
海量資料處理——點陣圖法bitmap
比如寫 1234 ,位元組序: 1234/8 = 154; 位序: 1234 &0b111 = 2 ,那麼 1234 放在 bit 的下標 154 位元組處,把該位元組的 2 號位( 0~7)置為 1
位元組位置: int nBytePos =1234/8 = 154;
位位置: int nBitPos = 1234 & 7 = 2;
<span style="color:#330033;">// 把陣列的 154 位元組的 2 位置為 1 unsigned short val = 1<<nBitPos; bit[nBytePos] = bit[nBytePos] |val; // 寫入 1234 得到arrBit[154]=0b00000100 </span>
再比如寫入 1236 ,
位元組位置: int nBytePos =1236/8 = 154;
位位置: int nBitPos = 1236 & 7 = 4
<span style="color:#330033;">// / 把陣列的 154 位元組的 4 位置為 1
val = 1<<nBitPos;
arrBit[nBytePos] = arrBit[nBytePos] |val; // 再寫入 1236 得到arrBit[154]=0b00010100 </span>函式實現:
<span style="color:#330033;">#define SHIFT 5 #define MAXLINE 32 #define MASK 0x1F void setbit(int *bitmap, int i){ bitmap[i >> SHIFT] |= (1 << (i & MASK)); } </span>
2,讀指定位
<span style="color:#330033;">bool getbit(int *bitmap1, int i){
return bitmap1[i >> SHIFT] & (1 << (i & MASK));
} </span>四、點陣圖法的缺點
- 可讀性差
-
點陣圖儲存的元素個數雖然比一般做法多,但是儲存的元素大小受限於儲存空間的大小。點陣圖儲存性質:儲存的元素個數等於元素的最大值。比如, 1K 位元組記憶體,能儲存 8K 個值大小上限為 8K 的元素。(元素值上限為 8K ,這個侷限性很大!)比如,要儲存值為
65535 的數,就必須要 65535/8=8K 位元組的記憶體。要就導致了點陣圖法根本不適合存 unsigned int 型別的數(大約需要 2^32/8=5 億位元組的記憶體)。
- 點陣圖對有符號型別資料的儲存,需要 2 位來表示一個有符號元素。這會讓點陣圖能儲存的元素個數,元素值大小上限減半。 比如 8K 位元組記憶體空間儲存 short 型別資料只能存 8K*4=32K 個,元素值大小範圍為 -32K~32K 。
五、點陣圖法的應用
1、給40億個不重複的unsigned int的整數,沒排過序的,然後再給一個數,如何快速判斷這個數是否在那40億個數當中首先,將這40億個數字儲存到bitmap中,然後對於給出的數,判斷是否在bitmap中即可。
2、使用點陣圖法判斷整形陣列是否存在重複
遍歷陣列,一個一個放入bitmap,並且檢查其是否在bitmap中出現過,如果沒出現放入,否則即為重複的元素。
3、使用點陣圖法進行整形陣列排序
首先遍歷陣列,得到陣列的最大最小值,然後根據這個最大最小值來縮小bitmap的範圍。這裡需要注意對於int的負數,都要轉化為unsigned int來處理,而且取位的時候,數字要減去最小值。
4、在2.5億個整數中找出不重複的整數,注,記憶體不足以容納這2.5億個整數
參 考的一個方法是:採用2-Bitmap(每個數分配2bit,00表示不存在,01表示出現一次,10表示多次,11無意義)。其實,這裡可以使用兩個普 通的Bitmap,即第一個Bitmap儲存的是整數是否出現,如果再次出現,則在第二個Bitmap中設定即可。這樣的話,就可以使用簡單的1- Bitmap了。
求解問題如下:
在本地磁盤裡面有file1和file2兩個檔案,每一個檔案包含500萬條隨機整數(可以重複),最大不超過2147483648也就是一個int表示範圍。要求寫程式將兩個檔案中都含有的整數輸出到一個新檔案中。
要求:1.程式的執行時間不超過5秒鐘。
2.沒有記憶體洩漏。
3.程式碼規範,能要考慮到出錯情況。
4.程式碼具有高度可重用性及可擴充套件性,以後將要在該作業基礎上更改需求。
初一看,覺得很簡單,不就是求兩個檔案的並集嘛,於是很快寫出了下面的程式碼。
<span style="color:#330033;">#include<iostream>
#include<vector>
#include<cstdlib>
#include<algorithm>
#include<fstream>
using namespace std;
void merge(const vector<int> &, const vector<int>&, vector<int> &);
int main(){
vector<int> v1, v2;
vector<int> result;
char buf[512];
FILE *fp;
fp = fopen("file1", "r");
if(fp < 0){
cout<<"Open file failed!\n";
exit(1);
}
while(fgets(buf, 512, fp) != NULL){
v1.push_back(atoi(buf));
}
sort(v1.begin(), v1.end());
fclose(fp);
fp = fopen("file2", "r");
if(fp < 0){
cout<<"Open file2 failed!\n";
exit(1);
}
while(fgets(buf, 512, fp) != NULL){
v2.push_back(atoi(buf));
}
sort(v2.begin(), v2.end());
cout<<v1[v1.size() - 1]<<endl;
cout<<v2[v2.size() - 1]<<endl;
fclose(fp);
merge(v1, v2, result);
cout<<result.size();
ofstream output;
output.open("result");
if(output.fail()){
cerr<<"crete file failed!\n";
exit(1);
}
vector<int>::const_iterator p = result.begin();
for(; p != result.end(); p++){
output<<*p<<endl;
}
output.close();
return 0;
}
void merge(const vector<int>& v1, const vector<int>& v2, vector<int> &result){
vector<int>::const_iterator p1, p2;
p1 = v1.begin();
p2 = v2.begin();
while((p1 != v1.end()) && p2 != v2.end()){
if(*p1 < *p2){
p1++;
}else if(*p1 > *p2){
p2++;
}else{
result.push_back(*p1);
p1++;
p2++;
}
}
} </span>編譯執行。
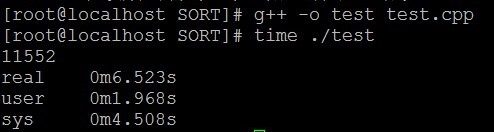
一看,不行,不滿足上面的5秒之內,於是又想了很久,上面不是顯示sys呼叫花了很長時間嘛,於是有寫了一個程式,用快速排序+二分查詢法實現,程式碼如下:
<span style="color:#330033;">#include <iostream>
#include <fstream>
#include <vector>
#include <cstdlib>
#include <cstdio>
#define MAXLINE 32
using namespace std;
void qsort(vector<int>&, int, int);
int partition(vector<int>&, int, int);
bool binarySearch(const vector<int>&, int);
int main(){
vector<int> v1, result;
int temp;
char buf[MAXLINE];
FILE *fd;
fd = fopen("file1", "r");
if(fd == NULL){
cerr<<"Open file1 failed!\n";
exit(1);
}
while(fgets(buf, MAXLINE, fd) != NULL){
v1.push_back(atoi(buf));
}
fclose(fd);
//cout<<v1.size()<<endl;
qsort(v1, 0, v1.size() - 1);
/*vector<int>::const_iterator p = v1.begin();
for(; p != v1.end(); p++){
cout<<*p<<endl;
sleep(1);
}*/
fd = fopen("file2", "r");
if(fd == NULL){
cerr<<"open file2 failed!\n";
exit(1);
}
while(fgets(buf, MAXLINE, fd) != NULL){
temp = atoi(buf);
if(binarySearch(v1, temp)){
result.push_back(temp);
}
}
cout<<result.size();
return 0;
}
void qsort(vector<int> &v, int low, int hight){
if(low < hight){
int mid = partition(v, low, hight);
qsort(v, low, mid - 1);
qsort(v, mid + 1, hight);
}
}
int partition(vector<int> &v, int min, int max){
int temp = v[min];
while(min < max){
while(min < max && v[max] >= temp)
max--;
v[min] = v[max];
while(min < max && v[min] <= temp)
min++;
v[max] = v[min];
}
v[min] = temp;
return min;
}
bool binarySearch(const vector<int> &v, int key){
int low, hight, mid;
low = 0;
hight = v.size() - 1;
while(low <= hight){
mid = (low + hight) /2;
if(v[mid] == key){
return true;
}else if(v[mid] < key){
low = mid + 1;
}else{
hight = mid - 1;
}
}
return false;
} </span>正樂著呢,編譯執行:
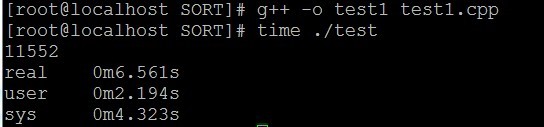
結果發現,user時間是2.194秒,整個時間還要比以前長,顯然這種方法還是不行,原因就是兩個檔案太大了,500萬條,不是一般小,且上面花的時間主要用在排序上面去了,於是就想,能不能不用排序完成?這時有個朋友和我說了一下點陣圖法,靈感一來,自己又去改寫了程式碼:
<span style="color:#330033;">#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <cstring>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
#include <iterator>
#define SHIFT 5
#define MAXLINE 32
#define MASK 0x1F
using namespace std;
void setbit(int *bitmap, int i){
bitmap[i >> SHIFT] |= (1 << (i & MASK));
}
bool getbit(int *bitmap1, int i){
return bitmap1[i >> SHIFT] & (1 << (i & MASK));
}
size_t getFileSize(ifstream &in, size_t &size){
in.seekg(0, ios::end);
size = in.tellg();
in.seekg(0, ios::beg);
return size;
}
char * fillBuf(const char *filename){
size_t size = 0;
ifstream in(filename);
if(in.fail()){
cerr<< "open " << filename << " failed!" << endl;
exit(1);
}
getFileSize(in, size);
char *buf = (char *)malloc(sizeof(char) * size + 1);
if(buf == NULL){
cerr << "malloc buf error!" << endl;
exit(1);
}
in.read(buf, size);
in.close();
buf[size] = '\0';
return buf;
}
void setBitMask(const char *filename, int *bit){
char *buf, *temp;
temp = buf = fillBuf(filename);
char *p = new char[11];
int len = 0;
while(*temp){
if(*temp == '\n'){
p[len] = '\0';
len = 0;
//cout<<p<<endl;
setbit(bit, atoi(p));
}else{
p[len++] = *temp;
}
temp++;
}
delete buf;
}
void compareBit(const char *filename, int *bit, vector<int> &result){
char *buf, *temp;
temp = buf = fillBuf(filename);
char *p = new char[11];
int len = 0;
while(*temp){
if(*temp == '\n'){
p[len] = '\0';
len = 0;
if(getbit(bit, atoi(p))){
result.push_back(atoi(p));
}
}else{
p[len++] = *temp;
}
temp++;
}
delete buf;
}
int main(){
vector<int> result;
unsigned int MAX = (unsigned int)(1 << 31);
unsigned int size = MAX >> 5;
int *bit1;
bit1 = (int *)malloc(sizeof(int) * (size + 1));
if(bit1 == NULL){
cerr<<"Malloc bit1 error!"<<endl;
exit(1);
}
memset(bit1, 0, size + 1);
setBitMask("file1", bit1);
compareBit("file2", bit1, result);
delete bit1;
cout<<result.size();
sort(result.begin(), result.end());
vector< int >::iterator it = unique(result.begin(), result.end());
ofstream of("result");
ostream_iterator<int> output(of, "\n");
copy(result.begin(), it, output);
return 0;
} </span>這是利用點陣圖法實現的程式,編譯執行
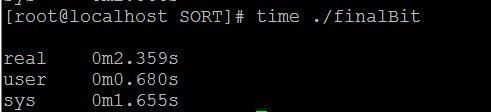
執行時間明顯比前兩個少,但是這個程式是以空間換取時間,程式執行的時候分配了幾百兆的空間。可見在程式設計中,方法很重要。什麼情況選用什麼方法。但是還是覺得前面兩個方法還行,因為需要的空間比較少。