
Trie 樹(字典樹)
阿新 • • 發佈:2018-12-31
字典樹(Trie)可以儲存一些 字串->值 的對應關係。
基本上,它跟 Java 的 HashMap 功能相同,都是 key-value 對映,只不過 Trie 的 key 只能是字串。
它的優點是:最大限度地減少無謂的字串比較,查詢效率比雜湊表高。
Trie的核心思想是空間換時間。利用字串的公共字首來降低查詢時間的開銷以達到提高效率的目的。
查詢的複雜度是O(len),len為Trie樹的平均高度,也就是字串的平均長度。
建立+查詢在trie中是可以同時執行的,建立trie的複雜度為O(n*len),n為字串的個數。
對於某一個單詞,我們要詢問它的字首是否出現過。這樣hash就不好搞了,而用trie還是很簡單。
Trie樹3個基本性質:
- 根節點不包含字元,除根節點外每一個節點都只包含一個字元。
- 從根節點到某一節點,路徑上經過的字元連線起來,為該節點對應的字串。
- 每個節點的所有子節點包含的字元都不相同。
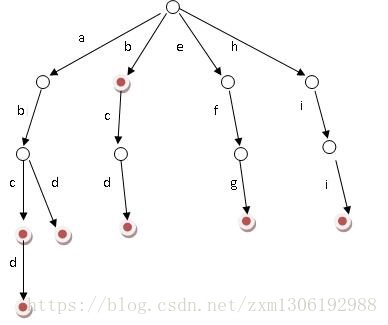
假設有b,abc,abd,bcd,abcd,efg,hii 這6個單詞,我們構建的樹就是如下圖這樣的:
典型例題:
統計難題
Problem Description
Ignatius最近遇到一個難題,老師交給他很多單詞(只有小寫字母組成,不會有重複的單詞出現),現在老師要他統計出以某個字串為字首的單詞數量(單詞本身也是自己的字首).
Input
輸入資料的第一部分是一張單詞表,每行一個單詞,單詞的長度不超過10,它們代表的是老師交給Ignatius統計的單詞,一個空行代表單詞表的結束.第二部分是一連串的提問,每行一個提問,每個提問都是一個字串.
注意:本題只有一組測試資料,處理到檔案結束.
Output
對於每個提問,給出以該字串為字首的單詞的數量.
Sample Input
banana
band
bee
absolute
acm
ba
b
band
abcSample Output
2
3
1
0題解:
import java.util.Scanner;
public class Main {
public static void main(String[] arg) {
Scanner scanner = new Scanner(System.in);
Trie root = new