
目標檢測(八)--Faster R-CNN
轉自:www.cnblogs.com/dudumiaomiao/p/6560841.html 略刪改
R-CNN --> FAST-RCNN --> FASTER-RCNN
R-CNN:
(1)輸入測試影象;
(2)利用selective search 演算法在影象中從上到下提取2000個左右的Region Proposal;
(3)將每個Region Proposal縮放(warp)成227*227的大小並輸入到CNN,將CNN的fc7層的輸出作為特徵;
(4)將每個Region Proposal提取的CNN特徵輸入到SVM進行分類;
(5)對於SVM分好類的Region Proposal做邊框迴歸,用Bounding box迴歸值校正原來的建議視窗,生成預測視窗座標.
缺陷:
(1) 訓練分為多個階段,步驟繁瑣:微調網路+訓練SVM+訓練邊框迴歸器;
(2) 訓練耗時,佔用磁碟空間大;5000張影象產生幾百G的特徵檔案;
(3) 速度慢:使用GPU,VGG16模型處理一張影象需要47s;
(4) 測試速度慢:每個候選區域需要執行整個前向CNN計算;
(5) SVM和迴歸是事後操作,在SVM和迴歸過程中CNN特徵沒有被學習更新.
FAST-RCNN:
(1)輸入測試影象;
(2)利用selective search 演算法在影象中從上到下提取2000個左右的建議視窗(Region Proposal);
(3)將整張圖片輸入CNN,進行特徵提取;
(4)把建議視窗對映到CNN的最後一層卷積feature map上;
(5)通過RoI pooling層使每個建議視窗生成固定尺寸的feature map;
(6)利用Softmax Loss(探測分類概率) 和Smooth L1 Loss(探測邊框迴歸)對分類概率和邊框迴歸(Bounding box regression)聯合訓練.
相比R-CNN,主要兩處不同:
(1)最後一層卷積層後加了一個ROI pooling layer;
(2)損失函式使用了多工損失函式(multi-task loss),將邊框迴歸直接加入到CNN網路中訓練
改進:
(1) 測試時速度慢:R-CNN把一張影象分解成大量的建議框,每個建議框拉伸形成的影象都會單獨通過CNN提取特徵.實際上這些建議框之間大量重疊,特徵值之間完全可以共享,造成了運算能力的浪費.
FAST-RCNN將整張影象歸一化後直接送入CNN,在最後的卷積層輸出的feature map上,加入建議框資訊,使得在此之前的CNN運算得以共享.
(2) 訓練時速度慢:R-CNN在訓練時,是在採用SVM分類之前,把通過CNN提取的特徵儲存在硬碟上.這種方法造成了訓練效能低下,因為在硬碟上大量的讀寫資料會造成訓練速度緩慢.
FAST-RCNN在訓練時,只需要將一張影象送入網路,每張影象一次性地提取CNN特徵和建議區域,訓練資料在GPU記憶體裡直接進Loss層,這樣候選區域的前幾層特徵不需要再重複計算且不再需要把大量資料儲存在硬碟上.
(3) 訓練所需空間大:R-CNN中獨立的SVM分類器和迴歸器需要大量特徵作為訓練樣本,需要大量的硬碟空間.FAST-RCNN把類別判斷和位置迴歸統一用深度網路實現,不再需要額外儲存.
FASTER -RCNN:
(1)輸入測試影象;
(2)將整張圖片輸入CNN,進行特徵提取;
(3)用RPN生成建議視窗(proposals),每張圖片生成300個建議視窗;
(4)把建議視窗對映到CNN的最後一層卷積feature map上;
(5)通過RoI pooling層使每個RoI生成固定尺寸的feature map;
(6)利用Softmax Loss(探測分類概率) 和Smooth L1 Loss(探測邊框迴歸)對分類概率和邊框迴歸(Bounding box regression)聯合訓練.
相比FASTER-RCNN,主要兩處不同:
(1)使用RPN(Region Proposal Network)代替原來的Selective Search方法產生建議視窗;
(2)產生建議視窗的CNN和目標檢測的CNN共享
改進:
(1) 如何高效快速產生建議框?
FASTER-RCNN創造性地採用卷積網路自行產生建議框,並且和目標檢測網路共享卷積網路,使得建議框數目從原有的約2000個減少為300個,且建議框的質量也有本質的提高.
概念解釋:
1、常用的Region Proposal有:
-Selective Search
-Edge Boxes
2、softmax-loss
softmax-loss 層和 softmax 層計算大致是相同的. softmax 是一個分類器,計算的是類別的概率(Likelihood),是Logistic Regression 的一種推廣. LogisticRegression 只能用於二分類,
而 softmax 可以用於多分類.
softmax 與 softmax-loss 的區別:
softmax 計算公式:
關於兩者的區別更加具體的介紹,可參考: softmax vs. softmax-loss
使用者可能最終目的就是得到各個類別的概率似然值,這個時候就只需要一個 Softmax 層,而不一定要進行softmax-Loss 操作;或者是使用者有通過其他什麼方式已經得到了某種概率似然值,然後要做最大似然估計,此時則只需要後面的softmax-Loss 而不需要前面的 Softmax操作.因此提供兩個不同的 Layer 結構比只提供一個合在一起的 Softmax-Loss Layer 要靈活許多.不管是 softmax layer 還是 softmax-loss layer,都是沒有引數的,只是層型別不同而已
softmax-loss layer:輸出 loss 值
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip1"
bottom: "label"
top: "loss"
}
softmax layer: 輸出似然值
layers {
bottom: "cls3_fc"
top: "prob"
name: "prob"
type: “Softmax"
}

3、Selective Search
這個策略其實是藉助了層次聚類的思想(可以搜尋瞭解一下"層次聚類演算法"),將層次聚類的思想應用到區域的合併上面;
總體思路:
l 假設現在影象上有n個預分割的區域(Efficient Graph-Based ImageSegmentation),表示為R={R1, R2, ..., Rn},
l 計算每個region與它相鄰region(注意是相鄰的區域)的相似度,這樣會得到一個n*n的相似度矩陣(同一個區域之間和一個區域與不相鄰區域之間的相似度可設為NaN),從矩陣中找出最大相似度值對應的兩個區域,將這兩個區域合二為一,這時候影象上還剩下n-1個區域;
l 重複上面的過程(只需要計算新的區域與它相鄰區域的新相似度,其他的不用重複計算),重複一次,區域的總數目就少1,知道最後所有的區域都合併稱為了同一個區域(即此過程進行了n-1次,區域總數目最後變成了1).演算法的流程圖如下圖所示:


4、SPP-NET
SSP-Net:Spatial Pyramid Pooling in Deep Convolutional Networks for VisualRecognition
先看一下R-CNN為什麼檢測速度這麼慢,一張圖都需要47s!仔細看下R-CNN框架發現,對影象提完Region Proposal(2000個左右)之後將每個Proposal當成一張影象進行後續處理(CNN提特徵+SVM分類),實際上對一張影象進行了2000次提特徵和分類的過程!這2000個Region Proposal不都是影象的一部分嗎,那麼我們完全可以對影象提一次卷積層特徵,然後只需要將Region Proposal在原圖的位置對映到卷積層特徵圖上,這樣對於一張影象我們只需要提一次卷積層特徵,然後將每個Region Proposal的卷積層特徵輸入到全連線層做後續操作.(對於CNN來說,大部分運算都耗在卷積操作上,這樣做可以節省大量時間).
現在的問題是每個Region Proposal的尺度不一樣,直接這樣輸入全連線層肯定是不行的,因為全連線層輸入必須是固定的長度.SPP-NET恰好可以解決這個問題.

由於傳統的CNN限制了輸入必須固定大小(比如AlexNet是224x224),所以在實際使用中往往需要對原圖片進行crop或者warp的操作:
- crop:擷取原圖片的一個固定大小的patch
- warp:將原圖片的ROI縮放到一個固定大小的patch
無論是crop還是warp,都無法保證在不失真的情況下將圖片傳入到CNN當中:
- crop:物體可能會產生截斷,尤其是長寬比大的圖片.
- warp:物體被拉伸,失去“原形”,尤其是長寬比大的圖片
SPP為的就是解決上述的問題,做到的效果為:不管輸入的圖片是什麼尺度,都能夠正確的傳入網路.
具體思路為:CNN的卷積層是可以處理任意尺度的輸入的,只是在全連線層處有限制尺度——換句話說,如果找到一個方法,在全連線層之前將其輸入限制到等長,那麼就解決了這個問題.
具體方案如下圖所示:

如果原圖輸入是224x224,對於conv5出來後的輸出,是13x13x256的,可以理解成有256個這樣的filter,每個filter對應一張13x13的activation map.如果像上圖那樣將activation mappooling成4x4 2x2 1x1三張子圖,做maxpooling後,出來的特徵就是固定長度的(16+4+1)x256那麼多的維度了.如果原圖的輸入不是224x224,出來的特徵依然是(16+4+1)x256;直覺地說,可以理解成將原來固定大小為(3x3)視窗的pool5改成了自適應視窗大小,視窗的大小和activation map成比例,保證了經過pooling後出來的feature的長度是一致的.
5、Bounding box regression
R-CNN中的bounding box迴歸
下面先介紹R-CNN和Fast R-CNN中所用到的邊框迴歸方法.
(1) 什麼是IOU

(2) 為什麼要做Bounding-boxregression?
如上圖所示,綠色的框為飛機的Ground Truth,紅色的框是提取的Region Proposal.那麼即便紅色的框被分類器識別為飛機,但是由於紅色的框定位不準(IoU<0.5),那麼這張圖相當於沒有正確的檢測出飛機.如果我們能對紅色的框進行微調,使得經過微調後的視窗跟Ground Truth更接近,這樣豈不是定位會更準確.確實,Bounding-box regression 就是用來微調這個視窗的.

(3) 迴歸/微調的物件是什麼?

(4) Bounding-box regression(邊框迴歸)
那麼經過何種變換才能從圖11中的視窗P變為視窗呢?比較簡單的思路就是:

注意:只有當Proposal和Ground Truth比較接近時(線性問題),我們才能將其作為訓練樣本訓練我們的線性迴歸模型,否則會導致訓練的迴歸模型不work(當Proposal跟GT離得較遠,就是複雜的非線性問題了,此時用線性迴歸建模顯然不合理).這個也是G-CNN: an Iterative Grid Based ObjectDetector多次迭代實現目標準確定位的關鍵.
線性迴歸就是給定輸入的特徵向量X,學習一組引數W,使得經過線性迴歸後的值跟真實值Y(Ground Truth)非常接近.即.那麼Bounding-box中我們的輸入以及輸出分別是什麼呢?



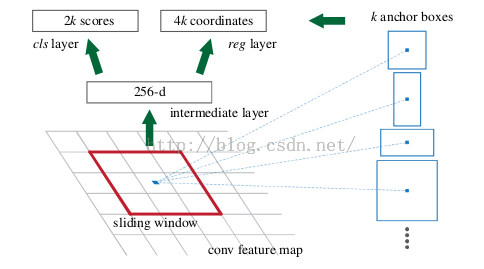
6、Region Proposal Network
RPN的實現方式:在conv5-3的卷積feature map上用一個n*n的滑窗(論文中作者選用了n=3,即3*3的滑窗)生成一個長度為256(對應於ZF網路)或512(對應於VGG網路)維長度的全連線特徵.然後在這個256維或512維的特徵後產生兩個分支的全連線層:
(1)reg-layer,用於預測proposal的中心錨點對應的proposal的座標x,y和寬高w,h;
(2)cls-layer,用於判定該proposal是前景還是背景.sliding window的處理方式保證reg-layer和cls-layer關聯了conv5-3的全部特徵空間.事實上,作者用全連線層實現方式介紹RPN層實現容易幫助我們理解這一過程,但在實現時作者選用了卷積層實現全連線層的功能.
(3)個人理解:全連線層本來就是特殊的卷積層,如果產生256或512維的fc特徵,事實上可以用Num_out=256或512, kernel_size=3*3, stride=1的卷積層實現conv5-3到第一個全連線特徵的對映.然後再用兩個Num_out分別為2*9=18和4*9=36,kernel_size=1*1,stride=1的卷積層實現上一層特徵到兩個分支cls層和reg層的特徵對映.
(4)注意:這裡2*9中的2指cls層的分類結果包括前後背景兩類,4*9的4表示一個Proposal的中心點座標x,y和寬高w,h四個引數.採用卷積的方式實現全連線處理並不會減少引數的數量,但是使得輸入影象的尺寸可以更加靈活.在RPN網路中,我們需要重點理解其中的anchors概念,Loss fucntions計算方式和RPN層訓練資料生成的具體細節.

Anchors:字面上可以理解為錨點,位於之前提到的n*n的sliding window的中心處.對於一個sliding window,我們可以同時預測多個proposal,假定有k個.k個proposal即k個referenceboxes,每一個reference box又可以用一個scale,一個aspect_ratio和sliding window中的錨點唯一確定.所以,我們在後面說一個anchor,你就理解成一個anchor box 或一個reference box.作者在論文中定義k=9,即3種scales和3種aspect_ratio確定出當前slidingwindow位置處對應的9個reference boxes, 4*k個reg-layer的輸出和2*k個cls-layer的score輸出.對於一幅W*H的feature map,對應W*H*k個錨點.所有的錨點都具有尺度不變性.
Loss functions:
在計算Loss值之前,作者設定了anchors的標定方法.正樣本標定規則:
1) 如果Anchor對應的reference box與ground truth的IoU值最大,標記為正樣本;
2) 如果Anchor對應的reference box與ground truth的IoU>0.7,標記為正樣本.事實上,採用第2個規則基本上可以找到足夠的正樣本,但是對於一些極端情況,例如所有的Anchor對應的reference box與groud truth的IoU不大於0.7,可以採用第一種規則生成.
3) 負樣本標定規則:如果Anchor對應的reference box與ground truth的IoU<0.3,標記為負樣本.
4) 剩下的既不是正樣本也不是負樣本,不用於最終訓練.
5) 訓練RPN的Loss是有classificationloss (即softmax loss)和regressionloss (即L1 loss)按一定比重組成的.
計算softmax loss需要的是anchors對應的groundtruth標定結果和預測結果,計算regression loss需要三組資訊:
i. 預測框,即RPN網路預測出的proposal的中心位置座標x,y和寬高w,h;
ii. 錨點reference box:
之前的9個錨點對應9個不同scale和aspect_ratio的reference boxes,每一個reference boxes都有一箇中心點位置座標x_a,y_a和寬高w_a,h_a;
iii. groundtruth:標定的框也對應一箇中心點位置座標x*,y*和寬高w*,h*.因此計算regressionloss和總Loss方式如下:


RPN訓練設定:
(1)在訓練RPN時,一個Mini-batch是由一幅影象中任意選取的256個proposal組成的,其中正負樣本的比例為1:1.
(2)如果正樣本不足128,則多用一些負樣本以滿足有256個Proposal可以用於訓練,反之亦然.
(3)訓練RPN時,與VGG共有的層引數可以直接拷貝經ImageNet訓練得到的模型中的引數;剩下沒有的層引數用標準差=0.01的高斯分佈初始化.
7、RoI Pooling
ROIpooling layer實際上是SPP-NET的一個精簡版,SPP-NET對每個proposal使用了不同大小的金字塔對映,而ROI pooling layer只需要下采樣到一個7x7的特徵圖.對於VGG16網路conv5_3有512個特徵圖,這樣所有region proposal對應了一個7*7*512維度的特徵向量作為全連線層的輸入.
RoIPooling就是實現從原圖區域對映到conv5區域最後pooling到固定大小的功能.
8、smooth L1 Loss
為了處理不可導的懲罰,FasterRCNN提出來的計算距離loss的smooth_L1_Loss.smooth L1近似理解見http://pages.cs.wisc.edu/~gfung/GeneralL1/L1_approx_bounds.pdf
補充一份:http://blog.csdn.net/u011534057/article/details/51247371
reference link:
http://blog.csdn.net/shenxiaolu1984/article/details/51152614
http://blog.csdn.net/luopingfeng/article/details/51245694
http://blog.csdn.net/xyy19920105/article/details/50817725
思想
從RCNN到fast RCNN,再到本文的faster RCNN,目標檢測的四個基本步驟(候選區域生成,特徵提取,分類,位置精修)終於被統一到一個深度網路框架之內。所有計算沒有重複,完全在GPU中完成,大大提高了執行速度。
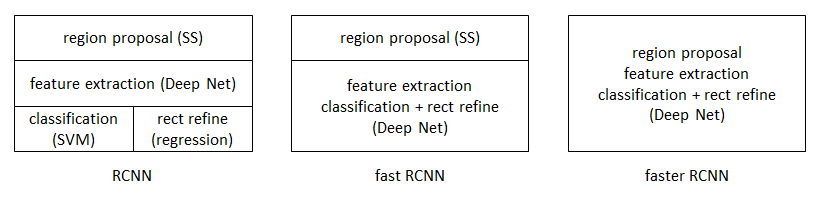
faster RCNN可以簡單地看做“區域生成網路+fast RCNN“的系統,用區域生成網路代替fast RCNN中的Selective Search方法。本篇論文著重解決了這個系統中的三個問題:
1. 如何設計區域生成網路
2. 如何訓練區域生成網路
3. 如何讓區域生成網路和fast RCNN網路共享特徵提取網路
區域生成網路:結構
基本設想是:在提取好的特徵圖上,對所有可能的候選框進行判別。由於後續還有位置精修步驟,所以候選框實際比較稀疏。
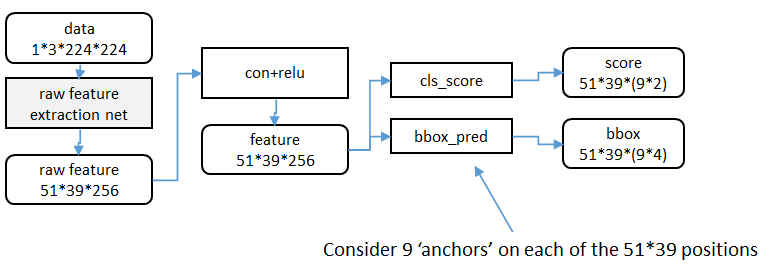
特徵提取
原始特徵提取(上圖灰色方框)包含若干層conv+relu,直接套用ImageNet上常見的分類網路即可。本文試驗了兩種網路:5層的ZF[3],16層的VGG-16[4],具體結構不再贅述。
額外新增一個conv+relu層,輸出51*39*256維特徵(feature)。
Region Proposal Networks的設計和訓練思路
上圖是RPN的網路流程圖,即也是利用了SPP的對映機制,從conv5上進行滑窗來替代從原圖滑窗。
不過,要如何訓練出一個網路來替代selective search相類似的功能呢?
實際上思路很簡單,就是先通過SPP根據一一對應的點從conv5映射回原圖,根據設計不同的固定初始尺度訓練一個網路,就是給它大小不同(但設計固定)的region圖,然後根據與ground truth的覆蓋率給它正負標籤,讓它學習裡面是否有object即可。
這就又變成介紹RCNN之前提出的traditional method,訓練出一個能檢測物體的網路,然後對整張圖片進行滑窗判斷,不過這樣子的話由於無法判斷region的尺度和scale ratio,故需要多次放縮,這樣子測試,估計判斷一張圖片是否有物體就需要很久。(傳統hog+svm->dpm)
如何降低這一部分的複雜度?
要知道我們只需要找出大致的地方,無論是精確定位位置還是尺寸,後面的工作都可以完成,這樣子的話,與其說用小網路,簡單的學習(這樣子估計和蒙差不多了,反正有無物體也就50%的概率),還不如用深的網路,固定尺度變化,固定scale ratio變化,固定取樣方式(反正後面的工作能進行調整,更何況它本身就可以對box的位置進行調整)這樣子來降低任務複雜度呢。
這裡有個很不錯的地方就是在前面可以共享卷積計算結果,這也算是用深度網路的另一個原因吧。而這三個固定,我估計也就是為什麼文章叫這些proposal為anchor的原因了。這個網路的結果就是卷積層的每個點都有有關於k個achor boxes的輸出,包括是不是物體,調整box相應的位置。這相當於給了比較死的初始位置(三個固定),然後來大致判斷是否是物體以及所對應的位置.
這樣子的話RPN所要做的也就完成了,這個網路也就完成了它應該完成的使命,剩下的交給其他部分完成。
候選區域(anchor)
特徵可以看做一個尺度51*39的256通道影象,對於該影象的每一個位置,考慮9個可能的候選視窗:三種面積{1282,2562,5122}× 三種比例{1:1,1:2,2:1} 。
這些候選視窗稱為anchors。
下圖示出51*39個anchor中心,以及9種anchor示例。
關於anchor的問題:
這裡在詳細解釋一下:(1)首先按照尺度和長寬比生成9種anchor,這9個anchor的意思是conv5 feature map 3x3的滑窗對應原圖區域的大小.這9個anchor對於任意輸入的影象都是一樣的,所以只需要計算一次. 既然大小對應關係有了,下一步就是中心點對應關係,接下來(2)對於每張輸入影象,根據影象大小計算conv5 3x3滑窗對應原圖的中心點. 有了中心點對應關係和大小對應關係,對映就顯而易見了.

在整個faster RCNN演算法中,有三種尺度。
原圖尺度:原始輸入的大小。不受任何限制,不影響效能。
歸一化尺度:輸入特徵提取網路的大小,在測試時設定,原始碼中opts.test_scale=600。anchor在這個尺度上設定。這個引數和anchor的相對大小決定了想要檢測的目標範圍。
網路輸入尺度:輸入特徵檢測網路的大小,在訓練時設定,原始碼中為224*224。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Region Proposal Networks
RPN的目的是實現"attention"機制,告訴後續的扮演檢測\識別\分類角色的Fast-RCNN應該注意哪些區域,它從任意尺寸的圖片中得到一系列的帶有 objectness score 的 object proposals。
具體流程是:使用一個小的網路在已經進行通過卷積計算得到的feature map上進行滑動掃描,這個小的網路每次在一個feature map上的一個視窗進行滑動(這個視窗大小為n*n----在這裡,再次看到神經網路中用於縮減網路訓練引數的區域性感知策略receptive field,通常n=228在VGG-16,而作者論文使用n=3),滑動操作後對映到一個低維向量(例如256D或512D,這裡說256或512是低維,Q:n=3,n*n=9,為什麼256是低維呢?那麼解釋一下:低維相對不是指視窗大小,視窗是用來滑動的!256相對的是a convolutional feature map of a size W × H (typically ∼2,400),而2400這個特徵數很大,所以說256是低維.另外需要明白的是:這裡的256維裡的每一個數都是一個Anchor(由2400的特徵數滑動後操作後,再進行壓縮))最後將這個低維向量送入到兩個獨立\平行的全連線層:box迴歸層(a box-regression layer (reg))和box分類層(a box-classification layer (cls))
Translation-Invariant Anchors
在計算機視覺中的一個挑戰就是平移不變性:比如人臉識別任務中,小的人臉(24*24的解析度)和大的人臉(1080*720)如何在同一個訓練好權值的網路中都能正確識別. 傳統有兩種主流的解決方式:
第一:對影象或feature map層進行尺度\寬高的取樣;
第二,對濾波器進行尺度\寬高的取樣(或可以認為是滑動視窗).
但作者的解決該問題的具體實現是:通過卷積核中心(用來生成推薦視窗的Anchor)進行尺度、寬高比的取樣。如上圖右邊,文中使用了3 scales and 3 aspect ratios (1:1,1:2,2:1), 就產生了 k = 9 anchors at each sliding position.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
視窗分類和位置精修
分類層(cls_score)輸出每一個位置上,9個anchor屬於前景和背景的概率;視窗迴歸層(bbox_pred)輸出每一個位置上,9個anchor對應視窗應該平移縮放的引數。
對於每一個位置來說,分類層從256維特徵中輸出屬於前景和背景的概率;視窗迴歸層從256維特徵中輸出4個平移縮放參數。
就區域性來說,這兩層是全連線網路;就全域性來說,由於網路在所有位置(共51*39個)的引數相同,所以實際用尺寸為1×1的卷積網路實現。
需要注意的是:並沒有顯式地提取任何候選視窗,完全使用網路自身完成判斷和修正。
區域生成網路:訓練
樣本
考察訓練集中的每張影象:
a. 對每個標定的真值候選區域,與其重疊比例最大的anchor記為前景樣本
b. 對a)剩餘的anchor,如果其與某個標定重疊比例大於0.7,記為前景樣本;如果其與任意一個標定的重疊比例都小於0.3,記為背景樣本
c. 對a),b)剩餘的anchor,棄去不用。
d. 跨越影象邊界的anchor棄去不用
代價函式
同時最小化兩種代價:
a. 分類誤差
b. 前景樣本的視窗位置偏差
超引數
原始特徵提取網路使用ImageNet的分類樣本初始化,其餘新增層隨機初始化。
每個mini-batch包含從一張影象中提取的256個anchor,前景背景樣本1:1.
前60K迭代,學習率0.001,後20K迭代,學習率0.0001。
momentum設定為0.9,weight decay設定為0.0005。[5]
共享特徵
區域生成網路(RPN)和fast RCNN都需要一個原始特徵提取網路(下圖灰色方框)。這個網路使用ImageNet的分類庫得到初始引數W0,但要如何精調引數,使其同時滿足兩方的需求呢?本文講解了三種方法。
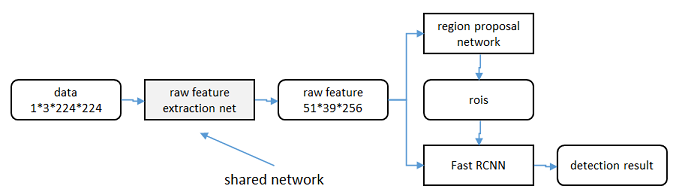
輪流訓練
a. 從W0開始,訓練RPN。用RPN提取訓練集上的候選區域
b. 從W0開始,用候選區域訓練Fast RCNN,引數記為W1
c. 從W1開始,訓練RPN…
具體操作時,僅執行兩次迭代,並在訓練時凍結了部分層。論文中的實驗使用此方法。
如Ross Girshick在ICCV 15年的講座Training R-CNNs of various velocities中所述,採用此方法沒有什麼根本原因,主要是因為”實現問題,以及截稿日期“。
近似聯合訓練
直接在上圖結構上訓練。在backward計算梯度時,把提取的ROI區域當做固定值看待;在backward更新引數時,來自RPN和來自Fast RCNN的增量合併輸入原始特徵提取層。
此方法和前方法效果類似,但能將訓練時間減少20%-25%。公佈的python程式碼中包含此方法。
聯合訓練
直接在上圖結構上訓練。但在backward計算梯度時,要考慮ROI區域的變化的影響。推導超出本文範疇,請參看15年NIP論文[6]。
實驗
除了開篇提到的基本效能外,還有一些值得注意的結論
-
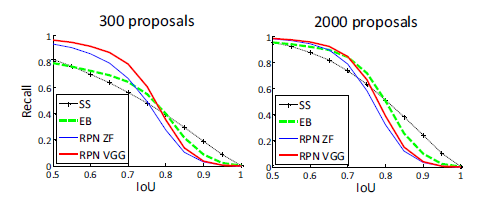
與Selective Search方法(黑)相比,當每張圖生成的候選區域從2000減少到300時,本文RPN方法(紅藍)的召回率下降不大。說明RPN方法的目的性更明確。
-
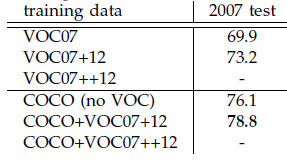
使用更大的Microsoft COCO庫[7]訓練,直接在PASCAL VOC上測試,準確率提升6%。說明faster RCNN遷移性良好,沒有over fitting。
- Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. ↩
- Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015. ↩
- M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional neural networks,” in European Conference on Computer Vision (ECCV), 2014. ↩
- K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in International Conference on Learning Representations (ICLR), 2015. ↩
- learning rate-控制增量和梯度之間的關係;momentum-保持前次迭代的增量;weight decay-每次迭代縮小引數,相當於正則化。 ↩
- Jaderberg et al. “Spatial Transformer Networks”
NIPS 2015 ↩