
LDA主題模型小結
簡述LDA
LDA涉及的知識很多,對於作者這樣的菜鳥來說想要弄清楚LDA要費一番功夫,想簡單說清更是不易,寫下此文,也是希望在行文的過程中,把握LDA主要脈絡,理順思路。也希望我理解的方式與順序,能幫到一部分初學的朋友。如果有不對的地方,也歡迎作出指正。
什麼是LDA主題模型
首先我們簡單瞭解一下什麼是LDA以及LDA可以用來做什麼。
LDA(Latent Dirichlet Allocation)是一種文件生成模型。它認為一篇文章是有多個主題的,而每個主題又對應著不同的詞。一篇文章的構造過程,首先是以一定的概率選擇某個主題,然後再在這個主題下以一定的概率選出某一個詞,這樣就生成了這篇文章的第一個詞。不斷重複這個過程,就生成了整片文章。當然這裡假定詞與詞之間是沒順序的。
LDA的使用是上述文件生成的逆過程,它將根據一篇得到的文章,去尋找出這篇文章的主題,以及這些主題對應的詞。
現在來看怎麼用LDA,LDA會給我們返回什麼結果。
LDA是非監督的機器學習模型,並且使用了詞袋模型。一篇文章將會用詞袋模型構造成詞向量。LDA需要我們手動確定要劃分的主題的個數,超引數將會在後面講述,一般超引數對結果無很大影響。

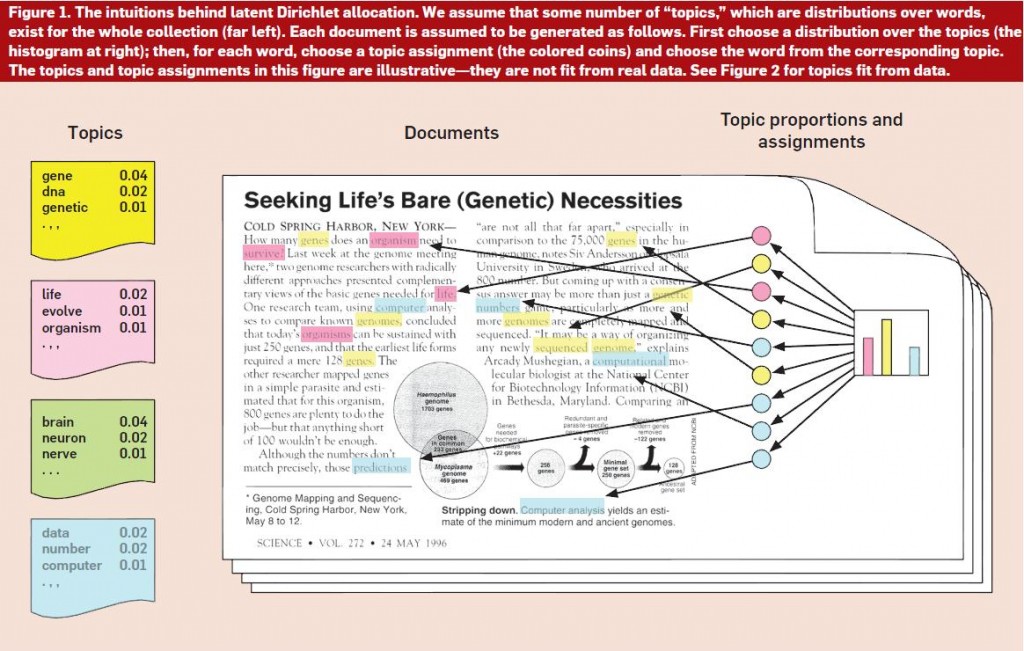

上圖是推斷《Seeking Life’s Bare(Genetic)Necessities》(Figure 1)的例子。使用主題建模演算法(假設有100個主題)推斷《科學》上17000篇文章的潛在主題結構,然後推斷出最能描述圖1中示例文章的主題分佈(圖左)。需要注意的是,儘管主題分佈上有無窮個主題,但事實上只有其中的一小部分的概率不為零。進一步地,文章中詞可被分主題進行組織,可以看到最常見的主題所包含的概率最大的詞。
主題分佈與詞分佈
上面說了,一篇文章的生成過程,每次生成一個詞的時候,首先會以一定的概率選擇一個主題。不同主題的概率是不一樣的,在這裡,假設這些文章-主題符合多項式分佈。同理,主題-詞也假定為多項式分佈。所謂分佈(概率),就是不同情況發生的可能性,它們符合一定的規律。
如果你數學基礎和我一樣薄弱,可能你已經忘了什麼事多項式分佈,這裡我們首先回顧一下兩點分佈和二項分佈,多項式分佈是二項分佈的延伸。二項分佈是兩點分佈的延伸。
兩點分佈
已知隨機變數X的分佈率為
| X | 1 | 0 |
|---|---|---|
| p | p | 1-p |
則有
拋一次硬幣的時候,不是正面就是反面,符合兩點分佈。這裡概率P為引數。
二項分佈
二項分佈,即是重複n次兩點分佈。設隨機變數X服從引數為n,p的二項分佈。其中,n為重複的次數,p為兩點分佈中,事件A發生的概率。設X=k為n次實驗中事件A發生了k次的概率。
可以得到X的分佈率為:
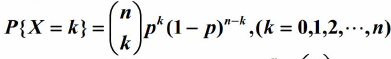
例如,丟5次硬幣,事件A為硬幣正面朝上,則
多項式分佈
多項式分佈(multinomial)是二項分佈在兩點分佈上的延伸。在兩點分佈中,一次實驗只有兩種可能性,p以及 (1-p)。例如拋一枚硬幣,不是正面就是反面。在多項式分佈中,這種可能的情況得到了擴充套件。例如拋一個骰子,一共有6種可能,而不是2種。
設某隨機實驗如果有k個可能情況 A1、A2、…、Ak,分別將他們的出現次數記為隨機變數X1、X2、…、Xk,它們的概率分佈分別是p1,p2,…,pk,那麼在n次取樣的總結果中,A1出現n1次、A2出現n2次、…、Ak出現nk次的這種事件的出現概率P有下面公式:
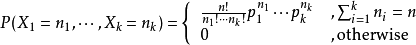
這裡,p1,p2…pk都是引數
那麼現在我們回到LDA身上,前面已經說了主題和詞是符合多項分佈的,我們可以用骰子形象地表達一篇文章的生成的過程。
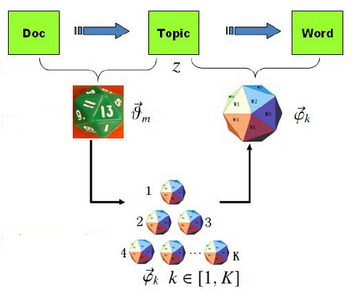

有兩類骰子,一種是文章-主題(doc-topic)骰子,骰子的每面代表一種主題。這裡設一共有K個主題,則K面。骰子的各個面的概率記為
另一種骰子為主題-詞(topic-word)骰子,一共有K個,從1~K編號,分別對應著不同的主題。骰子的一個面代表一個單詞。由於有K個骰子,把不同主題-詞骰子各個面的概率分別記為
那麼一篇文章的生成過程可以表示為:
- 拋擲這個doc-topic骰子,得到主題編號z
- 選擇編號為z的topic-word骰子,得到詞w
- 不斷重複步驟1以及步驟2
引數估計
上面我們已經知道了主題分佈和詞分佈都屬於多項式分佈,只是它們的引數究竟是什麼值,我們還無從知曉。如果我們能估算出它們的引數,我們就能求得這些主題分佈和詞分佈。LDA的主要目的就是求出主題分佈和詞分佈,距離這個目的,我們近在咫尺。
極大似然估計
我們知道,頻率可以用來估計引數。例如對於兩點分佈,拋硬幣。當我們拋的次數足夠多,可以估出p接近1/2,大數定理是有力的保證。頻率學派為引數估計提供了另一種有力的工具——極大似然估計。它的思想可以這樣形象地表達:既然樣本已經出來了,我們有理由相信它們發生的概率很大,於是我們不如就設給定引數的情況下,出現這些樣本的概率是最大的,通過求導計算極值,從而計算出引數。
在這裡,我們的樣本就是我們觀察到的,文章
給定第m篇文章情況下,第i個詞出現的概率正式上式。這裡

我們設詞和詞,文章和文章之間是獨立的。進一步,有了一個單詞的概率,我們就可以求一篇文章的概率:
進一步,有了整個語料庫(訓練集,多篇文章)的概率:
上面說過,極大似然估計就是要讓這個式子達到最大值。接下來還需要把式兩邊取對手,求導,解似然方程,就可以得到引數。實際上,到這裡為止,講述的是其實還只是plsa模型,因此這裡不寫出求解過程。LDA在plsa的求參上作了一些變化,下面將會講到。
形式化地,似然函式可以如下表示:
哪個引數能夠使得這個P最大,則把這個引數作為我們選定的引數。
貝葉斯估計
上一小節中我們知道,plsa模型用頻率學派來估計主題分佈和詞分佈的引數,頻率學派認為引數是一個定值。而貝葉斯學派則認為引數是變化的,也應該符合一定的分佈。LDA在plsa的基礎上引入了貝葉斯學派的方式。
我們先來看看貝葉斯公式
簡述LDA
LDA涉及的知識很多,對於作者這樣的菜鳥來說想要弄清楚LDA要費一番功夫,想簡單說清更是不易,寫下此文,也是希望在行文的過程中,把握LDA主要脈絡,理順思路。也希望我理解的方式與順序,能幫到一部分初學的朋友。如果有不對的地方,也歡迎作出指 大小 href 房子 鏈接 size 目標 文本 訓練樣本 papers 在LDA模型原理篇我們總結了LDA主題模型的原理,這裏我們就從應用的角度來使用scikit-learn來學習LDA主題模型。除了scikit-learn, 還有spark MLlib和gen 算法 ets 思想 dir 骰子 cati em算法 第一個 不同 1. LDA基礎知識
LDA(Latent Dirichlet Allocation)是一種主題模型。LDA一個三層貝葉斯概率模型,包含詞、主題和文檔三層結構。
LDA是一個生成模型,可以用來生成一篇文 .com img png src 技術 nbsp ima blog com
LDA主題模型 矩陣 ota 函數 dom 主題模型 估計 chart news span
本文將從三個方面介紹LDA主題模型——整體概況、數學推導、動手實現。
關於LDA的文章網上已經有很多了,大多都是從經典的《LDA 數學八卦》中引出來的,原創性不太多。
本文將用盡量少的公式,跳過不
https://algobeans.com/2015/06/21/laymans-explanation-of-topic-modeling-with-lda-2/
http://blog.echen.me/2011/08/22/introduction-to-latent-dirich
**
主題模型發展歷程
**首先從Unigram model談起,基於Unigram model加入貝葉斯先驗得到貝葉斯Unigram model,再基於SVD分解得到LSA模型,在LSA模型的基礎上加入概率化的解釋,就得到了PLSA,在PLSA的基礎上加入先驗化的
一、LDA主題模型簡介
LDA(Latent Dirichlet Allocation)中文翻譯為:潛在狄利克雷分佈。LDA主題模型是一種文件生成模型,是一種非監督機器學習技術。它認為一篇文件是有多個主題的,而每個主題又對應著不同的詞。一篇文件的構造過程,首先是以一定的概率
1、知道LDA的特點和應用方向
1.1、特點
知道LDA說的降維代表什麼含義:將一篇分詞後的文章降維為一個主題分佈(即如20個特徵向量主題)。
根據對應的特徵向量中的相關主題概率(20個主題的概率相加為1即為主題分佈)得到對應的文件主題,屬於無監督學習(你沒有
之前學習文字挖掘時已經寫過一篇關於主題模型的部落格《文字建模之Unigram Model,PLSA與LDA》,前幾天小組討論主題模型時,又重新理解了一遍LDA,有了更深刻的認識,特記錄一下。
1、Unigram Model
Unigram model是最簡單的文
將LDA跟多元統計分析結合起來看,那麼LDA中的主題就像詞主成分,其把主成分-樣本之間的關係說清楚了。多元學的時候聚類分為Q型聚類、R型聚類以及主成分分析。R型聚類、主成分分析針對變數,Q型聚類針對樣本
個人部落格地址:http://xurui.club/2018/06/01/lda/
最近在做一個動因分析的專案,自然想到了主題模型LDA。這次先把模型流程說下,原理後面再講。
lda實現有很多開源庫,這裡用的是gensim.
1 文字預處理
大概說下文字 這篇文章來自微軟研究院和哥倫比亞大學的學者共同完成。作者中的Chong Wang以及John Paisley都有長期從事Graphical Models以及Topic Models的研究工作。這篇文章想要做的事情非常直觀,那就是想把在深度學習中非常有效的序列模型——RNN和在文件分析領域非常有效的Topic
這是一篇關於文字主題分析的應用實踐,主要嘗試聚焦幾個問題,什麼是LDA主題模型?如何使用LDA主題模型進行文字?我們將知乎上面的轉基因話題精華帖下面的提問分成六大主題進行實踐。
轉基因“風雲再起”
2017年5月18日璞谷塘悄然開張,這是小崔線上販賣非轉基因食品的網
背景
隱含狄利克雷分配(Latent Dirichlet Allocation)是一種主題模型即從所給文件中挖掘潛在主題。LDA的出現是為了解決類似TFIDF只能從詞頻衡量文件相似度,可能在兩個文件共同出現的單詞很少甚至沒有,但兩個文件是相
原文出處:http://blog.csdn.net/pirage/article/details/9368535
在LDA主題模型之後,需要對模型的好壞進行評估,以此依據,判斷改進的引數或者演算法的建模能力。
Blei先生在論文《Latent Dirichlet Al
LDA主題模型在2002年被David M. Blei、Andrew Y. Ng(是的,就是吳恩達老師)和Michael I. Jordan三位第一次提出,近幾年隨著社會化媒體的興起,文字資料成為越來越重要的分析資料;海量的文字資料對社會科學研究者的分析能力提出
最近總是遇到主題模型LDA(Latent Dirichlet Allocation),網上的部落格寫的天花亂墜而不知所以然,無奈看了最厚的《LDA數學八卦》,觀完略通一二,記錄於此~順便放兩張遇到的圖,挺有意思的,共勉吧:
主題模型
首先我們來看
NLP︱LDA主題模型的應用難題
將LDA跟多元統計分析結合起來看,那麼LDA中的主題就像詞主成分,其把主成分-樣本之間的關係說清楚了。多元學的時候聚類分為Q型聚類、R型聚類以及主成分分析。R型聚類、主成分分析針對變數,Q型聚類針對樣本。
PCA主要將的是主成分-變數之間
本文利用gensim進行LDA主題模型實驗,第一部分是基於前文的wiki語料,第二部分是基於Sogou新聞語料。
1. 基於wiki語料的LDA實驗
上一文得到了wiki純文字已分詞語料 wiki.zh.seg.utf.txt,去停止詞後可進行LDA實驗。
import codecs
from gens 相關推薦
LDA主題模型小結
用scikit-learn學習LDA主題模型
Spark機器學習(8):LDA主題模型算法
LDA主題模型
LDA主題模型三連擊-入門/理論/代碼
LDA 主題模型 通俗簡單講解
LDA主題模型發展歷程(1)
自然語言處理-LDA主題模型
機器學習之LDA主題模型演算法
再看LDA主題模型
NLP︱LDA主題模型的應用難題、使用心得及從多元統計角度剖析
lda主題模型python實現篇
R語言︱LDA主題模型——最優主題數選取(topicmodels)+LDAvis視覺化(lda+LDAvis)
R語言實現LDA主題模型分析知乎話題
LDA主題模型、Word2Vec
LDA主題模型評估方法--Perplexity
用R做中文LDA主題模型視覺化分析
深入淺出講解LDA主題模型(一)
NLP︱LDA主題模型的應用難題
Gensim LDA主題模型實驗