
基於深度學習的文字分類方法庫(NLP)
注:本文翻譯自GitHub上的一篇介紹,介紹了基於深度學習的文字分類問題。程式碼和部分模型介紹在GitHub上,文末有連結。
這個庫的目的是探索用深度學習進行NLP文字分類的方法。
它具有文字分類的各種基準模型。
它還支援多標籤分類,其中多標籤與句子或文件相關聯。
雖然這些模型很多都很簡單,可能不會讓你在這項文字分類任務中游刃有餘,但是這些模型中的其中一些是非常經典的,因此它們可以說是非常適合作為基準模型的。
這個幾個模型也可以用於構建問答系統,或者是序列生成。
我們還探討了用兩個seq2seq模型(帶有注意的seq2seq模型,以及transformer:attention is all you need)進行文字分類。同時,這兩個模型也可以用於生成序列和其他任務。如果你的任務是多標籤分類,那麼你就可以將問題轉化為序列生成。
我們實現了兩個記憶網路:其中一個是動態儲存網路(dynamic memory network)。在此之前,該模型已經在問答問題、情感分析、序列生成任務中達到了最佳水平。它被稱為可以做多種不同任務的模型,並且都可以達到較高的水平。它有四個模組。最關鍵的組成部分就是事件記憶模組(episodic memory module)。該模型利用門機制(gate mechanism)來實現注意力,同時使用 gated-gru 去更新 episodic memory,然後還有另一個gru(垂直方向)來實現隱藏狀態的更新。該模型還具有傳遞推理的能力。
第二個記憶網路:迴圈實體網路(recurrent entity network):追蹤世界的狀態。它用鍵值對塊(blocks of key-value pairs)作為記憶,並行執行,從而獲得新的狀態。它可以用於使用上下文(或歷史)來回答建模問題。例如,你可以讓模型讀取一些句子(作為文字),並提出一個問題(作為查詢),然後請求模型預測答案;如果你像查詢一樣向其提供故事,那麼它就可以進行分類任務。
如果你需要樣本資料和一些預先用word2vec訓練好的詞嵌入(word embedding),可以在closed issues中找到,例如:issues 3
你也可以在data資料夾中找到所需的資料集。data檔案包含兩個檔案。sample_single_label.txt . 50k個單一的標籤資料
sample_multiple_label.txt .20k個多標籤資料。輸入和標籤是用“label”分開的。
如果你想了解更多關於文字分類,或這些模型可以應用的任務的資料集詳細資訊,可以點選連結進行查詢,我們選擇了一個:https://biendata.com/competition/zhihu/
模型:
1.fastText
2.TextCNN
3.TextRNN
4.RCNN
5.分層注意網路(Hierarchical Attention Network)
6.具有注意的seq2seq模型(seq2seq with attention)
7.Transformer("Attend Is All You Need")
8.動態記憶網路(Dynamic Memory Network)
9.實體網路:追蹤世界的狀態
10.Ensemble models
11.Boosting:
該模型是多模型堆疊而來的。每一層都是一個模型。結果將基於加在一起的logits,層之間的唯一連結是標籤權重。每個標籤的淺層預測誤差率將成為下一層的權重。那些錯誤率很高的標籤會有很大的權重。所以後面的層將更加關注那些錯誤預測的標籤,並試圖修復前一層的誤差。結果是,我們可以得到一個很強大的模型。檢視: a00_boosting/boosting.py
其他模型:
1.BiLstm Text Relation
2.Two CNN Text Relation
3.BiLstm Text Relation Two RNN
效能(多標籤標籤預測任務,要求預測能夠達到前5,300萬訓練資料,滿分:0.5)

Ensemble of TextCNN,EntityNet,DynamicMemory: 0.411
Ensemble EntityNet,DynamicMemory: 0.403
注意:
m : minutes,h:hours
HierAtteNetwork : Hierarchical Attention Network
Seq2seqAttn :Seq2seq with attention
DynamicMemory :DynamicMemoryNetwork
Transformer : Attention Is All You Need
用途:
1.模型在xxx_model.py中
2.執行python xxx_train.py來訓練模型
3.執行python xxx_predict.py進行推理(測試)。
每個模型在模型下都有一個測試方法。你可以先執行測試方法來檢查模型是否能正常工作。
環境:
python 2.7+tensorflow 1.1
(tensorflow 1.2,1.3,1.4也是可以應用的;大多數模型也應該在其他tensorflow版本中正常應用,因為我們使用非常少的特徵來將其結合到某些版本中;如果你使用的是python 3.5,只要更改print / try catch函式的話,它也會執行得很好。)
TextCNN 模型已經可以轉換成python 3.6版本
注意:
一些util函式是在data_util.py中的;典型輸入如:“x1 x2 x3 x4 x5 label 323434”,其中“x1,x2”是單詞,“323434”是標籤;它具有一個將預訓練的單詞載入和分配嵌入到模型的函式,其中單詞嵌入在word2vec或fastText中進行預先訓練。
模型細節:
1.快速文字(fastText)
在給句子中每一個word編碼後,隨後這個詞表示平均為一個文字表示,這個文字表示將會反饋給一個線性分類器。他使用softmax函式來計算預定義類中的概率分佈。利用交叉熵來計算損失。bag of word表示不會考慮到詞序問題。為了考慮詞序,n-gram特徵用於捕獲本地詞序的部分資訊;當類的數量很大時,計算線性分類器的計算量很大。所以他使用分層softmax來加速訓練過程。
1.使用bi-gram 或者tri-gram。
2.使用NCE損失,加速我們的softmax計算(不使用原始論文中的層次softmax)
結果:效能與原始論文中的一樣好,速度也非常快。
檢視:p5_fastTextB_model.py
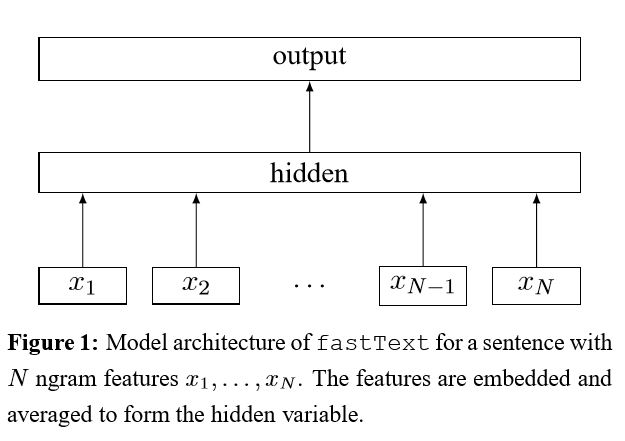
2.文字卷積神經網路(Text CNN)
結構:降維---> conv ---> 最大池化 --->完全連線層--------> softmax
檢視:p7_Text CNN_model.py
卷積神經網路是解決計算機視覺問題的主要手段。現在我們將展示CNN如何用於NLP,特別是文字分類。句子長度會因人而異。 所以我們將使用pad來獲得固定長度,n。 對於句子中的每個標記,我們將使用單詞嵌入來獲得一個固定的維度向量d。 所以我們的輸入是一個二維矩陣:(n,d)。這跟CNN用於圖象是類似的。
首先,我們將對我們的輸入進行卷積計算。他是濾波器和輸入部分之間的元素乘法。我們使用k個濾波器,每個濾波器是一個二維矩陣(f,d)。現在輸出的將是k個列表,每個列表的長度是n-f+1。每個元素是標量(scalar)。請注意,第二維將始終是單詞嵌入的維度。我們使用不同的大小的濾波器從文字輸入中獲取豐富的特徵,這與n-gram特徵是類似的。
其次,我們將卷積運算的輸出做最大池化。對於k個列表,我們將得到k個標量。
第三,我們將連線所有標量來獲得最終的特徵。他是一個固定大小的向量。它與我們使用的濾波器的大小無關。
最後,我們將使用線性層把這些特徵對映到之前定義的標籤。
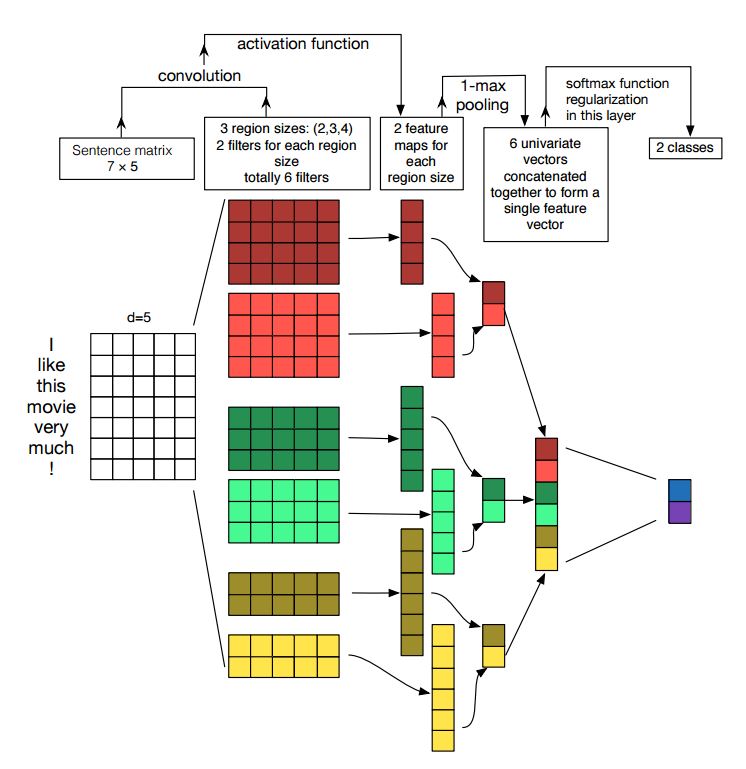
3.文字迴圈神經網路(Text RNN)
結構1:embedding--->bi-drectional lstm ---> concat output -->average-----> softmax layer
檢視:p8_Text RNN_model.py
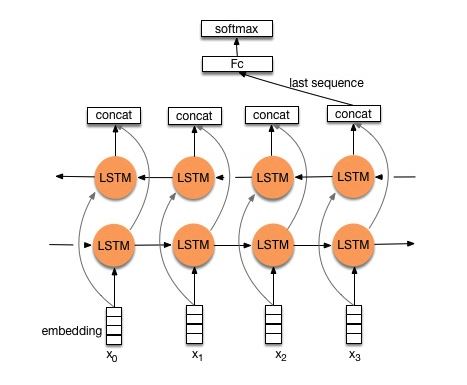
結構1:embedding--->bi-drectional lstm --->dropout ---> concat output -->lstm---> dropout---> FC layer-----> softmax layer
檢視:p8_TextRNN_model_mutillayer.py
4.雙向長短期記憶網路文字關係(BiLstm Text Relation)
結構與Text RNN相同。但輸入是被特別設計的。例如:輸入“這臺電腦多少錢?膝上型電腦的股票價格(how much is the computer? EOS price of laptop)”。“EOS”是一個特殊的標記,將問題1和問題2分開。
檢視:p9_BiLstm Text Relation_model.py
5.兩個卷積神經網路文字關係(two CNN Text Relation)
結構:首先用兩個不同的卷積來提取兩個句子的特徵,然後連線兩個功能,使用線性變換層將投影輸出到目標標籤上,然後使用softmax。
檢視:p9_two CNN Text Relation_model.py
6.雙長短期記憶文字關係雙迴圈神經網路(BiLstm Text Relation Two RNN)
結構:一個句子的一個雙向lstm(得到輸出1),另一個句子的另一個雙向lstm(得到輸出2)。那麼:softmax(輸出1 M輸出2)
檢視:p9_BiLstm Text Relation Two RNN_model.py
有關更多詳細資訊,你可以訪問:《Deep Learning for Chatbots》的第2部分—在Tensorflow中實現一個基於檢索的模型(Implementing a Retrieval-Based Model in Tensorflow)
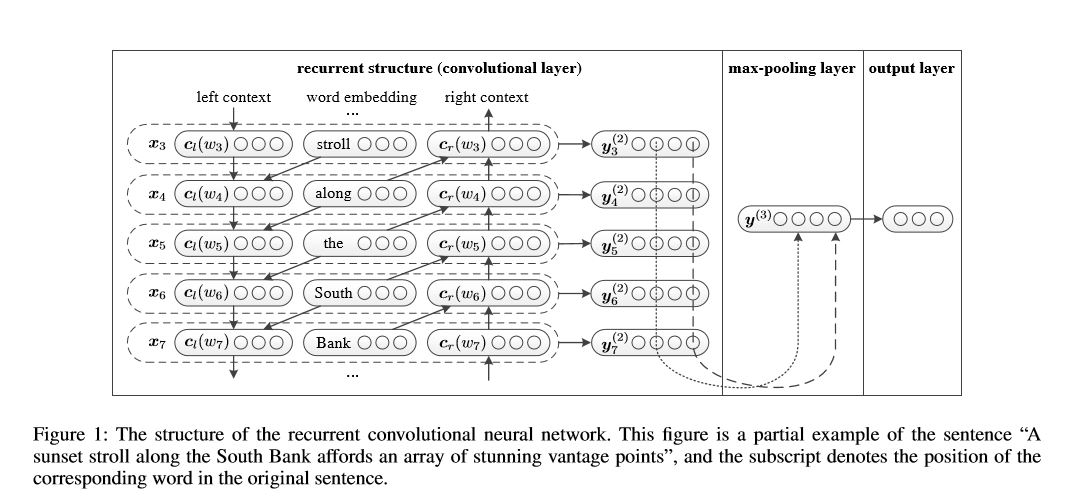
7.迴圈卷積神經網路(RCNN)
用於文字分類的迴圈卷積神經網路。
結構:1)迴圈結構(卷積層)2)最大池化3)完全連線層+ softmax
它用左側文字和右側文字學習句子或文件中的每個單詞的表示:
表示當前單詞= [left_side_context_vector,current_word_embedding,right_side_context_vecotor]。
對於左側文字,它使用一個迴圈結構,前一個單詞的非線性轉換和左側上一個文字;類似於右側文字。
檢視:p71_TextRCNN_model.py
8. 分層注意網路(Hierarchical Attention Network)
結構:
1)降維
2.詞編碼器:詞級雙向GRU,以獲得豐富的詞彙表徵
3.次注意:詞級注意在句子中獲取重要資訊
4.句子編碼器:句子級雙向GRU,以獲得豐富的句子表徵
5.句子注意:句級注意以獲得句子中的重點句子
6.FC + Softmax
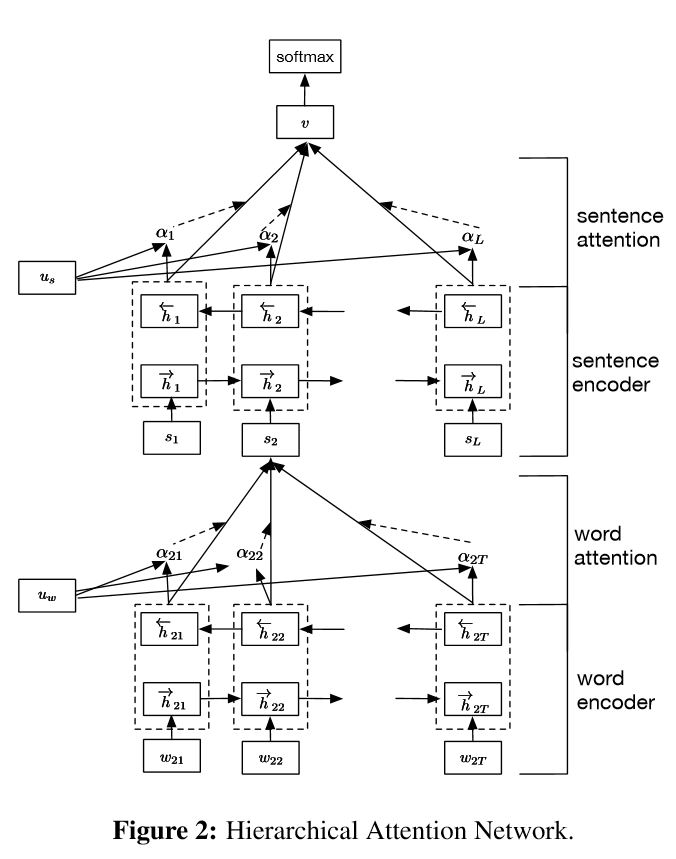
在NLP中,可以對單個句子進行文字分類,但是它也可以用於多個句子。我們可以稱之為文件分類。Wordsd的形式將sentence。並且sentence是檔案的形式。在這種情況下,可能存在一種內在的結構。那麼我們如何模擬這種型別的任務呢?檔案的所有部分是否同樣重要?我們如何確定哪一部分比另一部分更重要?
它有兩個獨特的特點:
1)它具有體現檔案層次結構的層次結構
2)它在單詞和句子級別使用兩個級別的注意力機制,它使模型能夠捕捉到不同級別的重要資訊。
Word Encoder:對於句子中的每個單詞,它都嵌入到分佈向量空間中的詞向量中。它使用雙向GRU來編碼句子。通過從兩個方向連線向量,它現在可以形成句子的表示,它也捕獲上下文資訊。
Word Attention:同樣的詞比其他的更重要。說明注意力機制是有效的。它首先使用一層MLP來獲得句子的隱藏表示,然後測量該單詞的重要性作為與單詞級別上下文向量Uw的相似性,並通過softmax函式獲得歸一化重要性。
Sentence Attention:句子等級向量用於測量句子之間的重要性。類似於詞注意力機制。
資料輸入:
一般來說,這個模型的輸入應該是幾個句子,而不是一個句子。形式是:[None,sentence_lenght]。其中None意味著batch_size。
在我的訓練資料中,對於每個樣本來說,我有四個部分。每個部分具有相同的長度。我將四個部分形成一個單一的句子。該模型將句子分為四部分,形成一個形狀為:[None,num_sentence,sentence_length]的張量。其中num_sentence是句子的個數(在我的設定中,其值等於4)。
檢視:p1_HierarchicalAttention_model.py
9. 具有注意的Seq2seq模型
一、結構:
2)bi-GRU也從源語句(向前和向後)獲取豐富的表示。
3)具有注意的解碼器。
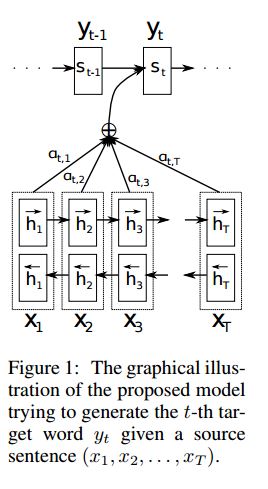
二、資料輸入:
使用三種輸入中的兩種:
1)編碼器輸入,這是一個句子;
2)解碼器輸入,是固定長度的標籤列表;
3)目標標籤,它也是一個標籤列表。
例如,標籤是:“L1 L2 L3 L4”,則解碼器輸入將為:[_ GO,L1,L2,L2,L3,_PAD];目標標籤為:[L1,L2,L3,L3,_END,_PAD]。長度固定為6,任何超出標籤將被截斷,如果標籤不足以填補,將填充完整。
三、注意機制:
1.傳輸編碼器輸入列表和解碼器的隱藏狀態
2. 計算每個編碼器輸入隱藏狀態的相似度,以獲得每個編碼器輸入的可能性分佈。
3. 基於可能性分佈的編碼器輸入的加權和。
通過RNN Cell使用這個權重和解碼器輸入以獲得新的隱藏狀態
四、Vanilla E編碼解碼工作原理:
在解碼器中,源語句將使用RNN作為固定大小向量(“思想向量”)進行編碼:
(1)當訓練時,將使用另一個RNN嘗試通過使用這個“思想向量”作為初始化狀態獲取一個單詞,並從每個時間戳的解碼器輸入獲取輸入。解碼器從特殊指令“_GO”開始。在執行一步之後,新的隱藏狀態將與新輸入一起獲得,我們可以繼續此過程,直到我們達到特殊指令“_END”。我們可以通過計算對數和目標標籤的交叉熵損失來計算損失。logits是通過隱藏狀態的投影層(對於解碼器步驟的輸出,在GRU中,我們可以僅使用來自解碼器的隱藏狀態作為輸出)。
(2)當測試時,沒有標籤。所以我們應該提供我們從以前的時間戳獲得的輸出,並繼續程序直到我們到達“_END”指令。
五、注意事項:
(1)這裡我使用兩種詞彙。 一個是由編碼器使用的單詞; 另一個是用於解碼器的標籤。
(2)對於詞彙表,插入三個特殊指令:“_ GO”,“_ END”,“_ PAD”; “_UNK”不被使用,因為所有標籤都是預先定義的。
10. Transformer(“Attention Is All You Need”)
狀態:完成主要部分,能夠在任務中產生序列的相反順序。你可以通過在模型中執行測試功能來檢查它。然而,我還沒有在實際任務中獲得有用的結果。我們在模型中也使用並行的style.layer規範化、殘餘連線和掩碼。
對於每個構建塊,我們在下面的每個檔案中包含測試函式,我們已經成功測試了每個小塊。
帶注意的序列到序列是解決序列生成問題的典型模型,如翻譯、對話系統。大多數時候,它使用RNN完成這些任務。直到最近,人們也應用卷積神經網路進行序列順序問題。但是,Transformer,它僅僅依靠注意機制執行這些任務,是快速的、實現新的最先進的結果。
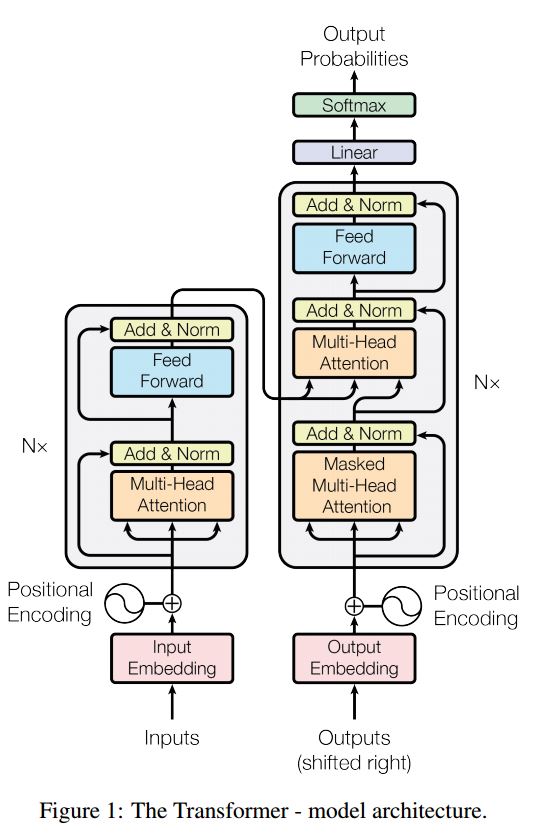
它還有兩個主要部分:編碼器和解碼器。看以下文章:
編碼器:
共6層,每個層都有兩個子層。第一是多向自我注意機制;第二個是位置的全連線前饋網路。對於每個子層使用LayerNorm(x + Sublayer(x)),維度= 512。
解碼器:
1.解碼器由N = 6個相同層的堆疊組成。
2.除了每個編碼器層中的兩個子層之外,解碼器插入第三子層,其在編碼器堆疊的輸出上執行多向注意。
3.與編碼器類似,我們採用圍繞每個子層的殘餘連線,然後進行層歸一化。我們還修改解碼器堆疊中的自我注意子層,以防止位置參與到後續位置。這種掩蔽與輸出嵌入偏移一個位置的事實相結合確保了位置i的預測只能取決於位於小於i的位置的已知輸出。
主要從這個模型中脫穎而出:
1.多向自我注意:使用自我注意,線性變換多次獲取關鍵值的投影,然後開始注意機制
2.一些提高效能的技巧(剩餘連線、位置編碼、前饋、標籤平滑、掩碼以忽略我們想忽略的事情)
使用這個模型處理分類任務:
在這裡我們只使用編碼部分進行任務分類,刪除了resdiual連線,只使用了1層。不需要使用mask。
我們使用多頭注意力機制和postionwise前饋來提取輸入句子的特徵,然後使用線性層來投影它以獲得logits。
有關模型的詳細資訊,請檢視:a2_transformer.py
11.迴圈實體網路(Recurrent Entity Network)
輸入:
1.故事:它是多句話,作為上下文。
2.問題:一個句子,這是一個問題。
3. 回答:一個單一的標籤。
模型結構:
1.輸入編碼:使用一個詞來編碼故事(上下文)和查詢(問題);通過使用位置掩碼將位置考慮在內。
通過使用雙向rnn編碼故事和查詢,效能從0.392提高到0.398,增長了1.5%。
2.動態記憶:
a. 通過使用鍵的“相似性”,輸入故事的值來計算門控。
b. 通過轉換每個鍵,值和輸入來獲取候選隱藏狀態。
c. 組合門和候選隱藏狀態來更新當前的隱藏狀態。
3. 輸出(使用注意機制):
a. 通過計算查詢和隱藏狀態的“相似性”來獲得可能性分佈。
b. 使用可能性分佈獲得隱藏狀態的加權和。
c. 查詢和隱藏狀態的非線性變換獲得預測標籤。
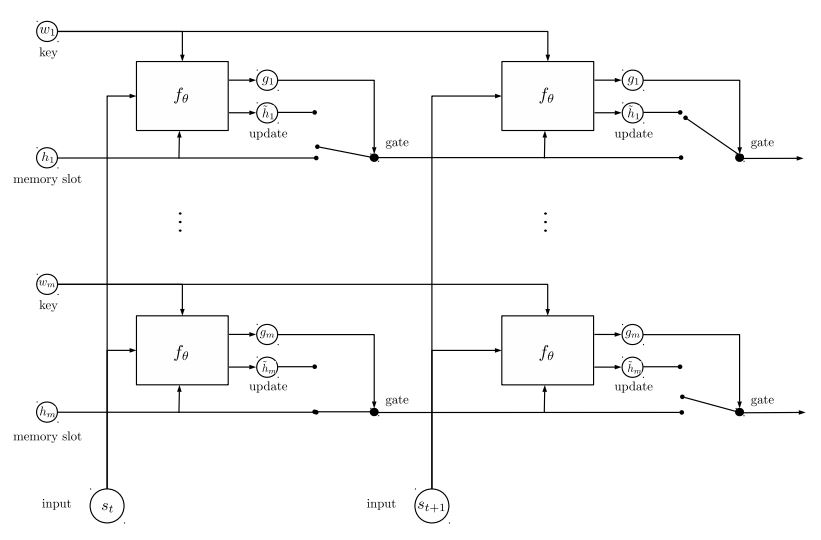
這個模型的關鍵點:
1.使用彼此獨立的鍵和值塊,可以並行執行。
2.上下文和問題一起建模。使用記憶來追蹤世界的狀態,並使用隱性狀態和問題(查詢)的非線性變換進行預測。
3.簡單的型號也可以實現非常好的效能。簡單的編碼作為詞的使用包。
有關模型的詳細資訊,請檢視:a3_entity_network.py
在這個模型下,它包含一個測試函式,它要求這個模型計算故事(上下文)和查詢(問題)的數字,但故事的權重小於查詢。
12.動態記憶網路
模組:Outlook
1.輸入模組:將原始文字編碼為向量表示。
2.問題模組:將問題編碼為向量表示。
3.獨特的記憶模組:通過輸入,通過注意機制選擇哪些部分輸入、將問題和以前的記憶考慮在內====>它將產生“記憶”向量。
4.答案模組:從最終的記憶向量生成答案。
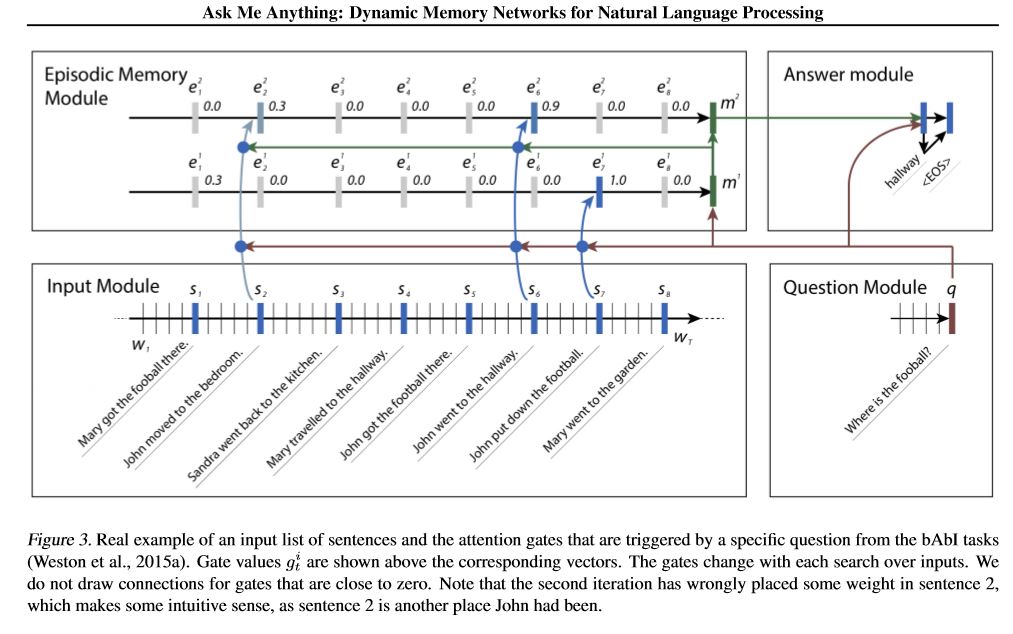
詳情:
1.輸入模組:
一個句子:使用gru獲取隱藏狀態b.list的句子:使用gru獲取每個句子的隱藏狀態。例如 [隱藏狀態1,隱藏狀態2,隱藏狀態...,隱藏狀態n]。
2.問題模組:使用gru獲取隱藏狀態。
3.記憶模組:
相關推薦
基於深度學習的文字分類方法庫(NLP)
注:本文翻譯自GitHub上的一篇介紹,介紹了基於深度學習的文字分類問題。程式碼和部分模型介紹在GitHub上,文末有連結。這個庫的目的是探索用深度學習進行NLP文字分類的方法。它具有文字分類的各種基準模型。它還支援多標籤分類,其中多標籤與句子或文件相關聯。雖然這些模型很多都
基於深度學習的Person Re-ID(綜述)
轉載。 https://blog.csdn.net/linolzhang/article/details/71075756 一. 問題的提出 Person Re-ID 全稱是 Person Re-Identification,又稱為 行
深度學習模型壓縮方法綜述(一)
前言 目前在深度學習領域分類兩個派別,一派為學院派,研究強大、複雜的模型網路和實驗方法,為了追求更高的效能;另一派為工程派,旨在將演算法更穩定、高效的落地在硬體平臺上,效率是其追求的目標。複雜的模型固然具有更好的效能,但是高額的儲存空間、計算資源消耗是使其難以有
深度學習模型壓縮方法綜述(三)
前言在前兩章,我們介紹了一些在已有的深度學習模型的基礎上,直接對其進行壓縮的方法,包括核的稀疏化,和模型的裁剪兩個方面的內容,其中核的稀疏化可能需要一些稀疏計算庫的支援,其加速的效果可能受到頻寬、稀疏度等很多因素的制約;而模型的裁剪方法則比較簡單明瞭,直接在原有的模型上剔除掉
學習筆記之——基於深度學習的分類網路
之前博文介紹了基於深度學習的常用的檢測網路《學習筆記之——基於深度學習的目標檢測演算法》,本博文為常用的CNN分類卷積網路介紹,本博文的主要內容來自於R&C團隊的成員的調研報告以及本人的理解~如有不當之處,還請各位看客賜教哈~好,下面
基於深度學習的推薦演算法實現(以MovieLens 1M資料 為例)
前言 本專案使用文字卷積神經網路,並使用MovieLens資料集完成電影推薦的任務。 推薦系統在日常的網路應用中無處不在,比如網上購物、網上買書、新聞app、社交網路、音樂網站、電影網站等等等等,有人的地方就有推薦。根據個人的喜好,相同喜好人群的習慣等資訊進行個性化
基於深度學習的Person Re-ID(特徵提取)
一. CNN特徵提取 通過上一篇文章的學習,我們已經知道,我們訓練的目的在於尋找一種特徵對映方法,使得對映後的特徵 “類內距離最小,類間距離最大”,這種特徵對映 可以看作是 空間投影,選擇一組基,得到基於這組基的特徵變換,與 PCA 有點像。 這
tensorflow實現基於LSTM的文字分類方法
引言 學習一段時間的tensor flow之後,想找個專案試試手,然後想起了之前在看Theano教程中的一個文字分類的例項,這個星期就用tensorflow實現了一下,感覺和之前使用的theano還是有很大的區別,有必要總結mark一下 模型說明 這個
基於深度學習的影象去噪(論文總結)
2015 深度學習、自編碼器、低照度影象增強 Lore, Kin Gwn, Adedotun Akintayo, and Soumik Sarkar. "LLNet: A Deep Autoencoder Approach to Natural Low-light Image Enhancement." ar
深度學習與人臉識別系列(3)__基於VGGNet的人臉識別系統
作者:wjmishuai 1.引言 本文中介紹的人臉識別系統是基於這兩篇論文: 第一篇論文介紹了海量資料集下的圖片檢索方法。第二篇文章將這種思想應用到人臉識別系統中,實現基於深度學習的人臉識別。 2.關於深度學習的簡要介紹 現階段為止,對
吳恩達《深度學習》第一門課(1)深度學習引言
數據規模 梯度 神經網絡 以及 應該 精確 構建 關於 http 1.1歡迎 主要講了五門課的內容: 第一門課:神經網絡基礎,構建網絡等; 第二門課:神經網絡的訓練技巧; 第三門課:構建機器學習系統的一些策略,下一步該怎麽走(吳恩達老師新書《Machine Learning
吳恩達《深度學習》第一門課(4)深層神經網絡
加網 分享 傳遞 height 經驗 技術分享 image 進行 sig 4.1深層神經網絡 (1)到底是深層還是淺層是一個相對的概念,不必太糾結,以下是一個四層的深度神經網絡: (2)一些符號定義: a[0]=x(輸入層也叫做第0層) L=4:表示網絡的層數 g:表示激
吳恩達《神經網路與深度學習》課程筆記歸納(二)-- 神經網路基礎之邏輯迴歸
上節課我們主要對深度學習(Deep Learning)的概念做了簡要的概述。我們先從房價預測的例子出發,建立了標準的神經網路(Neural Network)模型結構。然後從監督式學習入手,介紹了Standard NN,CNN和RNN三種不同的神經網路模型。接著介紹了兩種不
吳恩達《神經網路與深度學習》課程筆記歸納(三)-- 神經網路基礎之Python與向量化
上節課我們主要介紹了邏輯迴歸,以輸出概率的形式來處理二分類問題。我們介紹了邏輯迴歸的Cost function表示式,並使用梯度下降演算法來計算最小化Cost function時對應的引數w和b。通過計算圖的方式來講述了神經網路的正向傳播和反向傳播兩個過程。本節課我們將來
深度學習caffe(4)——caffe配置(GPU)
電腦:win7 64位,NVIDIA GeForce GTX1080 Ti,visual studio 2013. 深度學習caffe(1)——windows配置caffe(vs2013+python+matlab)(cpu): 系統:window,系統版本是7
深度學習與tensorflow的小日子(一)
本系列專門用來記錄我的深度學習歷程,其中程式碼大部分均出自於李金洪老師的《深度學習之TensorFlow》,希望所有機器學習的道友都能有所知、有所得。 import tensorflow as tf import numpy as np import matpl
詳解深度學習之經典網路架構(十):九大框架彙總
目錄 0、概覽 2、總結 本文是對本人前面講的的一些經典框架的彙總。 純手打,如果有不足之處,可以在評論區裡留言。 0、概覽 1、個人心得 (1)LeNet:元老級框架,結構簡單,卻開創了卷積神經網路的新紀元,具有重要的學
NLP入門(五)用深度學習實現命名實體識別(NER)
前言 在文章:NLP入門(四)命名實體識別(NER)中,筆者介紹了兩個實現命名實體識別的工具——NLTK和Stanford NLP。在本文中,我們將會學習到如何使用深度學習工具來自己一步步地實現NER,只要你堅持看完,就一定會很有收穫的。 OK,話不多說,讓我們進入正題。 幾乎所有的NLP都依賴一
PyTorch 深度學習:60分鐘快速入門(2) ----Autograd: 自動求導
PyTorch 中所有神經網路的核心是autograd包.我們首先簡單介紹一下這個包,然後訓練我們的第一個神經網路. autograd包為張量上的所有操作提供了自動求導.它是一個執行時定義的框架,這意味著反向傳播是根據你的程式碼如何執行來定義,並且每次迭代可以不同. 接下來我們用一些
PyTorch 深度學習:60分鐘快速入門(1) ----什麼是PyTorch
本文翻譯的版本是pytorch 1.0.0官方文件 譯自 pytorch官方文件 作者:Soumith Chintala 教程目標: 深入理解PyTorch張量庫和神經網路 訓練一個小的神經網路來分類圖片 這個教程假設你熟悉numpy的基本操作。