
目標檢測(一)--Objectness演算法總體理解,整理及總結
1.原始碼下載及轉換為VS2012 WIN32版本。
http://www.cnblogs.com/larch18/p/4560690.html
2.原文:
http://wenku.baidu.com/link?url=ls5vmcYnsUdC-ynKdBzWgxMX9WomZH2sDRvnQ634UlN8p7oJm_ATFWrLlTQ3H_Co3y-7fL8Jt0MbHu800RWJtSABPKRxrtZvkjkXiFzdLLG
3.原文翻譯:
4.程式說明
5.總結:
能夠在識別一個物件之前察覺它,非常接近自底向上的視覺顯著性。根據顯著性定義,廣義的將相關領域的研究氛圍三個類別:區域性區域預測、顯著性物件檢測,物件狀態建議。
區域性區域檢測: 該模型旨在預測人眼移動的顯著點。啟發於神經生物學研究早期的視覺系統,Itti等人提出了第一個用於顯著性檢測的計算模型,此模型利用了多尺度影象特徵的中心-周圍的差異。Ma和Zhang提出了另一種區域性對比度分析方法來產生顯著性影象,並用模糊增長模型對其進行擴充套件。Harel等人提出了歸一化中心分佈特徵來突出顯著部分。 儘管區域性區域檢測模型已經取得了卓越的發展,但其傾向於在邊緣部分產生高顯著性值,而不是均勻地突出整個物件,因此,這種方法不適合用於物件檢測。
顯著性物件檢測: 該模型旨在檢測當前視野中最引人注意的物件,然後分割提取整個部分。Liu等人通過在CRF框架中引入區域性,區域的,全域性顯著性測量。Achanta等人提出了頻率調諧方法。Cheng等人提出了基於全域性對比度分析和迭代圖分割的顯著性物件檢測。更多的最新研究也試著基於過濾框架產生一些高分辨的顯著性圖,採用一些效果比較好的資料,或者是使用分層結構。這些顯著性物件分割在簡單的情景影象分析、內容感知編輯中可以達到很好的效果。而且可以作為一個便宜的工具處理大規模的網路影象或者是通過自動篩選結果構建魯棒性好的應用程式然而,這些方法很少能夠運用於包含多物件的複雜影象,但現實生活中,這樣的圖片確實最有意義的。
物件狀態建議: 該方法並不做決定,而是提供一定數量(例如:1000)包含所有類別物件的視窗。通過產生粗糙分割集,作為物件狀態建議已經被證實為一個減少分類器搜尋空間的有效方式,而且可以採用強分類器提高準確率。然後,這兩種方法計算量大,平均一張圖片需要2-7分鐘。Alexe等提出了一個線索綜合性的方法來達到更好、更有效的預測效果。Zhang等人採用方向梯度特徵提出了一個級聯的排序SVM方法。Uijlings等人提出了一個可選擇性的搜尋方法老獲得更好的預測效果。作者提出了一個簡單直觀的方法,相對於其他方法,達到了更好的檢測效果,而且快於其他流行的方法1000多倍。
另外,對於一個有效的滑動視窗物件檢測方法,保證計算量可控是非常重要的。Lampert等人提出了一個優雅的分支定界方法用於檢測。但是,這些方法只能用於加速分類器,而且是使用者已經提供了一個好的邊框。一些其他有效的分類器和近似核方法也已經被提出。這些方法旨在減小估計單個視窗的計算量,自然也能結合物件性建議進而減小損失。
物件狀態通常表示一個影象視窗包含任意類別物件的概率值。一個通用類別的檢測方法可以很方便的用於改善預處理過程:1)減少了搜尋空間;2)通過使用強分類器來提高檢測準確度.然而,設計一個好的通用類別的方法是非常困難的,需要:
- 具備很好的檢測率,找到所有前景物件;
- 提出一些建議,用於減少物件檢測的計算時間;
- 達到很高的計算效率,很容易拓展到其他實時以及大規模的應用程式中;
- 具備很好的通用性,方便用於各個類別的檢測器中,這樣可以減少計算量
暫時還沒有任何方法可以同時滿足以上全部要求。
認知心理學以及神經生物學研究表明,人擁有強大的能力感知物件。通過對認知反應時間和訊號在生物途徑中的傳輸速度進行深入的研究和推理,形成了人類注意力理論假定,該假定認為人類視覺系統只詳細處理影象的某些區域性,而對影象的其餘部分幾 乎視而不見,這也意味著,在識別物件之前,人類視覺系統中會有一些簡單的機制來定位可能的物件。
基於以上的考慮,作者提出一個非常簡單而且魯棒性強的特徵(BING),通過使用物件狀態得分來協助檢測物件。動機來自於物件普遍是獨立的,而且都具有很好定義的封閉輪廓。觀察到將影象歸一化到一個相同的尺度(例如:8*8)上,一般物件的封閉輪廓和梯度範數之間具有強聯絡。為了能夠有效量化影象視窗中物件狀態,將其重置大小為8*8,組合該視窗的畫素梯度的幅值作為為一個64位的特徵,通過級聯的支援向量機框架學習一個通用的物件檢測方法。而且這個二值化賦範特性(BING),它可以很有效的用於一般物件估計。而且只需要一些CPU原子操作(例如加法,按位移動等)。大部分現存的先進方法,一般採用複雜的分類特徵,而且需要採用加速方法以至於計算時間是可控的,相對於此,BING特徵是簡單樸素的。
作者在PASCAL VOC2007資料集上,廣義的評價了這個演算法。實驗結果顯示,方法很有效(在一個簡單的桌面CPU中達到300fps)的產生了一系列資料驅動,類別獨立,高分辨的物件視窗,通過使用1000個視窗(約為整個滑動視窗的0.2%),檢測率達到96.2%。使用5000個建議視窗以及3個不同的顏色空間,可以達到99.5%。我們也核實了方法的通用性。我們訓練了6個已知類別,然後在14個未知類別上進行測試,得到了很好的效果。相對於其他流行的方法,BING特徵能夠使我們達到更好的檢測率,而且速率提高了1000多倍。實現了之前我們提到的關於一個好的檢測器的要求。
6.演算法流程圖。
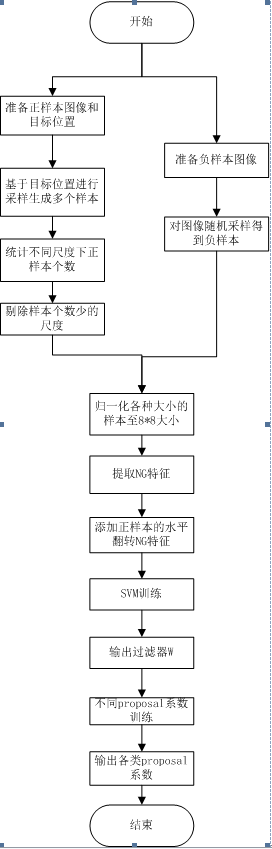
基本與演算法無關的東西,這裡不再贅述,下面開始邊熟悉原始碼,邊更新部落格。
6.1、生成正樣本
演算法首先,對每張影象上,可能的所有標註框,取樣生成不同尺度(該尺度在一定經驗值範圍內)的樣本位置,並計算新生成的正樣本與原始樣本重疊率,保留重疊率超過50%的,重新歸一化到8*8大小,計算新生成的有效正樣本的梯度特徵,並在水平方向翻轉,最終儲存新生成樣本8*8的梯度特徵與該特徵的水平翻轉特徵作為xP.
6.2.負樣本,固定100次隨機產生100個備選的負樣本視窗,篩選出與每張圖片中,與所有目標的重疊率都小於50%的負樣本窗,並將該視窗內儲存影象作為負樣本。
3.尺度處理,在篩選有效正樣本時,同時儲存了水平,垂直尺度係數,但是實際儲存的尺度size是歸一化對映後的值,即(h - min) * num + w - min + 1,其中h,w表示篩選出的有效正樣本相對原始目標的垂直,水平尺度係數,實際上,還是儲存的尺度係數,只是在資料結構上,採用雜湊對映儲存罷了。
6.4.判定有效樣本,程式下一步,會在上面取樣生成的所有有效正樣本,進行直方圖統計,統計出每個尺度下的樣本數。例如有2500多個影象檔案,計算所有正樣本數,統計每個尺度下的正樣本數。根據統計結果,剔除掉正樣本數少於50的尺度。儲存剩下的尺度統計結果,接著,對所有正負樣本,統一分配到一個二維矩陣,垂直表示樣本數,水平表示樣本的8*8梯度特徵值,直接儲存。
以上,屬於該演算法的第一個亮點。
演算法主要是用來加速傳統的滑動視窗物件檢測,通過訓練通用的物件估計方法來產生候選物件視窗。作者觀察到一般物件都會有定義完好的封閉輪廓,而且通過將相關影象視窗重置為固定大小,就可以通過梯度幅值進行區分。基於以上的觀察以及複雜度的考慮,為了明確訓練方法,將視窗固定為8*8的,並將梯度幅值轉化為一個簡單的64維的特徵來描述這個視窗。這就相當於我們看路上走的人一樣,在很遠的地方即使我們沒看清楚臉,只是看到一個輪廓也能識別出是不是我們認識的人,反而,如果臉貼著臉去看一個人可能會認不出來。
也就是作者發現,在固定視窗的大小下,物體與背景的梯度模式有所不同。如下圖所示。圖(a)中綠框代表背景,紅框代表物體。如果把這些框都resize成固定大小,比如8X8,然後求出8X8這些塊中每個點的梯度(Normed Gradient,簡稱NG特徵,叫賦範梯度特徵,就是計算梯度範數,即sqrt(gx^2 + gy^),實際就是該點的L2範數梯度,但是作者實現時,採用-1,0,1方式計算gx或者gy,因此,用|gx| + |gy|近似代替梯度的L2範數),可以明顯看到物體與背景的梯度模式的差別,如圖1(c)所示,物體的梯度分佈呈現出較為雜亂的模式,而背景的較為單一和清楚。其實這個道理很淺顯,就是影象中背景區域往往呈現出homogeneous的特性,早期的影象區域分割方法就是依靠這種特性來做的。然後我個人覺得這裡不一定要用梯度,用其他一些統計特徵甚至是影象特徵都有可能得到類似的結果。
所以,作者首先將所有的標註樣本,用不同尺度縮放取樣,將取樣出的有效正樣本統一縮放到8*8,計算NG特徵,也就是下面圖中a生成c在過程。這樣,通過SVM訓練這些NG特徵,得到目標和背景的第一次區分模型。
下面是原文的解釋
物件一般是具有很好定義封閉輪廓和中心的。重置視窗的時候,就相當於將現實中的物件縮小到一個固定大小,因為在封閉的輪廓中,影象梯度變化很小,所以它是一個很好的可區分特徵,就像是圖1中,輪船和人在顏色,形狀,紋理,光照等方面都有很大的不同,他們在梯度空間都存在共性。為了有效地利用觀察結果,我們首先將輸入影象重置為不同尺度的,在不同的尺度下計算梯度。然後再重置為取8*8大小的框,作為一個對應影象的64維的NG特徵。
我們採用的NG特徵,是一個密集的且緊湊的objectness特性,有以下幾點優勢:首先,由於歸一化了支援域,所以無論物件視窗如何改變位置,尺度以及縱橫比,它對應的NG特徵基本不會改變。也就是說,NG特徵是對於位置,尺度,縱橫比是不敏感的,這一點是對於任意類別物件檢測是很有用的。

圖1 儘管物件(紅色)和背景(綠色),在影象空間(a)呈現出了很大的不同,通過一個適當的尺度和縱橫比,我們將其分別重置為固定大小(b),他們對應的NG特徵(c)表現出很大的共性,基於NG特徵,我們學習了一個簡單的64D線性模型(d),用來篩選物件視窗。
這種不敏感的特性是一個好的物件檢測方法應該具備的。第二,NG特徵的緊湊性,使得計算和核實更加有效率,而且能夠很好的應用在實時應用程式中。
NG特徵的缺點就是識別能力不夠。但一般而言,會採用檢測器來最終缺點結果的誤報率。
以上,上部分結束。
-----------------------------------------------------------------------------------------------------------------------
6.5.SVM第一級訓練
首先,演算法傳遞進入第一級SVM的樣本總數,在超過SVM預設引數值時,採用SVM預設訓練總樣本數。用所有正樣本以及剩下的數量採用隨機從原負樣本中抽取。即,負樣本在這種情況下,不是全部參加SVM第一級訓練。而是隨機抽取一部分,保證總樣本數達到SVM預設訓練總樣本數。
演算法做一些SVM的初始化,涉及到樣本標籤Y,實際上,正樣本預設都為有標籤,以及SVM引數初始化等,這個後續另開文說明。這裡不說介紹。
通過第一級SVM訓練後,演算法生成第一級SVM模型,轉換成8*8,並歸一化到1~255,儲存。該模型w是用來下文中投票投票打分的,為第二級SVM學習做準備。
6.6 二值化模型引數w
首先通過上面的訓練,我們可以得到分類的模型線性w,第一個要二值化的目標就是它,二值化的思想可以簡單想象成找若干個基向量,並用這些基向量的線性組合來記表示w, 而且這些基向量的每一維只能取1或者-1(二值嘛)。那麼假設我們用了Nw個基向量,每個基向量為aj, j = 1,...,Nw,那麼就有

演算法1的步驟也很明確,每一個都生成一個基向量,此基向量每一維都是由當前殘差的符號決定,然後用當前殘差減去殘差在這基向量的投影(相當於去掉模型在這一維上的分量)。但在計算中因為二進位制位只能為0或者1,所以為了處理方便,取

也就是說,αj表示基向量{-1,1},βj表示校準係數,同時,將每個基向量,對映到一個64位型別的資料中。
這裡,實際上採用Gram-Schmidt正交化,只取了包含大部分資訊的前Nw個正交向量作為輸出,目的也是為了降低計算量。二值化的目的在於後期位運算,後面還會把NG特徵也二值化。直接採用硬體指令大幅度地提升速度。
增加點自己的體會:
程式碼中,Nw取2,也就是SVM生成的W 是8*8矩陣,矩陣元素任意值,通過這個二值化過程,生成2個基向量,每個基向量完全覆蓋了W中每個元素,但是此時在基向量中,每個元素對應的取值變成0或者1,因此,原w的64個元素,拼接成了一個64位的單個數據,即基向量。同時,對應該基向量的校準係數,演算法為了後期加速,只近似處理高4位的資料,因此,校準係數只有儲存4個,且都是一樣的值,但是由於後期位移運算,這裡就把校準值放置到了對應bit位。於是,2個基向量,生成8個校準係數,2個64位的資料。
6.7 打分視窗
為了找到影象中的一般物件,對每張訓練影象(注意,這裡是原影象,不是標註框),進行上文生成正樣本時得到所有尺度的量化,掃描每個尺度定義好的量化視窗(依據尺度或者是縱橫比,也就是說,這裡只是對原影象依據之前胡尺度係數做縮放,不是縮放到8*8,因此,才有下文的I)。每一個視窗通過上文得到模型w獲得得分
sl =<w,gl> (1)
l=(i,x,y) (2)
sl代表過濾器得分,gl表示NG特徵,l表示座標,i表示尺度,(x,y)表示視窗位置。其實就是一個濾波器,向量內積實現。也就是說,SVM第一級訓練得到的w作為權值。該w作用於視窗(即NG特徵,不是固定8*8大小),打分越高,就約接近目標。
下面引入w與二進位制的內積運算公式:
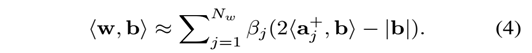 只需要按位與和位元組統計操作.下面解釋如何得到b.
只需要按位與和位元組統計操作.下面解釋如何得到b.
因此,為了實現(1)的快速計算,作者先用上面的演算法,二值化了w,現在開始二值化NG,即gl引數,得到上面的b.
接下來我們還要對NG特徵進行二值化,還記得我們剛才將NG歸一化到[0,255]之間吧,那麼8X8視窗上的每個點的NG特徵值就可以用一個byte來儲存,也就是每個值我們都可以用一個8位的二進位制串來表示。那麼我們就有一個8X8X8的三維矩陣,前兩維是視窗位置(行,列),第三維是在二進位制串中的位置(頁)。舉個例子,比如視窗中第1行,第2列的NG特徵值是192,換成二進位制就是1100 0000,那麼矩陣的元素(1,2,1) = (1,2,2)= 1,(1,2,3),…,(1,2,8)= 0;那麼我們一頁一頁地將矩陣元素取出來,再將每頁8X8的矩陣元素排成一個64位的二進位制串並存進一個int64裡。既然思路已經有了,做法也就很簡單了:對於每一頁,將每一行每個元素取出來,不斷加入int64中並左移1位,最後得到那個int64每一位對應的元素座標排列就應該是(1,1)(1,2)(1,3)…(8,8)。然後作者在這裡又玩了一個trick,他說你這樣每次移動一位不是要迴圈64次嘛,如果先將8個拼成一組(就是剛才那樣左移1次),那麼只需要移動8組就好了啊!而且,這樣在相鄰的視窗中還能重用重疊的部分(在VS2010
的Debug模式下我試了下,1個數“每次左移1位,移動1萬次”和“每次左移100位,移動100次”兩種情況,的確是後者速度快)。
最後,為了進一步節省儲存空間,還可以只取NG值的高位來作二值化。因為比如192和193、194,它們的二進位制表達分別是1100 0000, 1100 0001和 1100 0010,要是我只看前面4位,後面4位忽略(取0)的話,那麼它們的取值都是192。也就是我們可以用192來約等於193和194,這樣我們就不需要用到8位那麼多了!寫成公式就是下面的式(2)這樣,其中Ng 是我們要用的高位的位數(也就是前面說的三維矩陣的頁),bk,l就是對應三維矩陣中的第k頁(二值)。
最後將二值化模型w和二值化NG,結合起來對視窗打分的操作由卷積運算變成了大部分是位運算操作,
其中C_j,k是
上面的計算很容易通過位運算和SSE指令(支援8x8=64bit)來完成快速運算。
然後,運用非最大抑制(NMS),做下濾波。
這裡,寫的比較雜,再次總結一下,
首先,根據第一級SVM得到模型引數w,對每張訓練影象,進行所有尺度變換(不是固定8*8大小),然後計算NG特徵,接著根據上文的打分系統,計算每個尺度下的sl(實際上,二值化w和二值化NG特徵,就是BING特徵).並重新排序,利用NMS消除掉高分點附近領域內的打分值。且,這裡只選擇指定閾值以上的高分點。然後,在原始影象,找到對應打分點對應的方框大小,並儲存。這樣,針對每張影象,我們計算了不同尺度i下的打分項以及相對應的可能目標匡。然後,針對所有可能的目標匡,我們將其與原始影象中所有有效正樣本做重疊率比對,只要有一個正樣本框與該可能目標匡重疊與大於0.5,則該可能目標匡作為正樣本,否則為負樣本。在傳入第二級SVM時,作者將可能目標框的打分值,重新根據尺度整合,即不同尺度下下,所有的打分值,作為正負樣本。在第二級訓練時,針對每個尺度,訓練一次。
6.8第二級SVM訓練
作者針對每種尺度下的打分值,訓練SVM,每種尺度下樣本總數不超過10W。超過,則隨機在正負樣本中抽取。確保先讀取正樣本,後需剩餘的位置隨即用負樣本填滿。訓練結束後,生成新的權值vi,ti.
以上,訓練程式結束,下面進入測試部分。
--------------------------------------------------------------------------------
測試程式,在讀入測試圖片後,計算影象的BING特徵,跟二級SVM訓練預處理一樣,對影象進行不同尺度的縮放,計算NG,打分統計得到sl(用的還是第一級模型的w)
然後,為每個尺度提供一些建議視窗。相對於其他視窗(例如:100*100),一些尺度(例如:10*500)的視窗包含物件的可能性是很小的。因此我們定義物件狀態得分(校準過濾器得分):ol = vi*sl+ti (3)針對不同尺度i的視窗,得到不同的獨立學習係數。使用校準函式(3)是非常快的,通常只需要在最終的建議視窗重排。
這裡,打分用的權值是二級模型訓練出的,即上文的vi,ti.得到ol重新排序。整個過程,計算時間,給出每個檢測圖象的平均測試時間。並儲存打分結果與對應的目標框。
打分越高,越接近目標。實際上,演算法生成的就是打分視窗,也就是所為的物件狀態。下面測試的時候,根據打分視窗與標註的測試視窗重疊率大於0.5就認為檢測到了。
接著,作者開始繪製結果,根據檢測出的候選框與每個測試標註框計算重疊率,大於0.5,就認為檢測到了(1),否則score為0未檢到。之後,計算平均重疊率和平均檢測率.如下圖:

這裡解釋下重疊率:
DRandMABO
上面的精度曲線稱為DR-#WIN curves,源自TPAMI 2012的一篇論文:Measuring the objectness of image windows。原文還提出了將視窗數量比如[[0,5000]歸一化到[0,1]之間,用曲線下的面積作為目標檢測的度量結果,並稱之為the area under the curve(AUC),這樣AUC的範圍就在[0,1]之間了。
檢測精度DR的計算
DR的計算是參考The PASCAL Visual Object Classes (VOC) Challenge,目標檢測任務中DR的計算的是true/false positive精度,將演算法檢測目標結果放到groud truth中,將“預測目標區域與groud truth區域的交集”除以“預測目標區域與groud truth區域的並集”作為DR: