
Object Detection.... (更新中....)
Cascade R-CNN: Delving into High Quality Object Detection:
亮點:設定不同的 IoU 閾值,bbox reg 的級聯。
positive(pos) negative(neg)

就是在得到proposals後,設定不同的 IoU 閾值。然後因為閾值不同了,那麼根據與閾值 值的大小關係被分成的 pos 和 neg 樣本數量就也不同了~
在不同的 stage 中設定依次增大的 IoU 閾值。並且這一層的輸入是上一層的 bbox reg 之後的結果( 即上一層的輸出,上圖紅框框出了...)。原因是:因為較小的 IoU 閾值“監控”下的那些 bbox 可能不是很準,即,其與對應 gt 的 IoU 值是蠻小的。在本輪的 stage refine 後,box 會變得更準,使得其與對應 gt 的 IoU 值變大~這樣,把他們接著輸入到下一 stage,那麼它們可能也是可以通過更大 IoU 閾值的篩選,成為 pos 樣本的。這使得每一 stage 的 pos 樣本數基本可以保證足夠(不會因為 IoU 閾值的增大而減少很多...) 這就防止過擬合了。(因為每個 stage 中的樣本都很豐富,尤其 pos 樣本~)
文章主要是在 IoU 閾值上尋求提升點,其實沒考慮 multi-scale 改善小目標檢測的效果~不過,paper最後提及了它們把 FPN 做為 baseline network。 emmm... 這就很強了,把兩個 object detector 提升點結合起來,得到最佳效果!
以上兩篇的 data augmentation 都沒什麼驚豔的操作~...
DetNet: A Backbone network for Object Detection 一個專門為 object detector 設計的基礎 backbone network。
參考連結:知乎傳送門
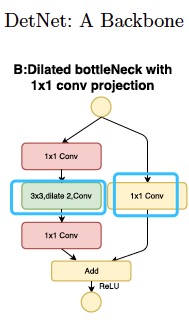
神奇的DetNet的主要亮點我認為是兩個:
1. dilate conv的引入,使得feature map的空間解析度和感受野這兩個矛盾量得到“和平共處”。
2. 上圖中的那個1x1 conv的作用,使得 in 和 out 間出現較大的差異(out = 直接過來的in + in 經過一系列conv的結果 ),相當於是構建了一個新的語義階段用於 object detector。
當然還有一些別的設計細節,如:因為stage4之後就沒有 feature map 的 size 減小了,所以引數量一下子就上去了。所以從 stage4 開始,輸出的 feature map 數量都統一成256,而不是像往常一樣越到後面越大(256 >> 512 >> 1024.....)
Mask R-CNN 亮點是RoIAlign 和 mask module
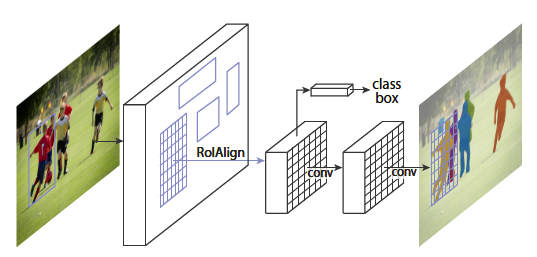
主框架見上圖。中間的RoIAlign是paper的一大提升。上一stage是類似Fast R-CNN一樣的檢測結構,下一stage是新增的mask module,使得網路可以實現segmentation,使用的是小FCN實現。
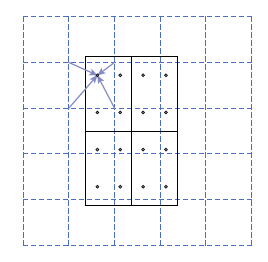
上圖是RoIAlign的實現。思想就是解決 RoI 與 feature map 無法“完美”對齊的問題。不再把浮點的座標直接整數化(包括RoI對映到feature map 的時候和進行RoI pool時候對每個bin的分割 這兩個過程均不把座標簡單粗暴的去整數化。) 而是座標不變,我們進行雙線性插值以對浮點數座標 進行賦 pixel value。
paper亮點2是新增的mask module。可實現instance segmentation。並且loss使用的sigmoid 而不是softmax~
更多細節有待補充~....
運用 Domain Adaptive 思想的 detector:Domain Adaptive Faster R-CNN for Object Detection in the Wild
亮點在於 domain adaptation,在例如自動駕駛這樣的實用場景,target image 的 label 幾乎是沒有的,所以 fine tune就不太行。需要把 source domain(含 label,如一些資料集中的 images) 和 target domain(實際場景中的 images,完全不 label)就行域適配。paper 實現了 image-level 和 instance-level 的適配。細節.....還請移步paper~
結合 GAN 的 detector: A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection
亮點是用 GSN gen 帶遮擋和形變的images ASDN、ASTN,得到 hard samples,然後聯合 Faster R-CNN訓練。另一亮點是結合了OHEM思想(online hard example mining)如下圖紅色的那部分操作~

ASDN
