
EM最大期望演算法與jensen不等式
介紹
em演算法是一種迭代演算法,用於含有隱變數的引數模型的最大似然估計或極大後驗概率估計。EM演算法,作為一個框架思想,它可以應用在很多領域,比如說資料聚類領域----模糊聚類的處理,待會兒也會給出一個這樣的實現例子。
EM演算法原理
EM演算法從名稱上就能看出他可以被分成2個部分,E-Step和M-Step。E-Step叫做期望化步驟,M-Step為最大化步驟。
整體演算法的步驟如下所示:
1、初始化分佈引數。
2、(E-Step)計算期望E,利用對隱藏變數的現有估計值,計算其最大似然估計值,以此實現期望化的過程。
3、(M-Step)最大化在E-步驟上的最大似然估計值來計算引數的值
4、重複2,3步驟直到收斂。
以上就是EM演算法的核心原理,也許您會想,真的這麼簡單,其實事實是我省略了其中複雜的資料推導的過程,因為如果不理解EM的演算法原理,去看其中的資料公式的推導,會讓人更加暈的。好,下面給出資料的推導過程,本人數學也不好,於是用了別人的推導過程,人家已經寫得非常詳細了。
EM演算法的推導過程
jensen不等式
在介紹推導過程的時候,需要明白jensen不等式,他是一個關於凸函式的一個定理,直接上公式定義;
如果f是凸函式,X是隨機變數,那麼

特別地,如果f是嚴格凸函式,那麼 當且僅當
當且僅當 ,也就是說X是常量。
,也就是說X是常量。
這裡我們將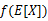 簡寫為
簡寫為 。
。
如果用圖表示會很清晰:
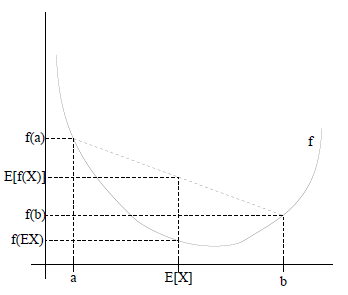
這裡需要解釋的是E(X)的值為什麼是(a+b)/2,因為有0.5 的概率是a,0.5的概率是b,於是他的期望就是a,b的和的中間值了。同理在y軸上的值也是如此。
EM演算法的公式表達形式
EM演算法轉化為公式的表達形式為:
給定的訓練樣本是 ,樣例間獨立,我們想找到每個樣例隱含的類別z,能使得p(x,z)最大。p(x,z)的最大似然估計如下:
,樣例間獨立,我們想找到每個樣例隱含的類別z,能使得p(x,z)最大。p(x,z)的最大似然估計如下:

然後對這個公式做一點變化,就可以用上jensen不等式了,神奇的一筆來了:
可以由前面闡述的內容得到下面的公式:

(1)到(2)比較直接,就是分子分母同乘以一個相等的函式。(2)到(3)利用了Jensen不等式。對於每一個樣例i,讓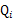 表示該樣例隱含變數z的某種分佈,
表示該樣例隱含變數z的某種分佈,![clip_image032[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616025060.png) 滿足的條件是
滿足的條件是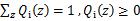 。於是就來到了問題的關鍵,通過上面的不等式,我們就可以確定式子的下界,然後我們就可以不斷的提高此下界達到逼近最後真實值的目的值,那麼什麼時候達到想到的時候呢,沒錯,就是這個不等式變成等式的時候,然後再依據之前描述的jensen不等式的說明,當不等式變為等式的時候,當且僅當,也就是說X是常量,推出就是下面的公式:
。於是就來到了問題的關鍵,通過上面的不等式,我們就可以確定式子的下界,然後我們就可以不斷的提高此下界達到逼近最後真實值的目的值,那麼什麼時候達到想到的時候呢,沒錯,就是這個不等式變成等式的時候,然後再依據之前描述的jensen不等式的說明,當不等式變為等式的時候,當且僅當,也就是說X是常量,推出就是下面的公式:

再推導下,由於 (因為Q是隨機變數z(i)的概率密度函式),則可以得到:分子的和等於c(分子分母都對所有z(i)求和:多個等式分子分母相加不變,這個認為每個樣例的兩個概率比值都是c)
(因為Q是隨機變數z(i)的概率密度函式),則可以得到:分子的和等於c(分子分母都對所有z(i)求和:多個等式分子分母相加不變,這個認為每個樣例的兩個概率比值都是c)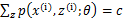 ,再次繼續推導;
,再次繼續推導;

最後就得出了EM演算法的一般過程了:
迴圈重複直到收斂
(E步)對於每一個i,計算

(M步)計算
