
Word Embedding與Word2Vec
一、數學上的“嵌入”(Embedding)
Embed這個詞,英文的釋義為, fix (an object) firmly and deeply in a surrounding mass, 也就是“嵌入”之意。例如:One of the bullets passed through Andrea's chest before embedding itself in a wall.
另外,這個詞(的分詞形式)在數學上也是一個專有名詞,Embedding,它廣泛存在於包括代數、拓撲與幾何等諸多數學領域。它主要表徵某個數學結構中的一個例項被包含在另外一個例項中,例如一個group它同時又是一個subgroup。
當我們說某個物件 X 被嵌入到另外一個物件 Y 中, 那麼 embedding 就由一個單射的、結構保持的(structure-preserving)對映 f : X → Y 來給定的。此處的結構保持的具體含義要依賴於X 和 Y 是哪種數學結構的例項而定。
舉個例子:我們可以把整數“嵌入”進有理數之中。顯然,整數是一個group,同時它又是有理數的一個subgroup。整數集合中的每個整數,在有理數集合中都能找到一個唯一的對應(其實就是它本身)。同時,整數集合中的每個整數所具有的性質,在有理數中同樣得到了保持。同理,我們也可以把有理數“嵌入”到實數中去。
二、詞嵌入(Word Embedding)
最簡單的一種Word Embedding方法,就是基於詞袋(BOW)的One-Hot表示。這種方法,把詞彙表中的詞排成一列,對於某個單詞 A,如果它出現在上述詞彙序列中的位置為 k,那麼它的向量表示就是“第 k 位為1,其他位置都為0 ”的一個向量。
例如,有語料庫如下:
John likes to watch movies. Mary likes movies too.
John also likes to watch football games.
把上述語料中的詞彙表整理出來並排序(具體的排序原則可以有很多,例如可以根據字母表順序,也可以根據出現在語料庫中的先後順序)
假設我們的詞彙表排序結果如下:
{"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also":6, "football": 7, "games": 8, "Mary": 9, "too": 10}
那麼則有如下word的向量表示:John: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]likes: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
……
此時,你也可以進一步地把文件也表示成向量。方法就是直接將各詞的詞向量表示加和,於是則有原來的兩句話的向量表示如下:
[1, 2, 1, 1, 2, 0, 0, 0, 1, 1]
[1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
One-hot方法很簡單,但是它的問題也很明顯:
1)它沒有考慮單詞之間相對位置的關係;
2)詞向量可能非常非常長!
針對第一個問題,你可能會想到n-gram方法,這確實是一個策略,但是它可能會導致計算量的急劇增長。因為n-gram已經在之前的文章中解釋過了,下面我們來看另外一個方法:共現矩陣 (Cocurrence matrix)。
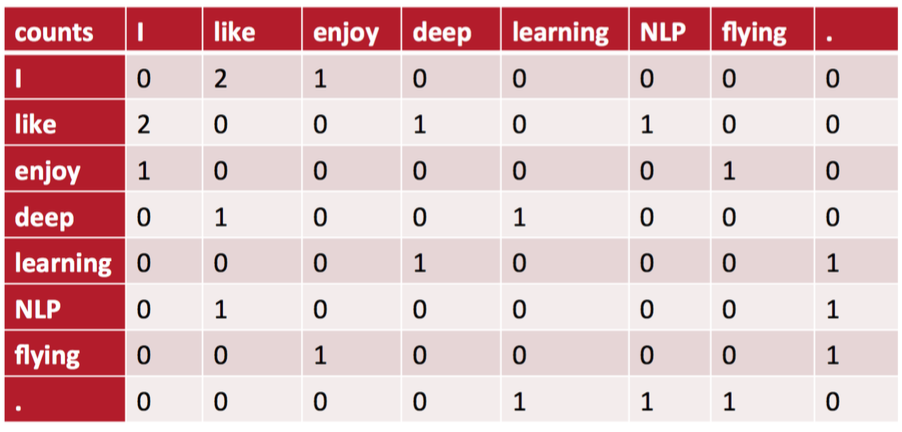
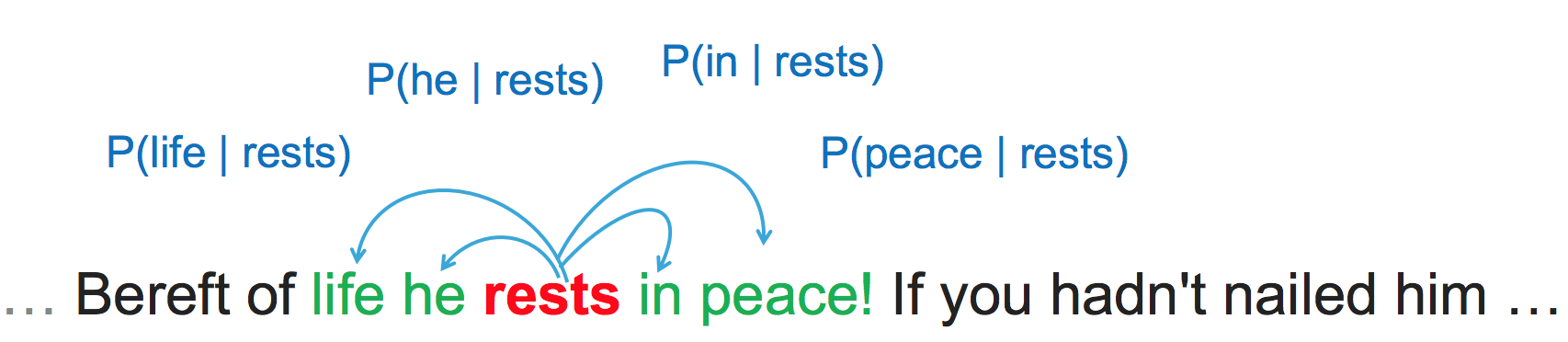
一個非常重要的思想是,我們認為某個詞的意思跟它臨近的單詞是緊密相關的。這是我們可以設定一個視窗(大小一般是5~10),如下視窗大小是2,那麼在這個視窗內,與rests 共同出現的單詞就有life、he、in、peace。然後我們就利用這種共現關係來生成詞向量。

例如,現在我們的語料庫包括下面三份文件資料:
I like deep learning.
I like NLP.
I enjoy flying.
作為示例,我們設定的視窗大小為1,也就是隻看某個單詞周圍緊鄰著的那個單詞。此時,將得到一個對稱矩陣——共現矩陣。因為在我們的語料庫中,I 和 like做為鄰居同時出現在視窗中的次數是2,所以下表中I 和like相交的位置其值就是2。這樣我們也實現了將word變成向量的設想,在共現矩陣每一行(或每一列)都是對應單詞的一個向量表示。
我們已經見識了兩種詞嵌入的方式。而現在最常用、最流行的方法,就是Word2Vec。這是Tomas Mikolov在谷歌工作時發明的一類方法,也是由谷歌開源的一個工具包的名稱。具體來說,Word2Vec中涉及到了兩種演算法,一個是CBOW一個是Skip-Gram。這也是因為深度學習流行起來之後,基於神經網路來完成的Word Embedding方法。
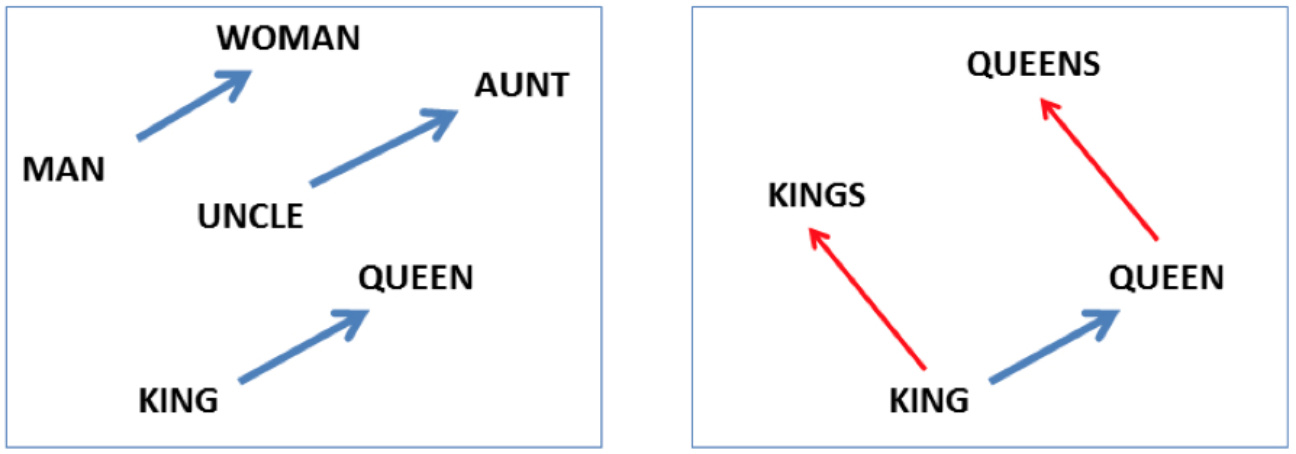
Word2Vec之所以現在這麼流行,不同於之前的一些Word Embedding方法,它能夠自動實現:1)單詞語義相似性的度量;2)詞彙的語義的類比。此處,語義的類比,反應的是類似下面這種關係:
- “國王” – “王后” ≈ “男” – “女”
- “英國” – “倫敦” ≈ “法國” – “巴黎” ≈ “首都”
對於Skip-Gram模型來說,它是要Generates each word in context given centre word。如下圖所示:
所以總概率定義為:
其中下標denotes position in running text. 對於每個單詞而言,則有
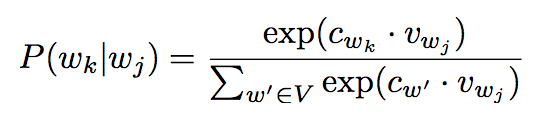
對於CBOW模型來說,Condition on context, and generate centre word。如下圖所示:

要細摳Skip-Gram和CBOW的話,恐怕還需要很長篇幅和太多細節上的討論,這一點留待後續文章中再來另行討論。下面我們將在Python中實際使用一下Word2Vec,這就要簡單許多了,因為我們可以直接使用gensim [1]。注意我們用來訓練模型的語料庫是NLTK中的Brown語料庫。實際中要獲得更高質量的模型,往往意味著需要更大的語料庫,當然這也意味著更多的訓練時間。
import gensim, logging, os
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
import nltk
corpus = nltk.corpus.brown.sents()
fname = 'brown_skipgram.model'
if os.path.exists(fname):
# load the file if it has already been trained, to save repeating the slow training step below
model = gensim.models.Word2Vec.load(fname)
else:
# can take a few minutes, grab a cuppa
model = gensim.models.Word2Vec(corpus, size=100, min_count=5, workers=2, iter=50)
model.save(fname)
words = "woman women man girl boy green blue did".split()
for w1 in words:
for w2 in words:
print(w1, w2, model.similarity(w1, w2))woman woman 1.0
woman women 0.3451595268
woman man 0.607956254336
woman girl 0.761190251497
woman boy 0.558522930154
woman green 0.24118403927
woman blue 0.178044251325
woman did 0.0751838683173
women woman 0.3451595268
women women 1.0
women man 0.126646555737
women girl 0.292825346454
women boy 0.298552943639
women green 0.104096393379
women blue 0.0930137564485
women did 0.152766770859
注意:輸出內容較長,這裡不全部列出,讀者可以執行嘗試並觀察輸出結果... ...
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
M = np.zeros((len(words), len(words)))
for i, w1 in enumerate(words):
for j, w2 in enumerate(words):
M[i,j] = model.similarity(w1, w2)
plt.imshow(M, interpolation='nearest')
plt.colorbar()
ax = plt.gca()
ax.set_xticklabels([''] + words, rotation=45)
ax.set_yticklabels([''] + words)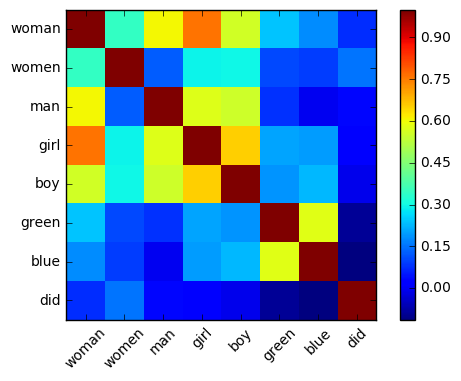
你也可以從詞彙表中提取出跟某個單詞(例如woman)最相關的k個詞:
model.most_similar(positive=['woman'], topn=10)[('girl', 0.7611901760101318),
('man', 0.6079562902450562),
('lady', 0.6069421768188477),
('boy', 0.5585228800773621),
('child', 0.5556907653808594),
('person', 0.5444432497024536),
('young', 0.5219132900238037),
('pair', 0.5211296081542969),
('she', 0.5175711512565613),
('fellow', 0.5115353465080261)]現在你也可以試著來玩一下Word2Vec啦!
參考:[1] https://radimrehurek.com/gensim/(本文完)