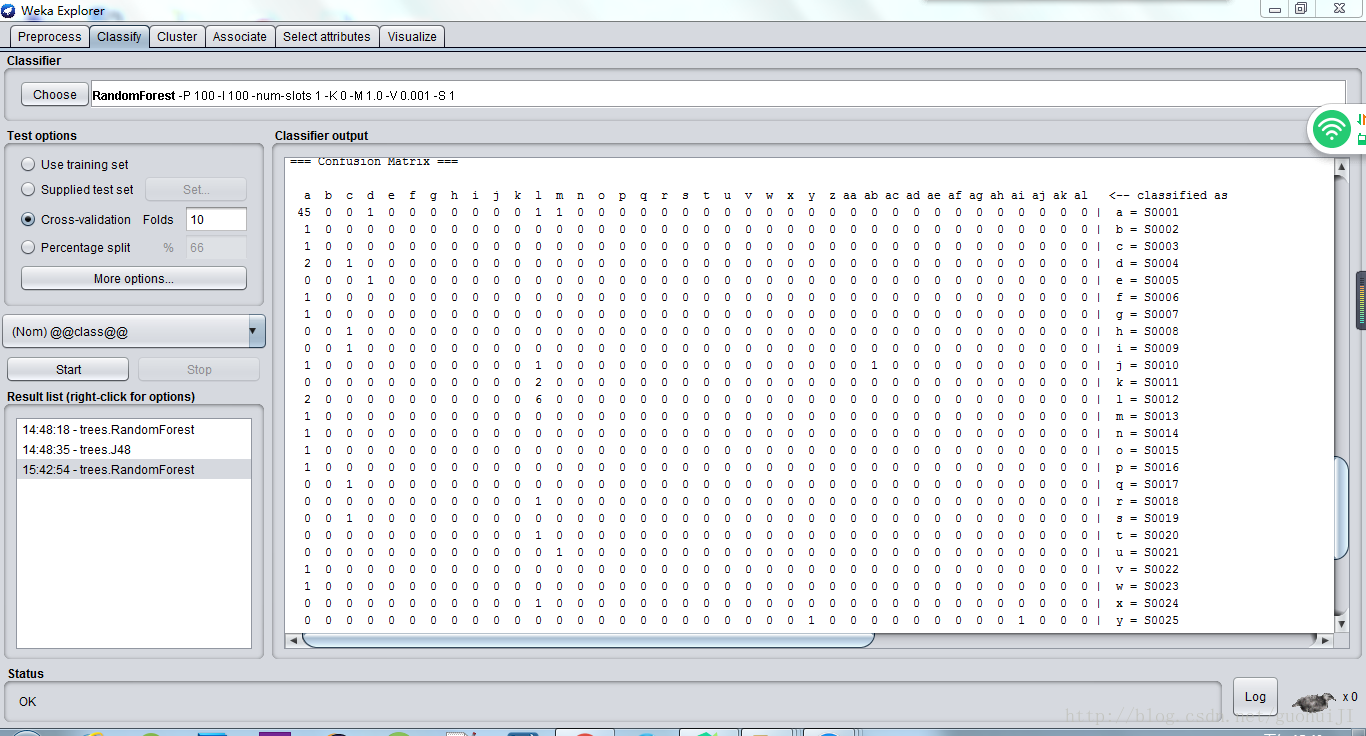
在分類Classify標籤頁中選擇J48演算法或隨機森林演算法,點選start開始分類,如下圖所示: