
elasticsearch以及其中倒排索引理解搜尋引擎
ES概念:
cluster:代表一個叢集,叢集中有多個節點,其中有一個為主節點,這個主節點是可以通過選舉產生的,主從節點是對於叢集內部來說的。es的一個概念就是去中心化,字面上理解就是無中心節點,這是對於叢集外部來說的,因為從外部來看es叢集,在邏輯上是個整體,你與任何一個節點的通訊和與整個es叢集通訊是等價的。
shards:代表索引分片,es可以把一個完整的索引分成多個分片,這樣的好處是可以把一個大的索引拆分成多個,分佈到不同的節點上。構成分散式搜尋。分片的數量只能在索引建立前指定,並且索引建立後不能更改。
replicas:代表索引副本,es可以設定多個索引的副本,副本的作用一是提高系統的容錯性,當某個節點某個分片損壞或丟失時可以從副本中恢復。二是提高es的查詢效率,es會自動對搜尋請求進行負載均衡。
recovery:代表資料恢復或叫資料重新分佈,es在有節點加入或退出時會根據機器的負載對索引分片進行重新分配,掛掉的節點重新啟動時也會進行資料恢復。
river:代表es的一個數據源,也是其它儲存方式(如:資料庫)同步資料到es的一個方法。它是以外掛方式存在的一個es服務,通過讀取river中的資料並把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。
gateway:代表es索引快照的儲存方式,es預設是先把索引存放到記憶體中,當記憶體滿了時再持久化到本地硬碟。gateway對索引快照進行儲存,當這個es叢集關閉再重新啟動時就會從gateway中讀取索引備份資料。es支援多種型別的gateway,有本地檔案系統(預設),分散式檔案系統,Hadoop的HDFS和amazon的s3雲端儲存服務。
discovery.zen:代表es的自動發現節點機制,es是一個基於p2p的系統,它先通過廣播尋找存在的節點,再通過多播協議來進行節點之間的通訊,同時也支援點對點的互動。
Transport:代表es內部節點或叢集與客戶端的互動方式,預設內部是使用tcp協議進行互動,同時它支援http協議(json格式)、thrift、servlet、memcached、zeroMQ等的傳輸協議(通過外掛方式整合)。
倒排索引的介紹:
倒排索引實際上由於應用中需要根據屬性值來查詢記錄,這種索引表中的每一項都包含一個屬性值和具有該屬性值的各記錄的地址。
由於不是由記錄來確定屬性值,而是由屬性值來確定記錄的位置,因而稱之為倒排索引(inverted index),帶有倒排索引的檔案稱之為倒排
索引檔案,簡稱倒排檔案。
比如說我們接下來要搜尋下面的這句話:
“python寫各大聊天系統的遮蔽髒話功能原理”
於是根據搜尋引擎給關鍵詞進行分詞的操作,於是便可以得到下面的查詢統計記錄結果:

關鍵詞代表的是 搜尋引擎 給句子分出來的詞,下面的文章代表搜尋引擎具體在哪篇文章中搜索出來的資料
我們還可以把這個搜尋出的結果更加的細化,變成更加具體的定位
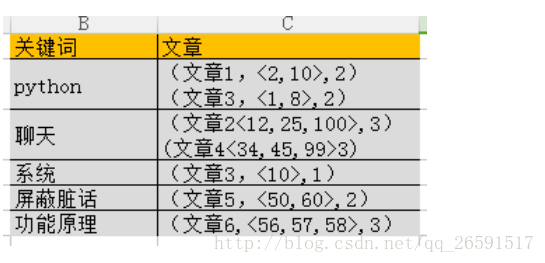
第二列文章中代表的含義分別是( 該關鍵詞所在的文章 ,<該關鍵詞在文章出出現的索引位置> ,該關鍵詞出現的次數 )
這樣以來搜尋引擎就可以根據把句子進行分詞,然後根據對分詞的查詢在文章中的位置將其按照某種方法進行排序操作,完成搜尋引擎的排序功能。
倒排索引還需要亟待解決的問題:
1、大小寫轉化的問題,如python和PYTHON應該為一個詞
2、詞幹抽取的問題,比如 look 和 looking 這兩個詞結果都處理成了look
3、分詞,“遮蔽系統”這個詞 應該是 分詞為 “遮蔽“ , “系統” 兩個詞還是 “遮蔽系統” 這樣一個詞
4、倒排索引檔案過大 — 需要壓縮排行編碼