
視覺化MNIST:關於降維的探討(1)
眾所周知,我們人類在二維和三維上能夠理性的進行思考,通過努力,我們可以從第四維來思考。但是機器學習經常要求我們使用成千上萬個維度——或者數萬,或者數百萬!即使是非常簡單的事情,當你在非常高的維度上做的時候,也會變得難以理解。
這時,就需要一些工具的輔助。高手已經建立了工具來幫助我們。有一個完整的、發展良好的領域,稱為降維,它實現了將高維資料轉換成低維資料的技術。關於高維資料視覺化的相關課題也做了大量工作。
這些技術就是我們需要的基本構建塊,特別是如果我們希望進行視覺化機器學習和深入學習。
通過視覺化和更直接地觀察實際發生的事情,我們可以更深入、更直接地理解神經網路。
因此,我們的首要任務是熟悉降維。要做到這一點,我們需要一個數據集來測試這些技術。
1. MNIST
MNIST是一種簡單的計算機視覺資料集。它由28×28畫素的手寫數字影象組成,如:

每一個MNIST資料點,每一個影象,都可以被看作是一個數字陣列,將每一個畫素填充為黑色,如
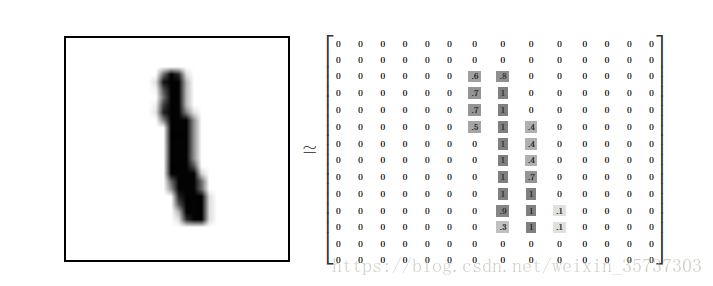
由於每個影象都有28×28個畫素,所以我們得到了一個28×28的陣列。我們可以將每個陣列變為28×28=784維向量。向量的每個分量是介於0和1之間的值,描述畫素的強度。因此,我們通常認為MNIST是784維向量的集合。
並不是所有784維空間中的所有向量都是MNIST資料。這個空間的典型點是非常不同的!為了對一個典型點有點感覺,我們可以隨機挑選幾個點,並檢查它們。在一個隨機點上(就是隨機的28×28影象)每個畫素是隨機的黑色,白色或一些灰色的陰影。

像MNIST資料這樣的影象是非常罕見的。當MNIST資料點嵌入到784維空間中時,它們位於非常小的子空間中。通過一些稍微困難的引數,我們可以看到它們佔據了更低維子空間。
人們對地位結果MNIST和相似的資料有很多理論,其中對受歡迎的就是機器學習中的歧義假設(manifold hypothesis):MNIST是一個低微多形(low dimensional manifold),通過其高維嵌入空間來掃描和彎曲。
與拓撲資料分析更相關的另一個假設是,像MNIST這樣的資料是由具有突起狀小突塊突出到周圍空間中構成的.
2 立方形MNIST
我們可以把MNIST資料點看作是懸浮在784維立方體中的點。立方體的每個維度對應於特定畫素。資料點根據畫素強度從0到1不等。在維度的一側,有影象,其中畫素是白色的。在維度的另一邊,有一些影象是黑色的。在兩者之間,有灰色的影象。

如果我們這樣想,自然會出現問題。如果我們看一個特定的二維面,立方體會是什麼樣子?就像看雪球一樣,我們看到資料點投射到兩個維度,一個維度對應於一個特定畫素的強度,另一個對應於第二畫素的強度。檢查這個使得我們以非常原始的方式探索MNIST。
在下面這個視覺化中,每個點是一個MNIST資料點。點是根據資料點屬於哪一類數字來著色的。當滑鼠停留在一個點上時,該資料點的影象顯示在每個軸上。每個軸對應於特定畫素的強度,當標記和視覺化後,在小影象旁邊最為一個藍色的點。通過點選影象,可以更改哪個畫素顯示在該軸上。

從上面我們可以看出MNIST的一些結構,注意到畫素點P18,15和P7,12,我們能夠分離很多零點到右下角和許多9到左上角。畫素P點5、6和P7、9,我們可以看到很多的2在右上角和很多3在右下角。


另一種樣式的9:

現在面臨的困難是我們需要選擇我們使用的角度,有一個叫做Principal Components Analysis (PCA)–主成分分析–的技術能為我們找到最好的角度,也就是說PCA會發現最大的點(捕捉儘可能多的變化)的角度。
但是,從一個角度看784維立方體是什麼意思呢?我們需要決定立方體的每一個軸的傾斜方向:一個方向,另一個方向,或者介於兩者之間的某個方向。
具體地說,下面是PCA選擇的兩個角度的圖片。紅色代表畫素向一側傾斜,藍色向另一側傾斜。

如果一個MNIST數字主要突出為紅色,它就傾向一端。如果它突出主要為藍色,它就傾向另一端。第一角度(就是”第一主要成分”)就是我們的水平角度。將1(突出大量紅色少量藍色)放到左邊,將0(突出大量藍色少量紅色)放到右邊。

現在我們知道了最好的水平和垂直角度,我們可以嘗試從這個角度來看待立方體。
下面這個視覺化很像上面的一個,但是現在軸被固定來顯示第一個和第二個“主要成分”,是觀察資料的基本角度。在每個軸上的影象中,藍色和紅色被用來表示那個畫素的傾斜。藍色區域中的畫素強度將資料點推到一邊,紅色區域中的畫素強度將我們推向另一個區域。


雖然比前面一個視覺化操作好多了,但仍不客觀。不幸的是,即使從最好的角度看資料,MNIST的資料也不能很好地反映我們的觀點。這是一個非平凡的高維結構,而這些線性投影只是無法切割它。值得慶幸的是,我們有一些強大的工具來處理不合作的資料集。
3. 基於優化的降維
如果我們的視覺化中的點之間的距離與原始空間中的點之間的距離相同,那就非常完美了。如果能做到這一步,我們將捕獲資料的全域性幾何結構。
詳細說就是,對於任意兩個MNIST資料點,Xi和Yi,它們之間有兩種距離的概念。一個是它們在原始空間中的距離,一個是它們在視覺上的距離。
我們有許多選項來定義這些高維向量之間的距離。對於這個帖子,我們將使用L2距離:
這裡使用

現在就可以有下面這個定義了:

這個值描述了視覺化的壞程度,它傳達的資訊就是:兩個距離不相同不是一件好事,這種程度的壞而且還是平方級別的。如果這個值很大,意味著距離與原來的空間不一樣如果它很小,就意味著它們是相似的;如果它是零,我們就有一個“完美”的嵌入。
這聽起來像是一個優化問題!深度學習者知道如何處理這些!我們選擇一個隨機起點,並應用梯度下降。
我們通過在原點周圍取樣高斯來初始化點的位置。我們的優化過程不是標準梯度下降。相反,我們使用動量梯度下降的變體。 在向動量新增梯度之前,我們將梯度歸一化。這減少了對超引數調諧的需要。
在原始文件中有一些視覺化的圖例,CSDN載入不出來,可以自行前往檢視,對於這裡所提到的視覺化,通過滑鼠可對其進行縮放


這種技術被稱為多維縮放(或MDS)。首先,我們隨機地將每個點定位在平面上。接下來,我們將每一對點與一個具有原始距離長度