
從Trie樹(字典樹)談到字尾樹(10.28修訂)
說明:本文基本上是“整理”性質,致謝文末的參考文獻。從Trie樹(字典樹)談到字尾樹
引言
常關注本blog的讀者朋友想必看過此篇文章:這次,咱們來講另外兩種樹:Tire樹與字尾樹。不過,在此之前,先來看兩個問題。
第一個問題: 一個文字檔案,大約有一萬行,每行一個詞,要求統計出其中最頻繁出現的前10個詞,請給出思想,給出時間複雜度分析。
之前在此文:海量資料處理面試題集錦與Bit-map詳解中給出的參考答案:用trie樹統計每個詞出現的次數,時間複雜度是O(n*le)(le表示單詞的平均長度),然後是找出出現最頻繁的前10個詞。也可以用堆來實現(具體的操作可參考
第二個問題:找出給定字串裡的最長迴文。例子:輸入XMADAMYX。則輸出MADAM。這道題的流行解法是用字尾樹(Suffix Tree),但其用途遠不止如此,它能高效解決一大票複雜的字串程式設計問題(當然,它有它的弱點,如演算法實現複雜以及空間開銷大),概括如下:
- 查詢字串S是否包含子串S1。主要思想是:如果S包含S1,那麼S1必定是S的某個字尾的字首;又因為S的字尾樹包含了所有的字尾,所以只需對S的字尾樹使用和Trie相同的查詢方法查詢S1即可(使用字尾樹實現的複雜度同流行的KMP演算法的複雜度相當)。
- 找出字串S的最長重複子串S1。比如abcdabcefda裡abc同da都重複出現,而最長重複子串是abc。
- 找出字串S1同S2的最長公共子串。注意最長公共子串(Longest CommonSubstring)和最長公共子序列(LongestCommon Subsequence, LCS)的區別:子串(Substring)是串的一個連續的部分,子序列(Subsequence)則是從不改變序列的順序,而從序列中去掉任意的元素而獲得的新序列;更簡略地說,前者(子串)的字元的位置必須連續,後者(子序列LCS)則不必。比如字串acdfg同akdfc的最長公共子串為df,而他們的最長公共子序列是adf。LCS可以使用動態規劃法解決。
- Ziv-Lampel無失真壓縮演算法。 LZW演算法的基本原理是利用編碼資料本身存在字串重複特性來實現資料壓縮,所以一個很好的選擇是使用字尾樹的形式來組織儲存字串及其對應壓縮碼值的字典。
- 找出字串S的最長迴文子串S1。例如:XMADAMYX的最長迴文子串是MADAM(此即為上面所說的第二個問題:最長迴文問題,本文第二部分將詳細闡述此問題)。
- 多模式串的模式匹配問題(suffix_array + 二分)。
本文第一部分,咱們就來了解這個Trie樹,然後自然而然過渡到第二部分、字尾樹,接著進入第三部分、詳細闡述字尾樹的構造方法-Ukkonen,最後第四部分、對自動機,KMP演算法,Extend-KMP,字尾樹,字尾陣列,trie樹,trie圖及其應用做個全文概括性總結。權作此番闡述,以備不時之需,在需要的時候便可手到擒來。ok,有任何問題,歡迎不吝指正或賜教。謝謝。
第一部分、Trie樹
1.1、什麼是Trie樹
Trie樹,即字典樹,又稱單詞查詢樹或鍵樹,是一種樹形結構,是一種雜湊樹的變種。典型應用是用於統計和排序大量的字串(但不僅限於字串),所以經常被搜尋引擎系統用於文字詞頻統計。它的優點是:最大限度地減少無謂的字串比較,查詢效率比雜湊表高。
Trie的核心思想是空間換時間。利用字串的公共字首來降低查詢時間的開銷以達到提高效率的目的。
它有3個基本性質:
- 根節點不包含字元,除根節點外每一個節點都只包含一個字元。
- 從根節點到某一節點,路徑上經過的字元連線起來,為該節點對應的字串。
- 每個節點的所有子節點包含的字元都不相同。
1.2、樹的構建
舉個在網上流傳頗廣的例子,如下: 題目:給你100000個長度不超過10的單詞。對於每一個單詞,我們要判斷他出沒出現過,如果出現了,求第一次出現在第幾個位置。分析:這題當然可以用hash來解決,但是本文重點介紹的是trie樹,因為在某些方面它的用途更大。比如說對於某一個單詞,我們要詢問它的字首是否出現過。這樣hash就不好搞了,而用trie還是很簡單。
現在回到例子中,如果我們用最傻的方法,對於每一個單詞,我們都要去查詢它前面的單詞中是否有它。那麼這個演算法的複雜度就是O(n^2)。顯然對於100000的範圍難以接受。現在我們換個思路想。假設我要查詢的單詞是abcd,那麼在他前面的單詞中,以b,c,d,f之類開頭的我顯然不必考慮。而只要找以a開頭的中是否存在abcd就可以了。同樣的,在以a開頭中的單詞中,我們只要考慮以b作為第二個字母的,一次次縮小範圍和提高針對性,這樣一個樹的模型就漸漸清晰了。
好比假設有b,abc,abd,bcd,abcd,efg,hii 這6個單詞,我們構建的樹就是如下圖這樣的:
當時第一次看到這幅圖的時候,便立馬感到此樹之不凡構造了。單單從上幅圖便可窺知一二,好比大海搜人,立馬就能確定東南西北中的到底哪個方位,如此迅速縮小查詢的範圍和提高查詢的針對性,不失為一創舉。
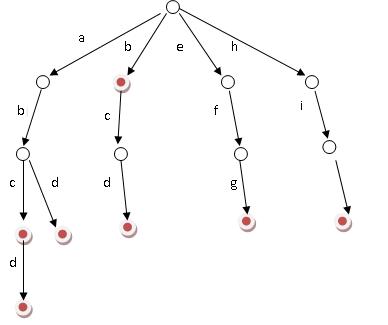
ok,如上圖所示,對於每一個節點,從根遍歷到他的過程就是一個單詞,如果這個節點被標記為紅色,就表示這個單詞存在,否則不存在。
那麼,對於一個單詞,我只要順著他從根走到對應的節點,再看這個節點是否被標記為紅色就可以知道它是否出現過了。把這個節點標記為紅色,就相當於插入了這個單詞。
這樣一來我們查詢和插入可以一起完成(重點體會這個查詢和插入是如何一起完成的,稍後,下文具體解釋),所用時間僅僅為單詞長度,在這一個樣例,便是10。
我們可以看到,trie樹每一層的節點數是26^i級別的。所以為了節省空間。我們用動態連結串列,或者用陣列來模擬動態。空間的花費,不會超過單詞數×單詞長度。
1.3、字首查詢
上文中提到”比如說對於某一個單詞,我們要詢問它的字首是否出現過。這樣hash就不好搞了,而用trie還是很簡單“。下面,咱們來看看這個字首查詢問題: 已知n個由小寫字母構成的平均長度為10的單詞,判斷其中是否存在某個串為另一個串的字首子串。下面對比3種方法:- 最容易想到的:即從字串集中從頭往後搜,看每個字串是否為字串集中某個字串的字首,複雜度為O(n^2)。
- 使用hash:我們用hash存下所有字串的所有的字首子串,建立存有子串hash的複雜度為O(n*len),而查詢的複雜度為O(n)* O(1)= O(n)。
- 使用trie:因為當查詢如字串abc是否為某個字串的字首時,顯然以b,c,d....等不是以a開頭的字串就不用查找了。所以建立trie的複雜度為O(n*len),而建立+查詢在trie中是可以同時執行的,建立的過程也就可以成為查詢的過程,hash就不能實現這個功能。所以總的複雜度為O(n*len),實際查詢的複雜度也只是O(len)。(說白了,就是Trie樹的平均高度h為len,所以Trie樹的查詢複雜度為O(h)=O(len)。好比一棵二叉平衡樹的高度為logN,則其查詢,插入的平均時間複雜度亦為O(logN))。
- 在hash中,例如現在要輸入兩個串911,911456,如果要同時查詢這兩個串,且查詢串的同時若hash中沒有則存入。那麼,這個查詢與建立的過程就是先查詢其中一個串911,沒有,然後存入9、91、911;而後查詢第二個串911456,沒有然後存入9、91、911、9114、91145、911456。因為程式沒有記憶功能,所以並不知道911在輸入資料中出現過,只是照常以例行事,存入9、91、911、9114、911...。也就是說用hash必須先存入所有子串,然後for迴圈查詢。
- 而trie樹中,存入911後,已經記錄911為出現的字串,在存入911456的過程中就能發現而輸出答案;倒過來亦可以,先存入911456,在存入911時,當指標指向最後一個1時,程式會發現這個1已經存在,說明911必定是某個字串的字首。
1.4、查詢
Trie樹是簡單但實用的資料結構,通常用於實現字典查詢。我們做即時響應使用者輸入的AJAX搜尋框時,就是Trie開始。本質上,Trie是一顆儲存多個字串的樹。相鄰節點間的邊代表一個字元,這樣樹的每條分支代表一則子串,而樹的葉節點則代表完整的字串。和普通樹不同的地方是,相同的字串字首共享同一條分支。下面,再舉一個例子。給出一組單詞,inn, int, at, age, adv, ant, 我們可以得到下面的Trie:可以看出:
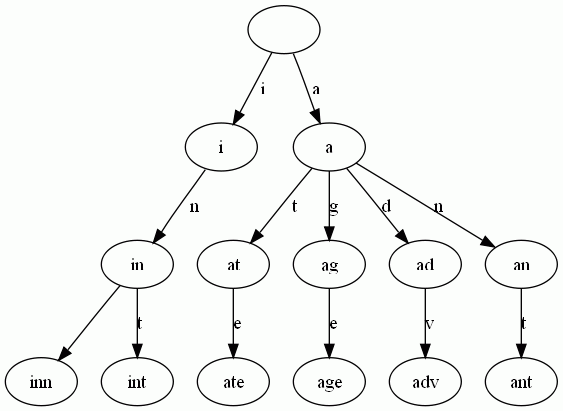
- 每條邊對應一個字母。
- 每個節點對應一項字首。葉節點對應最長字首,即單詞本身。
- 單詞inn與單詞int有共同的字首“in”, 因此他們共享左邊的一條分支,root->i->in。同理,ate, age, adv, 和ant共享字首"a",所以他們共享從根節點到節點"a"的邊。
搭建Trie的基本演算法也很簡單,無非是逐一把每則單詞的每個字母插入Trie。插入前先看字首是否存在。如果存在,就共享,否則建立對應的節點和邊。比如要插入單詞add,就有下面幾步:
- 考察字首"a",發現邊a已經存在。於是順著邊a走到節點a。
- 考察剩下的字串"dd"的字首"d",發現從節點a出發,已經有邊d存在。於是順著邊d走到節點ad
- 考察最後一個字元"d",這下從節點ad出發沒有邊d了,於是建立節點ad的子節點add,並把邊ad->add標記為d。
1.5、Trie樹的應用
除了本文引言處所述的問題能應用Trie樹解決之外,Trie樹還能解決下述問題(節選自此文:海量資料處理面試題集錦與Bit-map詳解):- 3、有一個1G大小的一個檔案,裡面每一行是一個詞,詞的大小不超過16位元組,記憶體限制大小是1M。返回頻數最高的100個詞。
- 9、1000萬字符串,其中有些是重複的,需要把重複的全部去掉,保留沒有重複的字串。請怎麼設計和實現?
- 10、 一個文字檔案,大約有一萬行,每行一個詞,要求統計出其中最頻繁出現的前10個詞,請給出思想,給出時間複雜度分析。
- 13、尋找熱門查詢:搜尋引擎會通過日誌檔案把使用者每次檢索使用的所有檢索串都記錄下來,每個查詢串的長度為1-255位元組。假設目前有一千萬個記錄,這些查詢串的重複讀比較高,雖然總數是1千萬,但是如果去除重複和,不超過3百萬個。一個查詢串的重複度越高,說明查詢它的使用者越多,也就越熱門。請你統計最熱門的10個查詢串,要求使用的記憶體不能超過1G。
(1) 請描述你解決這個問題的思路;
(2) 請給出主要的處理流程,演算法,以及演算法的複雜度。
第二部分、字尾樹
2.1、字尾樹的定義
字尾樹(Suffix tree)是一種資料結構,能快速解決很多關於字串的問題。字尾樹的概念最早由Weiner 於1973年提出,既而由McCreight 在1976年和Ukkonen在1992年和1995年加以改進完善。
字尾,顧名思義,甚至通俗點來說,就是所謂字尾就是後面尾巴的意思。比如說給定一長度為n的字串S=S1S2..Si..Sn,和整數i,1 <= i <= n,子串SiSi+1...Sn便都是字串S的字尾。
以字串S=XMADAMYX為例,它的長度為8,所以S[1..8], S[2..8], ... , S[8..8]都算S的字尾,我們一般還把空字串也算成字尾。這樣,我們一共有如下字尾。對於字尾S[i..n],我們說這項字尾起始於i。
S[1..8], XMADAMYX, 也就是字串本身,起始位置為1
S[2..8], MADAMYX,起始位置為2
S[3..8], ADAMYX,起始位置為3
S[4..8], DAMYX,起始位置為4
S[5..8], AMYX,起始位置為5
S[6..8], MYX,起始位置為6
S[7..8], YX,起始位置為7
S[8..8], X,起始位置為8
空字串,記為$。
而後綴樹,就是包含一則字串所有後綴的壓縮Trie。把上面的字尾加入Trie後,我們得到下面的結構:
仔細觀察上圖,我們可以看到不少值得壓縮的地方。比如藍框標註的分支都是獨苗,沒有必要用單獨的節點同邊表示。如果我們允許任意一條邊裡包含多個字 母,就可以把這種沒有分叉的路徑壓縮到一條邊。另外每條邊已經包含了足夠的字尾資訊,我們就不用再給節點標註字串資訊了。我們只需要在葉節點上標註上每項字尾的起始位置。於是我們得到下圖:
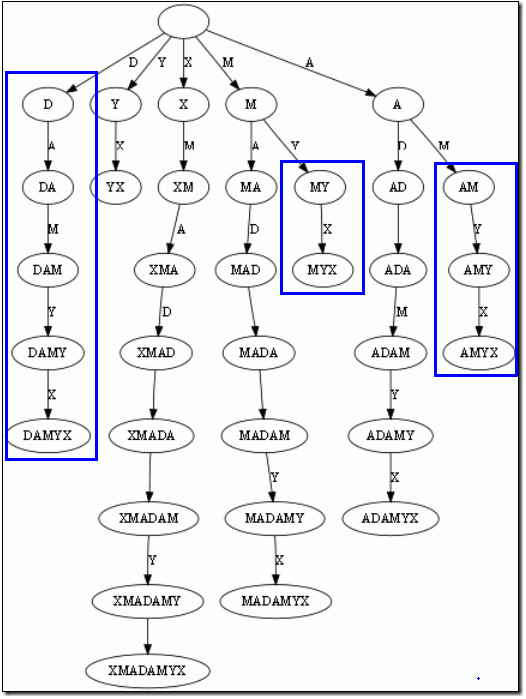
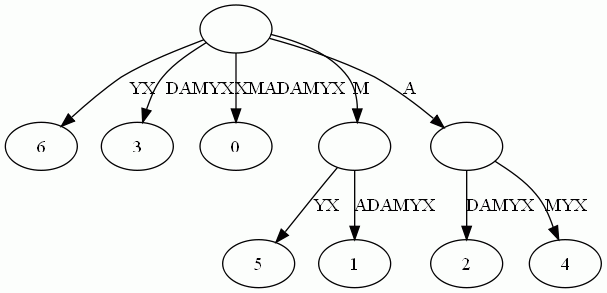
這樣的結構丟失了某些字尾。比如後綴X在上圖中消失了,因為它正好是字串XMADAMYX的字首。為了避免這種情況,我們也規定每項字尾不能是其它字尾的字首。要解決這個問題其實挺簡單,在待處理的子串後加一個空字串就行了。例如我們處理XMADAMYX前,先把XMADAMYX變為 XMADAMYX$,於是就得到suffix tree--字尾樹了,如下圖所示:
2.2、字尾樹與迴文問題的關聯
那字尾樹同最長迴文有什麼關係呢?我們得先知道兩個簡單概念:
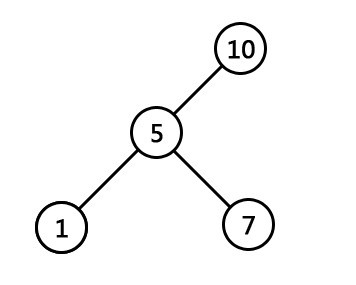
- 最低共有祖先,LCA(Lowest Common Ancestor),也就是任意兩節點(多個也行)最長的共有字首。比如下圖中,節點7同節點1的共同祖先是節點5與節點10,但最低共同祖先是5。 查詢LCA的演算法是O(1)的複雜度,當然,代價是需要對字尾樹做複雜度為O(n)的預處理。
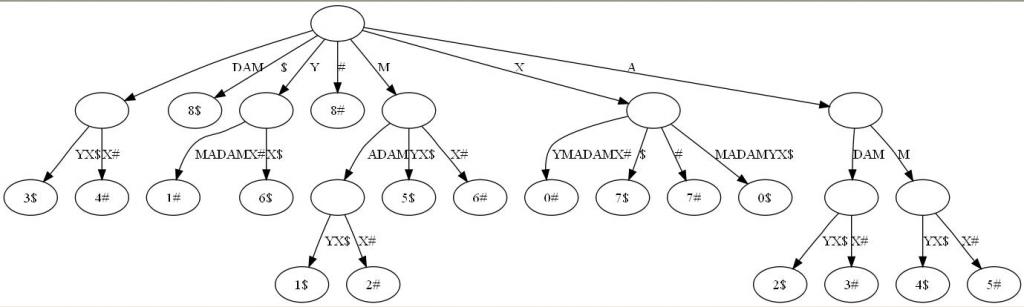
- 廣義字尾樹(Generalized Suffix Tree)。傳統的字尾樹處理一坨單詞的所有後綴。廣義字尾樹儲存任意多個單詞的所有後綴。例如下圖是單詞XMADAMYX與XYMADAMX的廣義字尾 樹。注意我們需要區分不同單詞的字尾,所以葉節點用不同的特殊符號與字尾位置配對。
2.3、最長迴文問題的解決
有了上面的概念,本文引言中提出的查詢最長迴文問題就相對簡單了。咱們來回顧下引言中提出的迴文問題的具體描述:找出給定字串裡的最長迴文。例如輸入XMADAMYX,則輸出MADAM。思維的突破點在於考察迴文的半徑,而不是迴文本身。所謂半徑,就是迴文對摺後的字串。比如迴文MADAM 的半徑為MAD,半徑長度為3,半徑的中心是字母D。顯然,最長迴文必有最長半徑,且兩條半徑相等。還是以MADAM為例,以D為中心往左,我們得到半徑 DAM;以D為中心向右,我們得到半徑DAM。二者肯定相等。因為MADAM已經是單詞XMADAMYX裡的最長迴文,我們可以肯定從D往左數的字串 DAMX與從D往右數的子串DAMYX共享最長字首DAM。而這,正是解決迴文問題的關鍵。現在我們有後綴樹,怎麼把從D向左數的字串DAMX變成字尾 呢?
到這個地步,答案應該明顯:把單詞XMADAMYX翻轉(XMADAMYX=>XYMADAMX,DAMX就變成字尾了)就行了。於是我們把尋找回文的問題轉換成了尋找兩坨字尾的LCA的問題。當然,我們還需要知道 到底查詢那些字尾間的LCA。很簡單,給定字串S,如果最長迴文的中心在i,那從位置i向右數的字尾剛好是S(i),而向左數的字串剛好是翻轉S後得到的字串S‘的字尾S'(n-i+1)。這裡的n是字串S的長度。
可能上面的闡述還不夠直觀,我再細細說明下:
1、首先,還記得本第二部分開頭關於字尾樹的定義麼: “先說說字尾的定義,顧名思義,甚至通俗點來說,就是所謂字尾就是後面尾巴的意思。比如說給定一長度為n的字串S=S1S2..Si..Sn,和整數i,1 <= i <= n,子串SiSi+1...Sn便都是字串S的字尾。”
以字串S=XMADAMYX為例,它的長度為8,所以S[1..8], S[2..8], ... , S[8..8]都算S的字尾,我們一般還把空字串也算成字尾。這樣,我們一共有如下字尾。對於字尾S[i..n],我們說這項字尾起始於i。
S[1..8], XMADAMYX, 也就是字串本身,起始位置為1
S[2..8], MADAMYX,起始位置為2
S[3..8], ADAMYX,起始位置為3
S[4..8], DAMYX,起始位置為4
S[5..8], AMYX,起始位置為5
S[6..8], MYX,起始位置為6
S[7..8], YX,起始位置為7
S[8..8], X,起始位置為8
空字串,記為$。
2、對單詞XMADAMYX而言,迴文中心為D,那麼D向右的字尾DAMYX假設是S(i)(當N=8,i從1開始計數,i=4時,便是S(4..8));而對於翻轉後的單詞XYMADAMX而言,迴文中心D向右對應的字尾為DAMX,也就是S'(N-i+1)((N=8,i=4,便是S‘(5..8)) 。此刻已經可以得出,它們共享最長字首,即LCA(DAMYX,DAMX)=DAM。有了這套直觀解釋,演算法自然呼之欲出:
- 預處理字尾樹,使得查詢LCA的複雜度為O(1)。這步的開銷是O(N),N是單詞S的長度 ;
- 對單詞的每一位置i(也就是從0到N-1),獲取LCA(S(i), S‘(N-i+1)) 以及LCA(S(i+1), S’(n-i+1))。查詢兩次的原因是我們需要考慮奇數迴文和偶數迴文的情況。這步要考察每坨i,所以複雜度是O(N) ;
- 找到最大的LCA,我們也就得到了迴文的中心i以及迴文的半徑長度,自然也就得到了最長迴文。總的複雜度O(n)。
上面大致描述了字尾樹的基本思路。要想寫出實用程式碼,至少還得知道下面的知識:
- 建立字尾樹的O(n)演算法。此演算法有很多種,無論Peter Weiner的73年年度最佳演算法,還是Edward McCreight1976的改進演算法,還是1995年E. Ukkonen大幅簡化的演算法(本文第4部分將重點闡述這種方法),還是Juha Kärkkäinen 和 Peter Sanders2003年進一步簡化的線性演算法,都是O(n)的時間複雜度。至於實際中具體選擇哪一種演算法,可依實際情況而定。
- 實現字尾樹用的資料結構。比如常用的子結點加兄弟節點列表,Directed 優化字尾樹空間的辦法。比如不儲存子串,而儲存讀取子串必需的位置。以及Directed Acyclic Word Graph,常縮寫為黑哥哥們掛在嘴邊的DAWG。
2.4、字尾樹的應用
字尾樹的用途,總結起來大概有如下幾種- 查詢字串o是否在字串S中。
方案:用S構造字尾樹,按在trie中搜索字串的方法搜尋o即可。
原理:若o在S中,則o必然是S的某個字尾的字首。
例如S: leconte,查詢o: con是否在S中,則o(con)必然是S(leconte)的字尾之一conte的字首.有了這個前提,採用trie搜尋的方法就不難理解了。 - 指定字串T在字串S中的重複次數。
方案:用S+’$'構造字尾樹,搜尋T節點下的葉節點數目即為重複次數
原理:如果T在S中重複了兩次,則S應有兩個字尾以T為字首,重複次數就自然統計出來了。 - 字串S中的最長重複子串
方案:原理同2,具體做法就是找到最深的非葉節點。
這個深是指從root所經歷過的字元個數,最深非葉節點所經歷的字串起來就是最長重複子串。
為什麼要非葉節點呢?因為既然是要重複,當然葉節點個數要>=2。 - 兩個字串S1,S2的最長公共部分
方案:將S1#S2$作為字串壓入字尾樹,找到最深的非葉節點,且該節點的葉節點既有#也有$(無#)。
字尾樹的程式碼實現,下期再續。第二部分、字尾樹完。
第三部分、字尾樹的構造方法-Ukkonen
接下來,咱們來了解字尾樹的構造方法-Ukkomen。為了兼顧上文內容,以及加深印象,本部分打算從Trie樹從頭到位重新開始闡述一切。
Ukkonen的構造法O(n), 它比Sartaj Sahni的構造法O(nr), r為字母表大小 在時間上更有優勢. 但我們不能說Sartaj Sahni的演算法慢, 因為r往往會很小, 因此實際效率也接近線性, 兩種構造法在思想上均有可取之處.
3.1、問題的起源
字串匹配問題是程式設計師經常要面對的問題. 字串匹配演算法的改進可以使許多工程受益良多, 比如資料壓縮和DNA排列。你可以把自己想象成一名工作於DNA排列工程的程式設計師. 那些基因研究者們天天忙著分切病毒的基因材料, 製造出一段一段的核苷酸序列. 他們把這些序列發到你的伺服器裡, 指望你在基因資料庫中定位. 要知道, 你的資料庫裡有數百種病毒的資料, 而一個特定的病毒可以有成千上萬的鹼基. 你的程式必須像C/S工程那樣實時向博士們反饋資訊, 這需要一個很好的方案。
很明顯, 在這個問題上採取暴力演算法是極其低效的. 這種方法需要你在基因資料庫裡對比每一個核苷酸, 測試一個較長的基因段基本會把你的C/S系統變成一臺古老的批處理機。
3.2、直覺上的解決方法
由於基因資料庫一般是不變的, 通過預處理來把搜尋簡化或許是個好主意. 一種預處理的方法是建立一棵Trie. 我們通過Trie引申出一種東西叫作字尾Trie. (字尾Trie離字尾樹僅一步之遙.) 首先, Trie是一種n叉樹, n為字母表大小, 每個節點表示從根節點到此節點所經過的所有字元組成的字串. 而後綴Trie的 “字尾” 說明這棵Trie包含了所給欄位的所有後綴 (也許正是一個病毒基因).
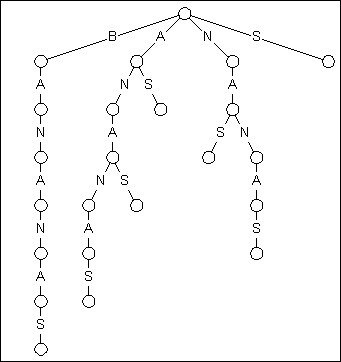
圖1 BANANAS的字尾Trie
上展示了文字BANANAS的字尾Trie. 關於這棵Trie有兩個地方需要注意. 第一, 從根節點開始, BANANAS的每一個字尾都插入到Trie中, 包括BANANAS, ANANAS, NANAS, ANAS, NAS, AS, S. 第二, 鑑於這種結構, 你可以通過從根節點往下匹配的方式搜尋到單詞的任何一個子串.
這裡所說的第二點正是我們認為字尾Trie優秀的原因. 如果你輸入一個長度為N的文字並想在其中搜索一個長度為M的串, 傳統的暴力匹配需要進行N*M次字元對比, 而一些改進過的匹配技術, 比如像Boyer-Moore演算法, 可以在O(N+M)的時間開銷內解決問題, 平均效率更是令人滿意. 然而, 字尾Trie亮出了O(M)的牌子, 徹底鄙視了其他演算法的成績, 字尾Trie對比的次數僅僅相當於被搜尋串的長度!
這確實是可圈可點的威力, 這意味著你能通過僅僅7次對比便在莎士比亞所有作品中找出BANANAS. 但有一點我們可不能忘了, 構造字尾Trie也是需要時間的.
字尾Trie之所以沒有家喻戶曉正是因為構造它需要O(n2)的時間和空間. 平方級的開銷使它在最需要它的領域 --- 長串搜尋 中被拒之門外.
3.3、橫空出世
直到1976年, Edward McCreigh發表了一篇論文, 咱們的字尾樹問世了. 字尾Trie的困境被徹底打破.
字尾樹跟字尾Trie有著一樣的佈局, 但它把只有一個兒子的節點給剔除了. 這個過程被稱為路徑壓縮, 這意味著樹上的某些邊將表示一個序列而不是單獨的字元.
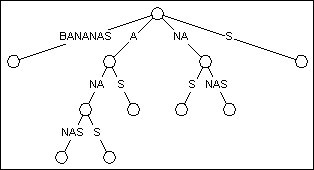
圖2 BANANAS的字尾樹
圖2是由圖1的字尾Trie轉化而來的字尾樹. 你會發現這樹基本還是那個形狀, 只是節點變少了. 在剔除了只有一個兒子的節點之後, 總節點數由23降為11. 經過證明, 在最壞情況下, 字尾樹的節點數也不會超過2N (N為文字的長度). 這使構造字尾樹的線性時空開銷成為可能.
然而, McCreight最初的構造法是有些缺陷的, 原則上它要按逆序構造, 也就是說字元要從末端開始插入. 如此一來, 便不能作為線上演算法, 它變得更加難以應用於實際問題, 如資料壓縮.
20年後, 來自赫爾辛基理工大學的Esko Ukkonen把原演算法作了一些改動, 把它變成了從左往右. 本文接下來的所有描述和程式碼都是基於Esko Ukkonen的成果.
對於所給的文字T, Esko Ukkonen的演算法是由一棵空樹開始, 逐步構造T的每個字首的字尾樹. 比如我們構造BANANAS的字尾樹, 先由B開始, 接著是BA, 然後BAN, … . 不斷更新直到構造出BANANAS的字尾樹.
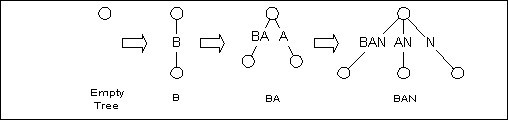
圖3 逐步構造字尾樹
3.4、初窺門徑
加入一個新的字首需要訪問樹中已有的字尾. 我們從最長的一個字尾開始(圖3中的BAN), 一直訪問到最短的字尾(空字尾). 每個字尾會在以下三種節點的其中一種結束.
- 一個葉節點. 這個是常識了, 圖4中標號為1, 2, 4, 5的就是葉節點.
- 一個顯式節點. 圖4中標號為0, 3的是顯式節點, 它表示該節點之後至少有兩條邊.
- 一個隱式節點. 圖4中, 字首BO, BOO, 或者非字首OO, 它們都在某條表示序列的邊上結束, 這些位置就叫作隱式節點. 它表示字尾Trie中存在的由於路徑壓縮而剔除的節點. 在後綴樹的構造過程中, 有時要把一些隱式節點轉化為顯式節點。

圖4 加入BOOK之後的BOOKKEEPER
(也就是BOOK的字尾樹)
如圖4, 在加入BOOK之後, 樹中有5個字尾(包括空字尾). 那麼要構造下一個字首BOOKK的字尾樹的話, 只需要訪問樹中已存在的每一個字尾, 然後在它們的末尾加上K.
前4個字尾BOOK, OOK, OK和K都在葉節點上結束. 由於我們要路徑壓縮, 只需要在通往葉節點的邊上直接加一個字元, 而不需要建立一個新節點.
在所有葉節點更新之後, 我們還需要在空字尾後面加上K. 這時候我們發現已經存在一條從0節點出發的邊的首字元為K, 沒必要畫蛇添足了. 換句話說, 新加入的字尾K可以在0節點和2節點之間的隱式節點中找到. 最終形態見圖5.
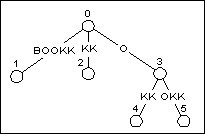
圖5 加入BOOKK之後的BOOKKEEPER
相比圖4, 樹的結構沒有發生變化
如果你是一位敏感的讀者, 可能要發問了, 如果加入K我們什麼都不做的話, 在查詢的時候如何知道它到底是一個字尾呢還是某個字尾的一截? 如果你同時又是一位熟悉字串演算法的朋友, 心裡可能馬上就有答案了 --- 我們只需要在文字後面加個字母表以外的字元, 比如$或者#. 那我們查詢到K$或K#的話就說明這是一個字尾了.
3.5、稍微麻煩一點的事情
從圖4到圖5這個更新過程是相對簡單的, 其中我們執行了兩種更新: 一種是將某條邊延長, 另一種是啥都不做. 但接下來往圖5繼續加入BOOKKE, 我們則會遇到另外兩種更新:
- 建立一個新節點來割開某一隱式節點所處的邊, 並在其後加一條新邊.
- 在顯式節點後加一條新邊.

圖6先分割, 再新增
當我們往圖5的樹中加入BOOKKE的時候, 我們是從已存在的最長字尾BOOKK開始, 一直操作到最短的字尾空字尾. 更新最長的字尾必然是更新葉節點, 之前提到了, 非常簡單. 除此之外, 圖5中結束在葉節點上的字尾還有OOKK, OKK, KK. 圖6的第一棵樹展示了這一類節點的更新.
圖5中首個不是結束在葉節點上的字尾是K. 這裡我們先引入一個定義:
在每次更新字尾樹的過程中, 第一個非葉節點稱為啟用節點. 它有以下性質:
- 所有比啟用節點長的字尾都在葉節點上結束.
- 所有在啟用節點之後加入的字尾都不在葉節點上結束.
字尾K在邊KKE上的隱式節點結束. 在後綴樹中我們要判斷一個節點是不是非葉節點需要看它是否有跟待加入字元相同的兒子, 即本例中的E.
一眼可以看出, KKE中的第一個K只有一個兒子: K. 所以它是非葉節點(這裡同時也是啟用節點), 我們要給他加一個兒子來表示E. 這個過程有兩個步驟:
- 在第一個K和第二個K之間把邊分割開, 於是第一個K(隱式節點)成了一個顯式節點, 如圖6第二棵樹.
- 在剛剛變身而來的顯式節點後加一個新節點表示E, 如圖6第三棵樹. 由此我們又多了一個葉節點。
字尾K更新之後, 別忘了還有空字尾. 空字尾在根節點(節點0)結束, 顯然此時根節點是一個顯式節點. 我們看一下它後面有沒有以E開頭的邊---沒有, 那麼加入一個新的葉節點(如果存在以E開頭的邊, 則不用任何操作). 最終如圖7.
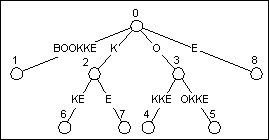
圖7
3.6、歸納, 反思, 優化
藉助字尾樹的特性, 我們可以做出一個相當有效的演算法. 首先一個重要的特性是: 一朝為葉, 終生為葉. 一個葉節點自誕生以後絕不會有子孫. 更重要的是, 每當我們往樹上加入一個新的字首, 每一條通往葉節點的邊都會延長一個字元(新字首的最後一個字元). 這使得處理通往葉節點的邊變得異常簡單, 我們完全可以在建立葉節點的時候就把當前字元到文字末的所有字元一股腦塞進去. 是的, 我們不需要知道後面的字元是啥, 但我們知道它們最終都要被加進去. 因此, 一個葉節點誕生的時候, 也正是它可以被我們遺忘的時候. 你可能會擔心通往葉節點的邊被分割了怎麼辦, 那也不要緊, 分割之後只是起點變了, 尾部該怎麼著還是怎麼著.
如此一來, 我們只需要關心顯式節點和隱式節點上的更新.
還要提到一個節約時間的方法. 當我們遍歷所有後綴時, 如果某個字尾的某個兒子跟待加字元(新字首最後一個字元)相同, 那麼我們當前字首的所有更新就可以停止了. 如果你理解了字尾樹的本質, 你會知道一旦待加字元跟某個字尾的某個兒子相同, 那麼更短的字尾必然也有這個兒子. 我們不妨把首個這樣的節點定義為結束節點. 比結束節點長的字尾必然是葉節點, 這一點很好解釋, 要麼本來就是葉節點, 要麼就是新建立的節點(新建立的必然是葉節點). 這意味著, 每一個字首更新完之後, 當前的結束節點將成為下一輪更新的啟用節點.
好了, 現在我們可以把字尾樹的更新限制在啟用節點和結束節點之間, 效率有了很大的改善. 整理成虛擬碼如下:
Update( 新字首 )
{
當前字尾 = 啟用節點
待加字元 = 新字首最後一個字元
done = false;
while ( !done ) {
if ( 當前字尾在顯式節點結束 )
{
if ( 當前節點後沒有以待加字元開始的邊 )
在當前節點後建立一個新的葉節點
else
done = true;
} else {
if ( 當前隱式節點的下一個字元不是待加字元 )
{
從隱式節點後分割此邊
在分割處建立一個新的葉節點
} else
done = true;
if ( 當前字尾是空字尾 )
done = true;
else
當前字尾 = 下一個更短的字尾
}
啟用節點 = 當前字尾
}
3.7、字尾指標
上面的虛擬碼看上去很完美, 但它掩蓋了一個問題. 注意到第21行, “下一個更短的字尾”, 如果呆板地沿著樹枝去搜索我們想要的字尾, 那這種演算法就不是線性的了. 要解決此問題, 我們得附加一種指標: 字尾指標. 字尾指標存在於每個結束在非葉節點的字尾上, 它指向“下一個更短的字尾”. 即, 如果一個字尾表示文字的第0到第N個字元, 那麼它的字尾指標指向的節點表示文字的第1到第N個字元.
圖8是文字ABABABC的字尾樹. 第一個字尾指標在表示ABAB的節點上. ABAB的字尾指標指向表示BAB的節點. 同樣地, BAB也有它的字尾指標, 指向AB. 如此這般.
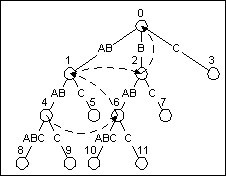
圖8 加上字尾指標(虛線)的ABABABC的字尾樹
介紹一下如何建立字尾指標. 字尾指標的建立是跟字尾樹的更新同步的. 隨著我們從啟用節點移動到結束節點, 我把每個新的葉節點的父親的路徑儲存下來. 每當建立一條新邊, 我同時也在上一個葉節點的父親那兒建立一個字尾指標來指向當前新邊開始的節點. (顯然, 我們不能在第一條新邊上做這樣的操作, 但除此之外都可以這麼做.)
有了字尾指標, 就可以方便地一個字尾跳到另一個字尾. 這個關鍵性的附加品使得演算法的時間上限成功降為O(N)。
第四部分、全文總結
自動機,KMP演算法,Extend-KMP,字尾樹,字尾陣列,trie樹,trie圖及其應用
涉及到字串的問題,無外乎這樣一些演算法和資料結構:自動機,KMP演算法,Extend-KMP,字尾樹,字尾陣列,trie樹,trie圖及其應用。當然這些都是比較高階的資料結構和演算法,而這裡面最常用和最熟悉的大概是kmp,即使如此還是有相當一部分人也不理解kmp,更別說其他的了。當然一般的字串問題中,我們只要用簡單的暴力演算法就可以解決了,然後如果暴力效率太低,就用個hash。當然hash也是一個面試中經常被用到的方法。這樣看來,這樣的一些演算法和資料結構實際上很少會被問到,不過如果使用它們一般可以得到很好的線性複雜度的演算法。
老實說,字串問題的確挺複雜的,出來一個如果用暴力,hash搞不定,就很難再想其他的方法,當然有些可以用動態規劃。下圖主要說明下這些演算法資料結構之間的關係。圖中黃色部分主要寫明瞭這些演算法和資料結構的一些關鍵點。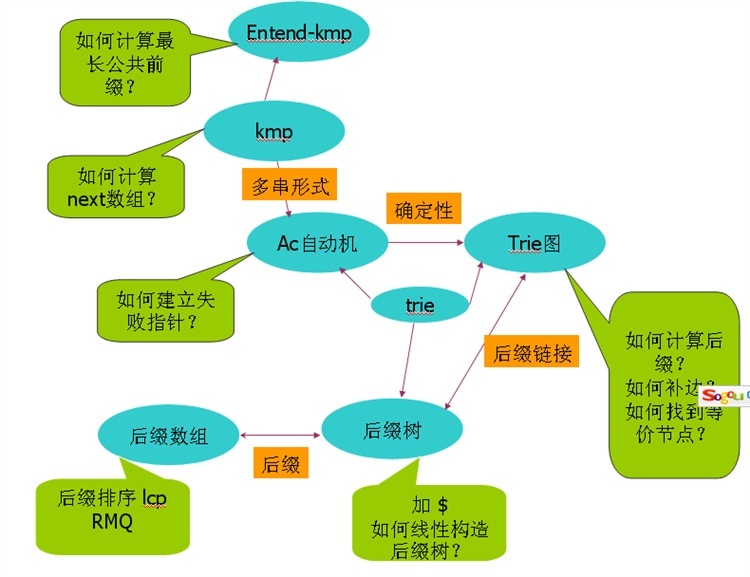
圖中可以看到這樣一些關係:extend-kmp 是kmp的擴充套件;ac自動機是kmp的多串形式;它是一個有限自動機;而trie圖實際上是一個確定性有限自動機;ac自動機,trie圖,字尾樹實際上都是一種trie;字尾陣列和字尾樹都是與字串的字尾集合有關的資料結構;trie圖中的字尾指標和字尾樹中的字尾連結這兩個概念及其一致。
字尾樹的構造可以用Ukkonen演算法線上性時間內完成[,但是不僅構造演算法實現相當複雜,而且字尾樹存在著致命弱點:空間開銷大且對大字母表時間效率不理想。至於字尾陣列下次闡述,這裡簡單介紹下extend-kmp。而在介紹extend-kmp之前,咱們先要回顧下KMP演算法。
kmp
首先這個匹配演算法,主要思想就是要充分利用上一次的匹配結果,找到匹配失敗時,模式串可以向前移動的最大距離。這個最大距離,必須要保證不會錯過可能的匹配位置,因此這個最大距離實際上就是模式串當前匹配位置的next陣列值。也就是max{Aj 是 Pi 的字尾 j < i},pi表示字串A[1...i],Aj表示A[1...j]。模式串的next陣列計算則是一個自匹配的過程。也是利用已有值next[1...i-1]計算next[i]的過程。我們可以看到,如果A[i] = A[next[i-1]+1] 那麼next[i] = next[i-1],否則,就可以將模式串繼續前移了。整個過程是這樣的:
void next_comp(char * str){
int next[N+1];
int k = 0;
next[1] = 0;
//迴圈不變性,每次迴圈的開始,k = next[i-1]
for(int i = 2 ; i <= N ; i++){
//如果當前位置不匹配,或者還推進到字串開始,則繼續推進
while(A[k+1] != A[i] && k != 0){
k = next[k];
}
if(A[k+1] == A[i]) k++;
next[i] = k;
}
}
複雜度分析:從上面的過程可以看出,內部迴圈再不斷的執行k = next[k],而這個值必然是在縮小,也就是是沒執行一次k至少減少1;另一方面k的初值是0,而最多++ N次,而k始終保持非負,很明顯減少的不可能大於增加的那些,所以整個過程的複雜度是O(N)。
上面是next陣列的計算過程,而整個kmp的匹配過程與此類似。
extend-kmp
為什麼叫做擴充套件-kmp呢,首先我們看它計算的內容,它是要求出字串B的字尾與字串A的最長公共字首。extend[i]表示B[i...B_len] 與A的最長公共字首長度,也就是要計算這個陣列。觀察這個陣列可以知道,kmp可以判斷A是否是B的一個子串,並且找到第一個匹配位置?而對於extend[]陣列來說,則可以利用它直接解決匹配問題,只要看extend[]陣列元素是否有一個等於len_A即可。顯然這個陣列儲存了更多更豐富的資訊,即B的每個位置與A的匹配長度。計算這個陣列extend也採用了於kmp類似的過程。首先也是需要計算字串A與自身後綴的最長公共字首長度。我們設為next[]陣列。當然這裡next陣列的含義與kmp裡的有所過程。但它的計算,也是利用了已經計算出來的next[1...i-1]來找到next[i]的大小,整體的思路是一樣的。
具體是這樣的:觀察下圖可以發現
首先在1...i-1,要找到一個k,使得它滿足k+next[k]-1最大,也就是說,讓k加上next[k]長度儘量長。實際上下面的證明過程中就是利用了每次計算後k+next[k]始終只增不減,而它很明顯有個上界,來證明整個計算過程複雜度是線性的。如下圖所示,假設我們已經找到這樣的k,然後看怎麼計算next[i]的值。設len = k+next[k]-1(圖中我們用Ak代表next[k]),分情況討論:

- 如果len < i 也就是說,len的長度還未覆蓋到Ai,這樣我們只要從頭開始比較A[i...n]與A的最長公共字首即可,這種情況下很明顯的,每比較一次,必然就會讓i+next[i]-1增加一.
- 如果len >= i,就是我們在圖中表達的情形,這時我們可以看到i這個位置現在等於i-k+1這個位置的元素,這樣又分兩種情況:
- 如果 L = next[i-k+1] >= len-i+1,也就是說L處在第二條虛線的位置,這樣我們可以看到next[i]的大小,至少是len-i+1,然後我們再從此處開始比較後面的還能否匹配,顯然如果多比較一次,也會讓i+A[i]-1多增加1.
- 如果 L < len-i+1 也就是說L處在第一條虛線位置,我們知道A與Ak在這個位置匹配,但Ak與Ai-k+1在這個位置不匹配,顯然A與與Ai-k+1在這個位置也不會匹配,故next[i]的值就是L。這樣next[i]的值就被計算出來了,從上面的過程中我們可以看到,next[i]要麼可以直接由k這個位置計算出來,要麼需要在逐個比較,但是如果需要比較,則每次比較會讓k+next[k]-1的最大值加1.而整個過程中這個值只增不減,而且它有一個很明顯的上界k+next[k]-1 < 2*len_A,可見比較的次數要被限制到這個數值之內,因此總的複雜度將是O(N)的。
本文參考及推薦閱讀
- 維基百科:Trie樹,字尾樹;
- 兔子的演算法集中營:字尾樹 http://www.cppblog.com/superKiki/archive/2010/10/29/131786.aspx;
- 銀河裡的星星:字串 http://duanple.blog.163.com/blog/static/709717672009825004092/;
- 字尾樹的構造方法-Ukkonen詳解 3xian / 三鮮 in GDUT http://blog.163.com/lazy_p/blog/static/13510721620108139476816/
- E.M. McCreight. A space-economical suffix tree construction algorithm. Journal of the ACM, 23:262-272, 1976.
- E. Ukkonen. On-line construction of suffix trees. Algorithmica, 14(3):249-260, September 1995.
- Mark Nelson. Fast string searching with suffix trees. 1996.
- fsdev的專欄:實用演算法實現-第8篇字尾樹和字尾陣列 [1簡介]
- 深度探索c++物件模型 侯捷譯 P152~168。
相關推薦
從Trie樹(字典樹)談到字尾樹(10.28修訂)
從Trie樹(字典樹)談到字尾樹說明:本文基本上是“整理”性質,致謝文末的參考文獻。 引言 常關注本blog的讀者朋友想必看過此篇文章:這次,咱們來講另外兩種樹:Tire樹與字尾樹。不過,在此之前,先來看兩個問題。 第一個問題: 一個文字檔
從Trie樹(字典樹)談到字尾樹
引言 常關注本blog的讀者朋友想必看過此篇文章:從 B樹、B+樹、B*樹談到R 樹 ,這次,咱們來講另外兩種樹:Tire樹與字尾樹。不過,在此之前,先來看兩個問題。 第一個問題: 一個文字檔案,大約有一萬行,每行一個詞,要求統計出其中最頻繁出現的前10個詞,請
Trie樹(字典樹)(1)
stdio.h public ctu 哈希 pac 索引 cas proc ren Trie樹。又稱字典樹,單詞查找樹或者前綴樹,是一種用於高速檢索的多叉樹結構。 Trie樹與二叉搜索樹不同,鍵不是直接保存在節點中,而是由節點在樹中的位置決定。
trie樹(字典樹)
arc delete png 技術分享 我只 blog 存在 紅色 style 核心思想: 利用字符串的公共前綴來降低查詢時間的開銷以達到提高效率的目的 舉個例子 上圖是由 am as tea too tooth two 構成的字典樹。每個節
208 Implement Trie (Prefix Tree) 字典樹(前綴樹)
tar ref ems clas next 字典樹 ted imp arc 實現一個 Trie (前綴樹),包含 insert, search, 和 startsWith 這三個方法。註意:你可以假設所有的輸入都是小寫字母 a-z。詳見:https://leetcode.c
Trie tree(字典樹)
pri table main radix gcc編譯器 out 字典 name dia Trie tree有時被稱為(digital tree)或(radix tree or prefix tree)。 可能是編譯器問題,我的實現方法用gcc編譯器,debug沒問
hiho 第2周 Trie樹(字典樹)
oid syn one ++ tac col splay str gif 裸字典樹。AC自動機前綴技能 1 #include <set> 2 #include <map> 3 #include <queue> 4
從MySQL Bug#67718淺談B+樹索引的分裂優化(轉)
原文連結:http://hedengcheng.com/?p=525 問題背景 今天,看到Twitter的DBA團隊釋出了其最新的MySQL分支:Changes in Twitter MySQL 5.5.28.t9,此分支最重要的一個改進,就是修復了MySQL 的Bug #67718:In
【模板】Trie樹(字典樹,單詞查詢樹)
int n; // 0為根節點 char a[MAX_N]; // a[0] = 0; int p[MAX_N][26]; void Update(string s) { int now = 0, len = s.size(); for(register int i = 0; i < l
Trie樹(字典樹):應用於統計和排序
轉載這篇關於字典樹的原因是看到騰訊面試相關的題:就是在海量資料中找出某一個數,比如2億QQ號中查找出某一個特定的QQ號。。 有人提到字典樹,我就順便了解下字典樹。 [轉自:http://blog.csdn.net/oncealong/article/details
Trie 樹(字典樹)
字典樹(Trie)可以儲存一些 字串->值 的對應關係。 基本上,它跟 Java 的 HashMap 功能相同,都是 key-value 對映,只不過 Trie 的 key 只能是字串。 它的優點是:最大限度地減少無謂的字串比較,查詢效率比雜湊表高。
B - Trie樹 (trie)(字典樹的拓展)
B - Trie樹 (trie) Time Limit:10000MS Memory Limit:262144KB 64bit IO Format:%lld & %llu
Trie樹(字典樹,字首樹,鍵樹)分析詳解
Trie樹概述 Trie樹,又稱字典樹、字首樹、單詞查詢樹、鍵樹,是一種多叉樹形結構,是一種雜湊樹的變種。Trie這個術語來自於retrieval,發音為/tri:/ “tree”,也有人讀為/traɪ/ “try”。Trie樹典型應用是用於快速檢索(最
Trie樹(字典樹)的C++實現
問題描述: Trie樹 又稱單詞查詢樹,是一種樹形結構,是一種雜湊樹的變種。典型應用是用於統計,排序和儲存大量的字串(但不僅限於字串),所以經常被搜尋引擎系統用於文字詞頻統計。 舉個例子:os,oh,old,char,chat這些關鍵詞構成的trie樹:
Trie樹(字典樹、字首樹)面向物件思想C++實現
Trie樹的功能、思想、實現都寫在程式碼註釋中了 使用: Trie trie = new Trie([TypeCase]); trie. TypeCase= Bit //二進位制 Number // 0-9數字 LowerCase //小寫字母
TRIE(字典樹)模板
/* 給一個不用指標,用鏈式前向星寫的TRIE,當初只為省空間 */ #include<cstring> #include<cstdlib> #include<cmat
Trie(字典樹)的Java實現
簡單實現了一個具有CRUD操作能力的Trie。CRUD操作即插入(Create),讀取(Read),改變(Update)和刪除(Delete)。 刪除是基於當前結點的count實現的。當count為0時代表當前結點應該被完全刪除。 Trie的所有操作均為O(
Trie(字典樹)
none not in insert 節點 pre word fix 根節點 keys 字典樹的作用:它是利用單詞的公共前綴來節約儲存空間,因為單詞的前綴相同就會公用前綴的節點。比如搜索提示就可以根據輸入的前綴來提示可以構成的單詞。 前綴樹特點: ①:單詞前綴相同共
淺談樹形結構的特性和應用(上):多叉樹,紅黑樹,堆,Trie樹,B樹,B+樹...
 上篇文章我們主要介紹了線性資料結構,本篇
(字典樹3道水題)codeforces 665E&282E&514C
eps trie sub amp ret sea 動態 應該 signed 665E 題意: 給一個數列和一個整數k,求這個數列中異或起來大於等於k的子串數量。 分析: 其實只要維護一個維護前綴和就行了,把前綴和加到字典樹裏,然後遞歸search一下,註意需要剪枝,