
NLP-使用CNN進行文字分類
- CNN最初用於處理影象問題,但是在自然語言處理中,使用CNN進行文字分類也可以取得不錯的效果。
- 在文字中,每個詞都可以用一個行向量表示,一句話就可以用一個矩陣來表示,那麼處理文字就與處理影象是類似的了。
目錄
一、卷積神經網路CNN
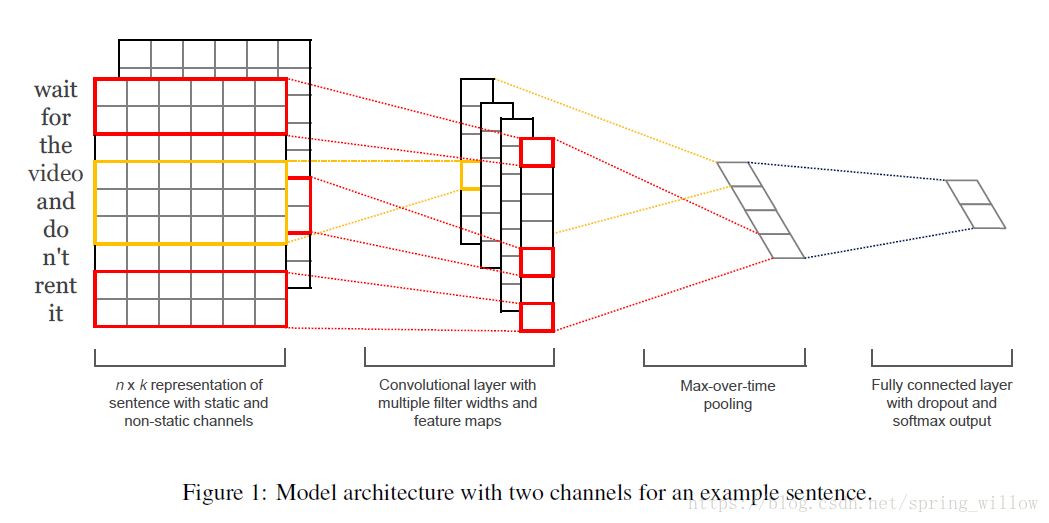
圖片來源:Convolutional Neural Networks for Sentence Classification
1.模型說明
- 在影象處理中使用不同的濾鏡可以使影象凸顯出不同的特徵,我們把新的影象稱為卷積後的特徵圖(第二層)。
- 將特徵圖通過pooling層(第三層),這與人眼在看東西的時候會首先看到耀眼的內容一樣,通常選取最大值或使用平均值來得到更小的特徵圖,這有助於計算。
- 加上任意分類器,如SVM,LSTM等。
2.卷積核
- 上述所說的濾鏡(filter)就是我們的CNN模型中的卷積核,通過使用卷積核可以將我們的原始矩陣(CNN的第一層)變成CNN的第二層。
- 卷積核是通過學習得到的,不能人工設定,這是很重要的一點,而剛開始的時候卷積核的設定是隨機的。
3.CNN4Text
上述模型中是將每個單詞作為一個特徵向量,使用了二維和三維的卷積核進行Filter,我們也可以使用一整個句子作為特徵向量,用一維的Filter進行掃描(1xN),如下圖所示:
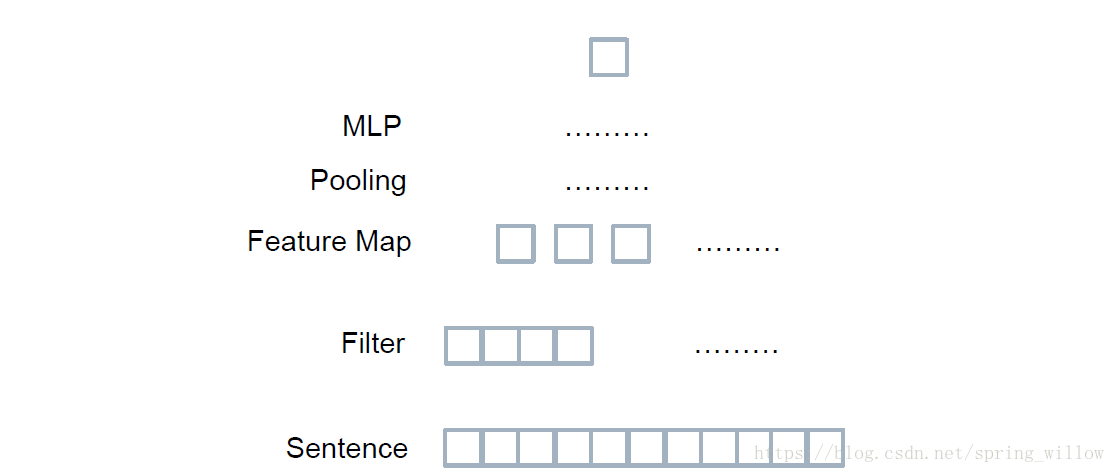
圖片來源:七月線上視訊課件(包括下圖,原始來源我母雞的了)
4.兩種引數調整問題
- 邊界處理:Narrow 和Wide
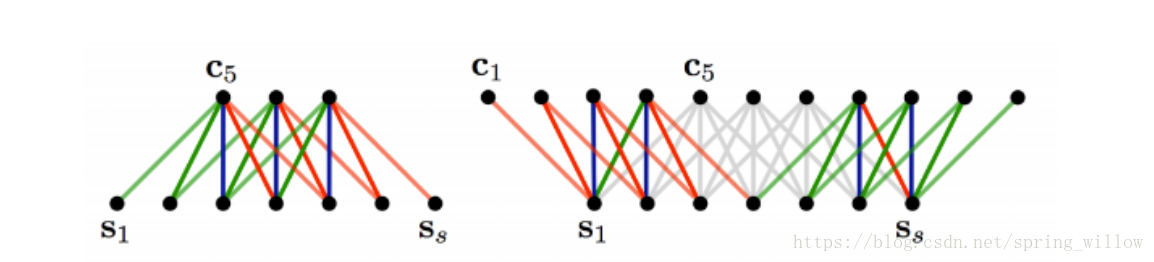
- Stride size:步伐大小
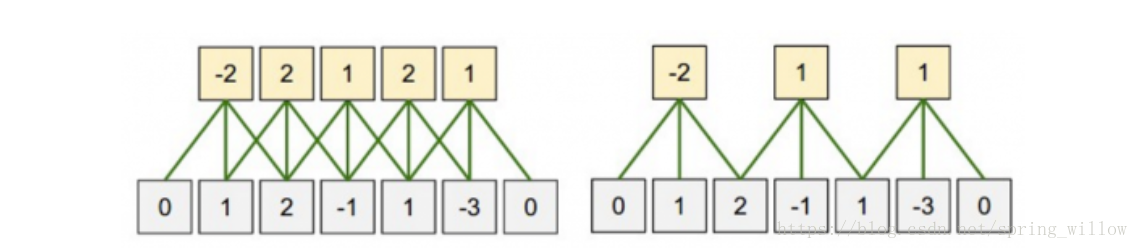
二、使用例項:word2vec+CNN進行文字分類
1.題目
用每日新聞預測金融市場變化
題目來源:Kaggle競賽
程式碼作者:加號
2.資料說明
- Combined_News_DJIA.csv: 作者將資料combine成27列,第一列是日期,第二列是標籤,其他25列是每日的前25條新聞,通過熱門程度進行排序得來。
- 這是一個二分類問題,‘1’表示這一天的股票值上升或保持不變;‘0’表示下降。
- 訓練集和測試集的比例是8:2
3.資料預處理
①匯入所需要的庫
import pandas as pd
import ②讀入資料
data = pd.read_csv('./Combined_News_DJIA.csv')
可以通過data.head()檢視資料的長相
③分割資料集
train = data[data['Date'] < '2015-01-01']
test = data[data['Date'] > '2014-12-31']④處理資料集
X_train = train[train.columns[2:]]
#去掉日期和標籤,把每條新聞做成單獨的句子,集合在一起
corpus = X_train.values.flatten().astype(str)
#獲取語料庫
X_train = X_train.values.astype(str)
X_train = np.array([' '.join(x) for x in X_train])
X_test = test[test.columns[2:]]
X_test = X_test.values.astype(str)
X_test = np.array([' '.join(x) for x in X_test])
y_train = train['Label'].values
y_test = test['Label'].values- 通過.columns[]獲取特定列;
- flatten()函式將一個巢狀多層的陣列array轉化成只有一層的陣列;
numpy array儲存單一資料型別的多維陣列;
說明:
corpus是全部我們『可見』的文字資料。假設每條新聞就是一句話,把他們全部flatten()就會得到list of sentences。
X_train和X_test不能隨便flatten,他們需要與y_train和y_test對應。
⑤分詞
from nltk.tokenize import word_tokenize
corpus = [word_tokenize(x) for x in corpus]
X_train = [word_tokenize(x) for x in X_train]
X_test = [word_tokenize(x) for x in X_test]- corpus的分詞結果裡,第二維資料是一個個的句子,而X_train的第二維資料是一天中整個新聞的合集,對應每個label。
- 可以通過X_train[:2]和corpus[:2]檢視資料的變化情況。
⑥預處理
- 小寫化
- 刪除停止詞
- 刪除數字和符號
lemma詞性還原
把這些步驟統一合成一個func
# 停止詞
from nltk.corpus import stopwords
stop = stopwords.words('english')
# 數字
import re
def hasNumbers(inputString):
return bool(re.search(r'\d', inputString))
# 正則表示式,出現數字的時候返回true
# 特殊符號
def isSymbol(inputString):
return bool(re.match(r'[^\w]', inputString))
"""
正則表示式,\w表示單詞字元[A-Za-z0-9_]
[^\w]表示取反==\W非單詞字元
全是特殊符號時返回true
"""
# lemma
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
def check(word):
"""
如果需要這個單詞,則True
如果應該去除,則False
"""
word= word.lower()
if word in stop:
return False
elif hasNumbers(word) or isSymbol(word):
return False
else:
return True
# 把上面的方法綜合起來
def preprocessing(sen):
res = []
for word in sen:
if check(word):
# 這一段的用處僅僅是去除python裡面byte存str時候留下的標識。。之前資料沒處理好,其他case裡不會有這個情況
word = word.lower().replace("b'", '').replace('b"', '').replace('"', '').replace("'", '')
res.append(wordnet_lemmatizer.lemmatize(word))
return res把三組資料集通過上面的函式進行預處理:
corpus = [preprocessing(x) for x in corpus]
X_train = [preprocessing(x) for x in X_train]
X_test = [preprocessing(x) for x in X_test]4.訓練NLP模型
使用最簡單的word2vec
from gensim.models.word2vec import Word2Vec
model = Word2Vec(corpus, size=128, window=5, min_count=5, workers=4)Word2Vec:word to vector ,將單詞轉化為向量,這時候每個單詞都可以像查字典一樣讀取座標。
例如,使用model['white']就可以獲得單詞‘white’的w2v座標。
5.使用CNN
①獲取矩陣資訊
- 用vector表示出一個大matrix,使用CNN做‘降維+注意力’
- 通過調大引數可以增加複雜度和準確度
- 確定padding size,使生成的matrix是一樣的size
- 下面程式碼可以直接呼叫keras的sequence方法
# 說明,對於每天的新聞,我們會考慮前256個單詞。不夠的我們用[000000]補上
# vec_size 指的是我們本身vector的size
def transform_to_matrix(x, padding_size=256, vec_size=128):
res = []
for sen in x:
matrix = []
for i in range(padding_size):
try:
matrix.append(model[sen[i]].tolist())
except:
# 這裡有兩種except情況,
# 1. 這個單詞找不到
# 2. sen沒那麼長
# 不管哪種情況,我們直接貼上全是0的vec
matrix.append([0] * vec_size)
res.append(matrix)
return res處理訓練集/測試集
X_train = transform_to_matrix(X_train)
X_test = transform_to_matrix(X_test)
# print(X_train[1])
# 檢視資料的長相
最後,我們得到的就是一個大大的Matrix,它的size是 128 * 256。每一個matrix對應一個數據點(標籤)。
②reshape輸入集
在進行下一步之前,需要將input 資料reshape一下,原因是要使每一個matrix的外部包裹一層維度,來告訴我們的CNN model,每個資料點都是獨立的,沒有前後關係。
(對於股票來說,存在前後關係,可以使用CNN+LSTM模型實現記憶功能)
# 搞成np的陣列,便於處理
X_train = np.array(X_train)
X_test = np.array(X_test)
# 看看陣列的大小
print(X_train.shape)
print(X_test.shape)結果:
(1611, 256, 128)
(378, 256, 128)
X_train = X_train.reshape(X_train.shape[0], 1, X_train.shape[1], X_train.shape[2])
X_test = X_test.reshape(X_test.shape[0], 1, X_test.shape[1], X_test.shape[2])
#通過print(X_test)觀察與前者的區別,就是多了一個括號
print(X_train.shape)
print(X_test.shape)結果:
(1611, 1, 256, 128)
(378, 1, 256, 128)
③定義CNN模型
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers.core import Dense, Dropout, Activation, Flatten
# set parameters:
batch_size = 32
n_filter = 16
filter_length = 4
nb_epoch = 5
n_pool = 2
# 新建一個sequential的模型
model = Sequential()
model.add(Convolution2D(n_filter,filter_length,filter_length,
input_shape=(1, 256, 128)))
model.add(Activation('relu'))
model.add(Convolution2D(n_filter,filter_length,filter_length))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(n_pool, n_pool)))
model.add(Dropout(0.25))
model.add(Flatten())
# 後面接上一個ANN
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('softmax'))
# compile模型
model.compile(loss='mse',
optimizer='adadelta',
metrics=['accuracy'])④獲取結果
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=nb_epoch,
verbose=0)
score = model.evaluate(X_test, y_test, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])三、擴充套件
①對於CNN而言,無論input什麼內容,只要符合規矩,都可以process,所以可以不使用word2vec。甚至可以使用ASCII碼(0,256)來表達每個位置上的字元,然後組成一個大大的matrix。每個字元都可以被表示出來,而且使有意義的。
②分類器的使用也是多種多樣的,可以用LSTM或者RNN等接在CNN的那句Flatten語句後,來提高預測結果。