
【機器學習】關於t-sne:降維、視覺化
阿新 • • 發佈:2019-01-22
關於t-sne:降維、視覺化
機器學習中,我們的使用的資料基本都是高維的,所以我們很難直接從資料中觀察分佈和特徵。因此出現了很多資料降維的手段幫助我們提取特徵和視覺化資料。這就是流行學習方法(Manifold Learning):假設資料是均勻取樣於一個高維歐氏空間中的低維流形,流形學習就是從高維取樣資料中恢復低維流形結構,即找到高維空間中的低維流形,並求出相應的嵌入對映,以實現維數約簡或者資料視覺化。它是從觀測到的現象中去尋找事物的本質,找到產生資料的內在規律。
有張圖可以比較好的理解下降維的方法。
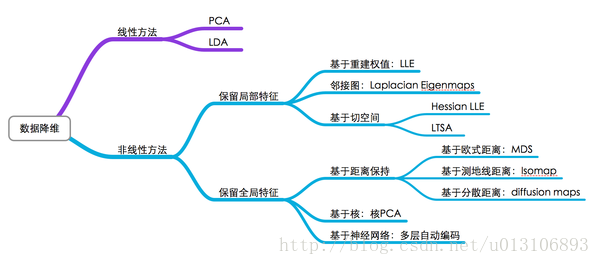
PCA曾經廣泛用於提取特徵,由於其是線性降維,所以不能解釋特徵之間的複雜多項式關係,而且也已經過於古老。而上圖中沒有提及的t-sne屬於非線性方法,是由Hinton和lvdmaaten在2008年提出的。關於降維的資料作為feature是否更優還不能確定,但是其視覺化效果非常好。由於t-sne執行速度非常慢,比pca高了一個數量級,因此在視覺化資料的時候一般先用pca處理,然後再用tsne處理。
t-sne是由sne發展而來,SNE是通過仿射(affinitie)變換將資料點對映到概率分佈上,主要包括兩個步驟:
- SNE構建一個高維物件之間的概率分佈,使得相似的物件有更高的概率被選擇,而不相似的物件有較低的概率被選擇。
- SNE在低維空間裡在構建這些點的概率分佈,使得這兩個概率分佈之間儘可能的相似
儘管SNE提供了很好的視覺化方法,但是他很難優化,而且存在”crowding problem”(擁擠問題)。後續中,Hinton等人又提出了t-SNE的方法。與SNE不同,主要如下:
- 使用對稱版的SNE,簡化梯度公式
- 低維空間下,使用t分佈替代高斯分佈表達兩點之間的相似度
優化mnist過程的動態圖如下:
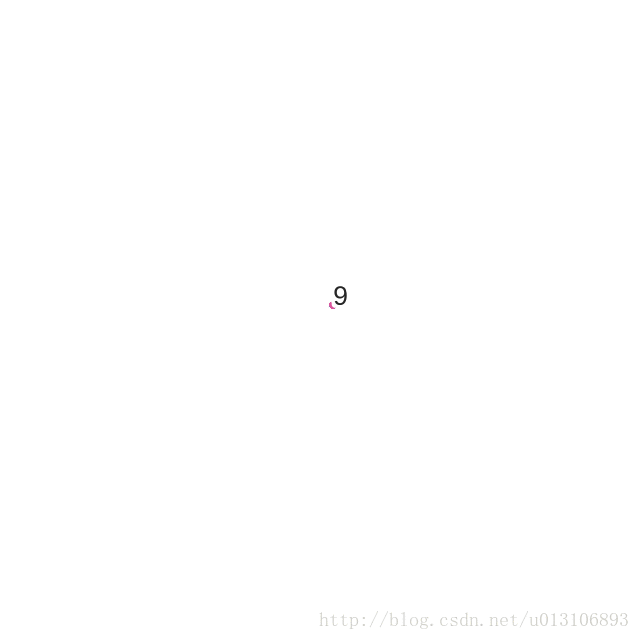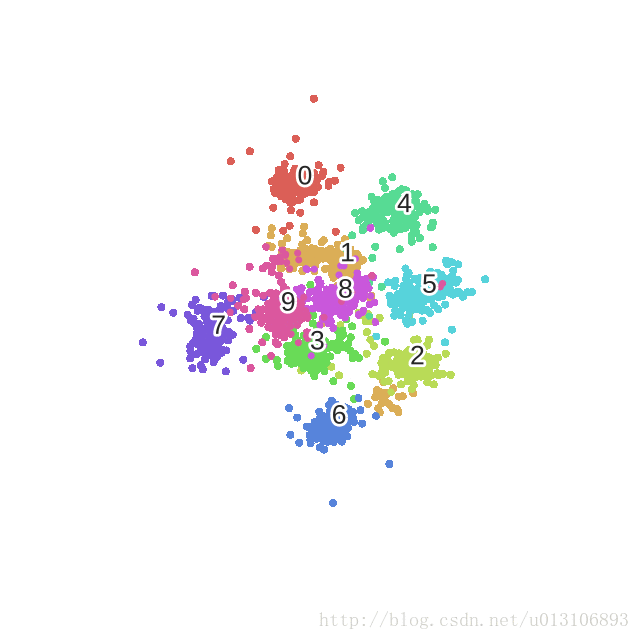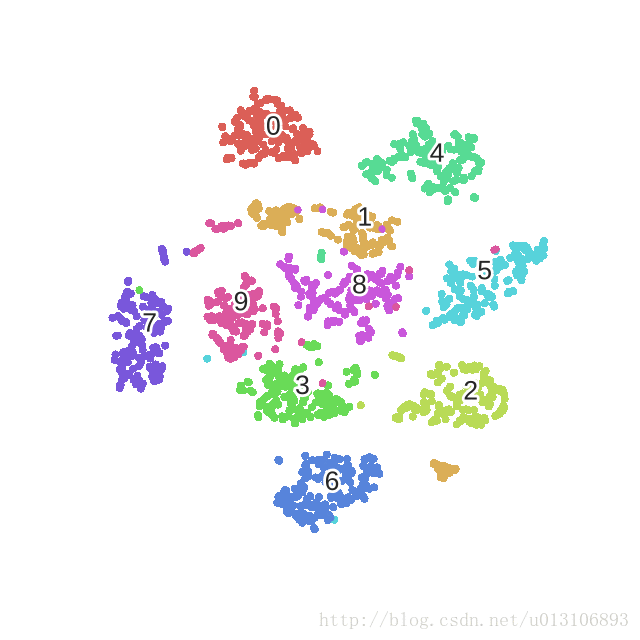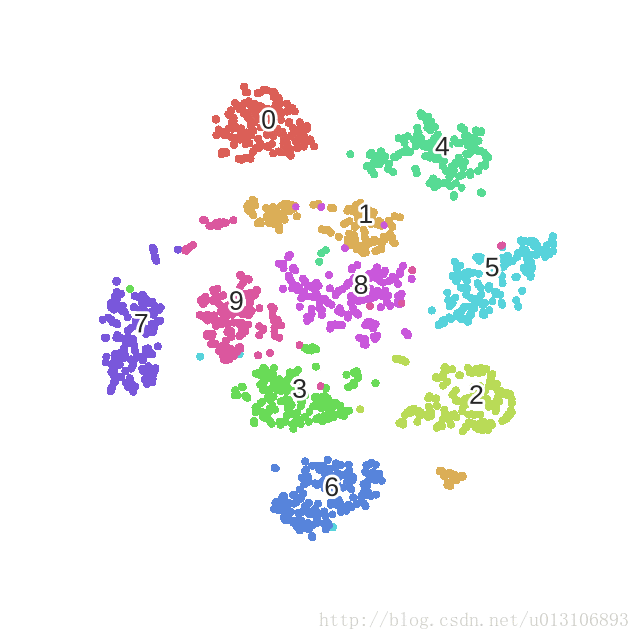
我們可以使用python得sklearn包來體驗一下tsne,非常簡單。
#import 相關的包和mnist資料集
import numpy as np
import matplotlib.pyplot as plt
from time import time
from sklearn import datasets, manifold
#定義函式將結果plot出來
def plot_embedding(X, title=None):
x_min, x_max = np.min(X, 0), np.max(X, 0