
人工智慧入門1.交叉熵 - loss函式在Tensorflow中的定義
1.交叉熵
要懂得交叉熵,先要懂得資訊量
資訊量的定義
夏農(C. E. Shannon)資訊理論應用概率來描述不確定性。資訊是用不確定性的量度定義的.一個訊息的可能性愈小,其資訊愈多;而訊息的可能性愈大,則其資訊愈少.事件出現的概率小,不確定性越多,資訊量就大,反之則少。
其中
![]()
標識x0 事件出現的概率。
通俗的講,資訊量,就是某個事件能給你帶來多大的震撼,越震撼資訊量就越大。我們來舉個例子
拋硬幣是人們經常用來舉例的,假設
x1 表示硬幣正面 x2表示硬幣反面,另外x3表示硬幣豎起來。(x3事件我們現在只是用來舉例不必深究)
則這個三者的概率(p)
p(x1) 0.49995
p(x2) 0.49995
p(x3) 0.0001
則這個三個事件能帶給我們的資訊量(I)是多少呢?
I(x1) = -log(0.49995) = 1.000144277
I(x2) = -log(0.49995) = 1.000144277
I(x3) = -log(0.0001) = 13.28771238
這邊的log是
所以你拋一枚硬幣,如果它立起來了,你會說臥槽---表示資訊量很大。 實際上x3 的概率還會更小,我這邊只是為了舉例子。
熵的定義

n表示幾個可能的概率事件。
這個熵,怎麼理解能,我們如果不求和,單個的看就是概率和資訊量的乘積。把所有的事件的這個乘積加起來就是熵。
定義是這樣定義的,但是怎麼理解,就看個人的理解了。
我們計算下上面拋硬幣的熵:
0.49995*1.000144277 + 0.49995*1.000144277 + 0.0001*13.28771238 = 1.001373034
相對熵的定義
再提出相對熵之前我們先講一個出老千的例子:比如還是上述拋硬幣,我和另外一個同學A再用這個拋硬幣來賭博,如果正面朝上我贏,如果反面朝上同學A贏,如果立起來誰也不算贏。但是啊,上面我們算過了p(x1) 的概率 是0.49995 ,但是有一天,同學A出老千,使用磁鐵等不正規手段,把p(x1) 正面的概率降低到了0.33333以下,我們記q(x1) = 0.33333 導致我輸了很多錢。
那麼,這邊x1 正面朝上的概率,相對兩個場景就有了兩個不同的概率分佈。我們如何去描述這兩個場景資訊差異。就是用相對熵。

我們看相對熵D,如果p 場景下的概率和q場景下的概率都是一樣的,意思是q場景下我的同學沒有出老千,那麼p和q的比例就是1。那麼
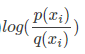
就等於0,那麼相對熵就是為零。就是表示這兩個場景的資訊沒有差異。
將D進行變換一下,
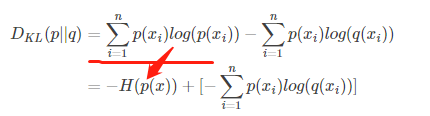
那麼好了,由於p場景下x事件是恆定已知的,因為沒有人做手腳。所有H函式是確定的,不確定的就是後面的部分。

我們定義H(p,q)叫做交叉熵。
2.loss函式在Tensorflow中的定義
loss = tf.reduce_mean(tf.square(y - y_))
cross = -tf.reduce_sum(y_ * tf.log(y + 1e-10))
在Tensorflow中常常有,以上兩種定義loss函式。
第一個是均方差第二個就是交叉熵。
為什麼使用交叉熵,理論上我沒有去證明,大概想一想。
在梯度求極限的情況下,使用均方差是比較好的
但是如果是資訊分類,大多反應的是各種場景的資訊量,所有估計交叉熵會好。實踐表明就是如此。
學的比較淺,有錯誤的地方歡迎批評指正。
相關文章《人工智慧入門2.線性迴歸-理解TensorFlow中wb引數的含義》
更多文章關注https://www.shennongblog.com