
Cs231n課堂內容記錄-Lecture 8 深度學習框架
Lecture 8 Deep Learning Software
課堂筆記參見:https://blog.csdn.net/u012554092/article/details/78159316
今天我們來介紹深度學習軟體,它們的效能、優劣以及應用流程,包括CPU、GPU和一些流行的深度學習框架。

一、 CPU vs GPU
GPU被稱作顯示卡(graphics card),或者圖形處理器(Graphics Processing Unit),是一種專門進行影象運算工作的微處理器。這裡不得不提到NVIDIA和AMD,深度學習中往往採用NVIDIA。CPU只有少量的核,這意味著它們可以同時執行4到20個執行緒,且運作相互獨立。GPU都有成千上萬的核數,NVIDIA Titan Xp有3840個核,GPU的缺點是每一個核的執行速度非常慢,而且它們能夠執行的操作沒有CPU多,它們沒辦法獨立操作,只能多個核合作完成某項任務。所以我們不能直觀地比較CPU和GPU的核數。
在記憶體上,CPU有快取記憶體,但是相對較小,一般是4到32GB,取決於RAM;GPU在晶片中內建了RAM,Titan Xp內建記憶體有12 GB。GPU同樣有自己的快取系統,在GPU的12個G記憶體和核之間有多級快取,實際上和CPU的多層快取相似。CPU對於通訊處理來說是足夠的,可以做很多事情,GPU則更加擅長高度並行處理。最典型的演算法就是矩陣乘法,矩陣的各行各列的點積運算都是獨立的,所以可以進行並行運算。CPU可能會進行序列運算,一個一個地計算矩陣元素,這會導致你的運算速度很慢。
我們可以在GPU上寫出可以直接執行的程式,NVIDIA有個叫做CUBA的抽象程式碼,可以讓你寫出類C的程式碼,可以在GPU上直接執行。但是寫CUDA程式碼不太容易,想要寫出高效能有充分發揮GPU優勢的CUDA程式碼實際上是很困難的。你必須非常謹慎地管理記憶體結構並且不遺漏任何一個快取記憶體以及分支誤預測等等。NVIDIA開源了很多庫可以用來實現高度優化的GPU的通用計算功能,比如cuBLAS庫可以實現各種各樣的矩陣乘法。cuDNN可以實現卷積、前向和反向傳播、批歸一化、遞迴神經網路等各種各樣的功能。所以在做深度學習專案時你不需要自己編寫CUDA程式碼而是直接呼叫已經寫好的程式碼。
另一種語言是OpenCL,這種語言更加普及,可以在GPU、CPU以及AMD上執行,但是沒有人花費大量的精力優化深度學習程式碼,所以效能沒有CUDA好。在目前看來,NVIDIA有絕對的優勢。
二、 Deep Learning Frameworks
1.深度學習框架的優點:
(1) Easily build big computational graphs
(2) Easily compute gradients in computational graphs
(3) Run it all efficiently on GPU (wrap cuDNN, cuBLAS, etc)
2.各個框架:
numpy的缺點是無法提供梯度計算,所以只能自己寫。另外不能在GPU上執行,只能在CPU上執行。

之後多數框架的思路大體都是希望前向網路的書寫類似於numpy,但是可以在GPU上執行,又能自動計算梯度。tensorflow實現了這一點,另外你可以實現CPU和GPU的轉換,比如在前向網路之前加入一行如圖的程式碼。

3.tensorflow:

這裡我們定義了一個兩層的全連線網路,來作為tf的講解例項:

這些佔位符是計算圖的輸入結點,我們的資料會輸入到這個節點,從而進入計算圖中。

maximum定義了一個RELU函式,這幾行程式碼沒有做實質性的運算,只是建立圖模型。

大多時候tf是從np中接收資料,我們使用字典儲存這些資料。

我們告訴模型希望計算w1和w2的loss,並且通過字典引數傳遞資料字典。
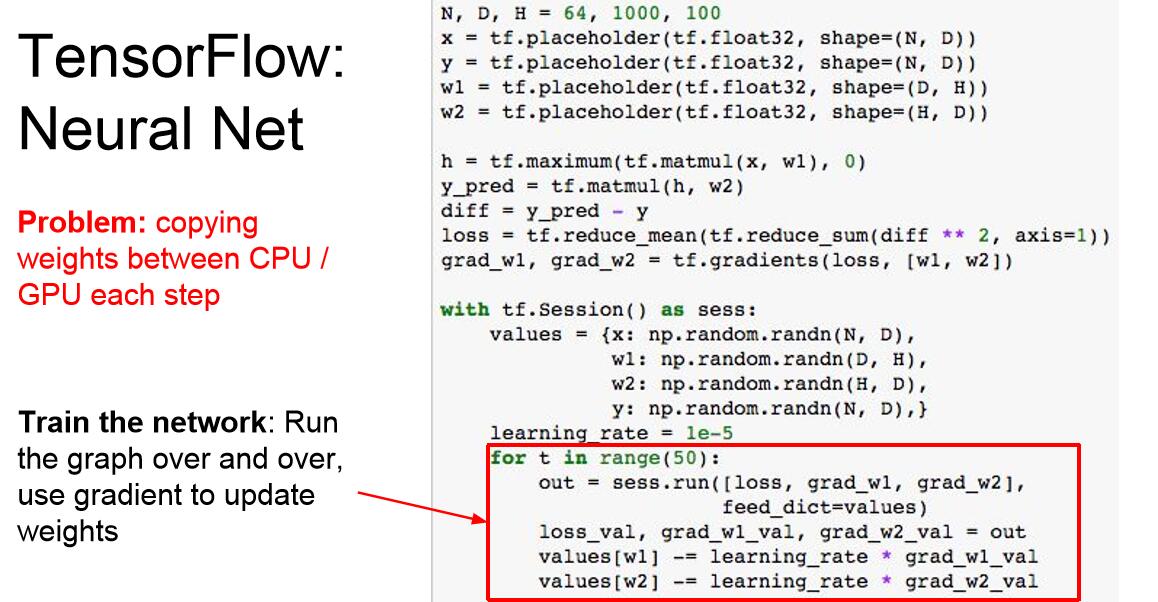
我們每一次運算圖都需要從numpy陣列中複製權重到tensorflow中才能得到梯度,然後將梯度複製回np陣列,如果你的權重值和梯度值非常多,需要在GPU上執行的時候,np到tf的過程就是CPU到GPU的資料傳輸,而這個過程是極其浪費時間、耗費資源的。

解決方案是我們將w1,w2變為變數而不是輸入入口,這樣它們就可以儲存在tf網路中,這是我們需要在tf網路中初始化這些變數,所以用random_normal初始化,這個語句並沒有真正初始化,而是告訴tf應該怎樣進行初始化,更新操作也要在tf計算圖中進行。

全域性引數的初始化操作。

這是因為我們並沒有將new_w1和new_w2加入計算圖中參與運算。我們只告訴tf說要計算loss,這並不需要執行更新操作,所以tf只執行了要求結果所必須的操作。

但是這裡還有一個問題,neww1和neww2都是很大的張量,當我們告訴tf我們需要這些輸出時(也就是像loss一樣讓tf輸出它們到np中),每次迭代就會在CPU和GPU之間執行這些操作,這是我們不希望的,所以我們在計算圖中新增一個仿製節點,這個節點不輸出任何值,只是保證計算圖進行了更新操作。
問題1:為什麼我們不把x、y也放入計算圖中?
TA解釋:在這個計算圖中,我們每一次迭代都重複使用了同樣的X和Y,所以在這個例子中應該被放入計算圖中,但是更為常用的情況是x和y是資料集的mini batch,所以它們在每次迭代之後都是變化的。
合理解釋:因為w1和w2是與資料無關對的,本身更類似於計算圖中可以自我更新的屬性,所以我們初始化之後就不用保留傳輸介面而只讓它們在計算圖中更新就行。但是x和y是資料集的mini batch,所以它們在每次迭代之後都要重新輸入的。
問題2:tf.group返回了什麼?
這是tf的一個小trick,當你在計算圖中內部執行group的時候,它返回的是一個具體的值,類似於節點內部的操作值,告訴計算圖我需要進行更新;而當你執行Session.run的時候,返回的就是None,因為你沒有定義計算圖要輸出的是什麼,所以計算圖只會執行操作,而不輸出值。
問題3:為什麼loss的返回值是一個值,而updates就是none呢?
loss是一個值,而updates可以看成是一種特殊的資料型別,它並不返回值,而返回空。實際上是因為tf.reduce.mean的返回值就是一個具體的值,而group的返回是一個操作。
參見官方文件中關於group的說明:
https://www.tensorflow.org/api_docs/python/tf/group?hl=zh-cn